前言
刚学完数据结构,写此文目的如下
- 加深对五大类共八个排序算法思想的理解
- 比较各自的算法效率(主要是时间复杂度)
- 寻找算法思想间的联系与区别
- 用顺序结构、链式结构实现算法
- 用递归、非递归(迭代)实现算法
- 记录下来以便复习巩固
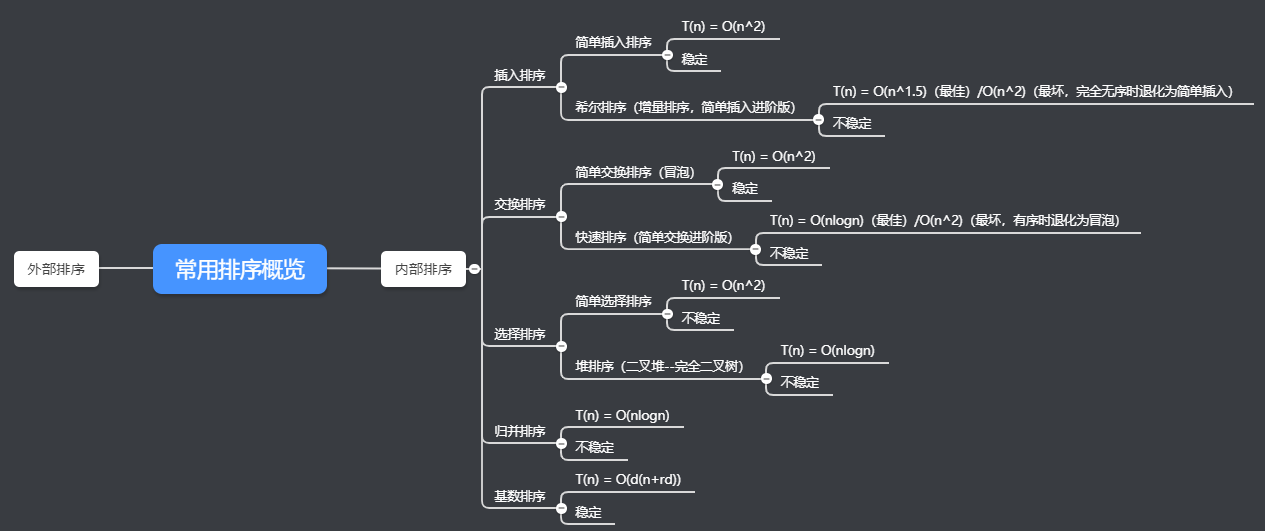
(五类排序算法思维导图)
稳定性: 举个例子,假如我们要对序列A进行排序,排序前A中存在两个元素a1,a2,这两个元素满足同时条件1,a1=a2;条件2,a1在a2之前。若是在排好序的A’中a1依旧在a2之前,那么,我们可以称其满足稳定性。
一句话,稳定性就是遵循先来后到的原则
总结并补充上图:
1,常用排序有五大类,每一类中都是先出现简单,符合人思维的算法,为了提高效率,大家在此前基础上改进算法,进而出现了高效的算法。可见算法的发展是循序渐进,迭代而成,因此,若是按照其发展脉络学习算法,更容易理解算法间的关系
2,简单插入、交换、基数排序满足稳定性,其余皆不稳定
3,希尔排序效率与增量选取有关
4,堆排序有大、小顶堆之分。升序建大顶堆;降序建小顶堆
本文均以升序为例
数据结构
采用顺序结构,为了程序通用性,使用动态数组
typedef struct
{
int *elem;//数组首地址
int length;//数组长度
}SqList;
//初始化动态数组
void InitSqList(SqList &L)//记得加引用,赋初值才有效
{
L.elem = NULL;
L.length = 0;
}
自定义队列及其基本操作
//队列数据结构
typedef struct QNode
{
int data;
struct QNode* next;
}QNode,LNode,*LinkList;
typedef struct
{
QNode* front;
QNode* rear;
}LinkQueue;
//初始化
void InitQueue(LinkQueue &Q)
{
Q.front = Q.rear = (QNode*)malloc(sizeof(QNode));//头尾均指向头指针
Q.front->next = NULL;//尾部赋空
}
//入队:尾部插入
void Enqueue(LinkQueue &Q,int data)
{
QNode* p = (QNode*)malloc(sizeof(QNode));
p->data = data;
p->next = NULL;
Q.rear->next = p;
Q.rear = p;
}
//判空:空->true;非空->false
bool IsEmpty(LinkQueue Q)
{
if(Q.front->next) return false;
else return true;
}
//出队:头部删除;注意删除的节点为尾节点时,重新将尾节点指向头结点
void Dequeue(LinkQueue &Q)
{
if(!IsEmpty(Q))
{
Q.front->next = Q.front->next->next;
if(IsEmpty(Q)) Q.rear = Q.front;//删除尾节点,重新将尾指针指向头
}
}
//获取队头元素
int GetTop(LinkQueue &Q)
{
if(!IsEmpty(Q))
{
return Q.front->next->data;
}
else return -111111;//表示获取失败,即队空
}
前期准备函数
- 由于使用文件交换数据,所以需设计文件存储、读取、重读取函数;随机产生不超过五位的非负整数
- 由于两个元素间交换频繁,因此设计元素交换函数
//创建动态数组
void CreateSqList(SqList &L)//记得加引用
{
L.length = N;//N是宏定义,表示元素个数
L.elem = (int*)malloc(N*sizeof(int));//动态数组必须分配内存!!!!!
fstream inFile("Sort.dat",ios::binary | ios::in);//以只读二进制方式存储文件
inFile.read((char*)L.elem,N*sizeof(int));
inFile.close();//记得关闭
}
//重新加载动态数组,以相同的数据测试新的排序算法
void ReloadSqList(SqList &L)
{
if(L.elem != NULL)
{
L.length = N;
// L.elem = (int*)malloc(N*sizeof(int));//动态数组必须分配内存!!!!!
fstream inFile("Sort.dat",ios::binary | ios::in);//以只读二进制方式存储文件
inFile.read((char*)L.elem,N*sizeof(int));//二进制读取,直接覆盖L之前的元素
inFile.close();//记得关闭
}
}
//把随机数以二进制形式存入文件。每次直接写会覆盖之前的内容
void CreateRandFile()//文件流无法作为参数???或许是因为文件可以在任何处被打开,可看做全局数组
{
SqList L;//中间存储
InitSqList(L);
L.length = N;
L.elem = (int*)malloc(N*sizeof(int));
srand((int)time(0));//随机数种子
for(int i = 0; i < N; i++)
{
L.elem[i] = rand()%100000;//保证产生5位数以内,为桶排序准备
}
fstream outFile("Sort.dat",ios::binary | ios::out);//以只写二进制方式存储文件
outFile.write((char*)L.elem,N*sizeof(int));
outFile.close();//记得关闭读,下次再打开读指针从头开始
free(L.elem);//记得释放
}
//交换
void swap(int &a, int &b)//记得加引用,否则传入的参数在此函数结束后不会改变
{
int t = a;
a = b;
b = t;
}
//仅仅为测试从文件读取数据是否成功,排序是否成功
void TraverseSqList(SqList L)
{
for(int i = 0; i < L.length; i++)
{
cout<<L.elem[i]<<" ";
}
}
插入排序
简单插入排序
算法思想
一个元素插入一个有序序列L,新序列L’依旧有序
算法描述
1,初始状态:第一个元素默认已有序,加入有序序列L
2,将距离序列L最近的元素插入L,得到新的有序序列L
3,重复步骤2,直到所有元素均在L中
算法实现(C++)
//=========================简单插入排序============================
//简单插入排序,从第二个开始
void InsertSort(SqList L)
{
for(int i = 1; i < L.length; i++)//从第二个开始
{
for(int j = i; j > 0; j--)
{
if(L.elem[j] < L.elem[j-1])
{
swap(L.elem[j],L.elem[j-1]);
}
else break;//提高效率
}
}
}
希尔排序
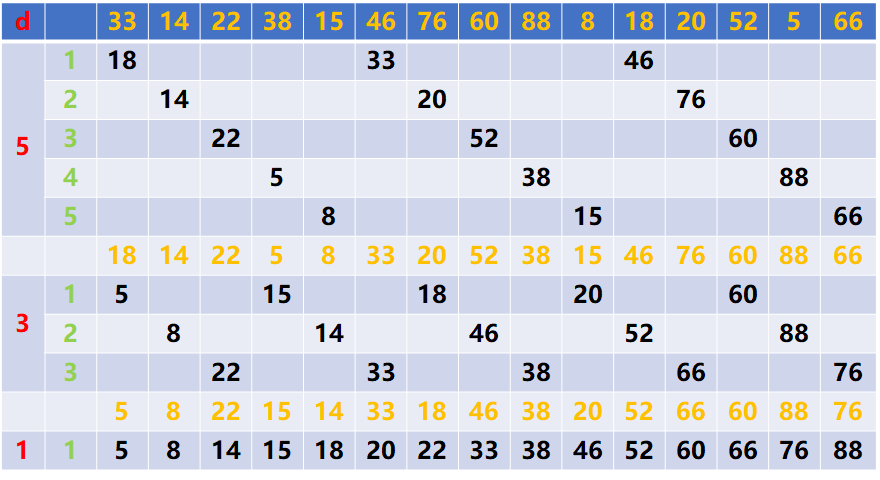
算法思想
- 1, 确定一个起点a1,选取与其间距为id的元素构成一个子序列,L1={a1,a1+d,…a1+id},对其进行简单插入排序,L1为有序
在确定新的起点a2,选取与其间距为id的元素构成一个子序列,L2={a2,a2+d,…a2+id},对其进行简单插入排序,L2为有序
以次类推,最终得到d个子序列,且每个子序列均有序
因此,在L中间隔为d的元素已排好序
(在同一个子序列中的元素下标必构成公差为d的等差数列) - 2, 减小d,重复步骤1,直至d=1
实例讲解
第一行为原始序列,d为增量
代码实现(C++)
tips:
- 1,每个序列的第一个默认是排好序的
- 2,一个序列分成dk个子序列时,
- 思路一:传统是将i%dk相同的ai抽出来成为新序列,进而对该新序列使用简单插入排序,再处理下一个序列
- 思路二:i%dk = {0,1,…dk-1} 在不同的子序列间来回处理,处理完余数为0,立刻处理余数为1,2,…dk-1。此思路为该程序的写法
- 3,判断条件中一发现当前数更大,立刻break,否则时间复杂度可能比简单插入还高
- 4,这是测试快速排序时发现的问题:数组下标越界,j>=dk,否则j-dk会溢出。很严重的问题是它溢出了照样输出,不终止,运行到快速排序就卡着了,误导我以为是快排出现问题。
- 5,通过打印输出找问题时又发现了一个严重问题:即使不通过应用L,数组L.elem依旧被改变,原因在于虽然L作为形参传入,但L.elem是指针,代表着地址,在函数中对其操作,相当于直接在其对应地址改动
- 6,要有自信,迅速定位问题位置,明白当前问题可能是由之前问题导致,连锁反应,可见封装的优越性。尽量不用递归,一是难调,二是耗空间
//=========================希尔排序============================
//希尔插入,按照一定的增量dk,进行插入排序
void ShellInsert(SqList L, int dk)
{
//=============思路一实现===========================
for(int k = 0; k < dk; k++)
{
for(int i = k + dk; i < L.length; i += dk)//i%dk = {0,1,...dk} 间来回转换
{
// for(int j = i; j > 0; j -= dk)错误示例,会溢出
for(int j = i; j >= dk; j -= dk)
{
if(L.elem[j] < L.elem[j-dk])
{
swap(L.elem[j], L.elem[j-dk]);
}
else break;//不跳出时间复杂度比简单插入还高
}
}
}
/*
//==================思路二实现=================
for(int i = 0 + dk; i < L.length; i ++)//i%dk = {0,1,...dk} 间来回转换
{
for(int j = i; j >= dk; j -= dk)//方案一:控制j的范围,j>=dk,否则会溢出
{
// if(j - dk >= 0)//方案二:注意判断是否存在,否则j<dk时必溢出!!!!!!!!!
// {
if(L.elem[j] < L.elem[j-dk])//两种解决方案
{
swap(L.elem[j], L.elem[j-dk]);
}
// }
else break;//不跳出时间复杂度比简单插入还高
}
}*/
}
void ShellSort(SqList L)
{
int d[3] = {5,3,1};//增量数列
for(int i = 0; i < 3; i++)
{
ShellInsert(L,d[i]);
}
// TraverseSqList(L);
}
交换排序
简单交换(冒泡)排序
算法思想
两两比较,较大者往后走/较小者往前走
实现代码(C++)
//通过两两交换,求得最小值,从前往后填入
void BubbleSort(SqList L)
{
for(int i = 0; i < L.length - 1; i++)
{
for(int j = i+1; j < L.length; j++)
{
if(L.elem[i] > L.elem[j])
{
swap(L.elem[i],L.elem[j]);
}
}
}
// TraverseSqList(L);
}
快速排序
算法思想
分割(核心):选取一个分割元素p,令p左边元素均小于等于p,p右边元素均大于等于p,因此,p的位置唯一确定。
因此,只需进行n次分割就可将长度为n的序列L排成有序序列
代码实现(C++)
递归版
//选择一个值pivot作为轴对数列进行分割,左小右大,分割完成,pivot位置确定
//快速排序是对不断对序列进行分割,每分一次,确定一个值的位置
int Partition(SqList L,int low,int high)
{
int i,j;//好习惯:尽量不改变参数
i = low;//头
j = high;//尾
int t = L.elem[low];//保存第一个,腾出空位
while(i < j)
{
while(i < j && t <= L.elem[j]) j--;//从j向前找到第一个比t小的值
L.elem[i] = L.elem[j];//填入空中 ,此时i的位置腾出
while(i < j && t >= L.elem[i]) i++;//从i向后找到第一个比t大的值
L.elem[j] = L.elem[i];//填入空中 ,此时j的位置腾出
}//跳出循环,i=j,且还必有一个空
L.elem[i] = t;//将开始的轴值填入最后一个空,该值位置确定,其左边均比它小,右边均比他大。
return i;//返回中轴的位置
}
//递归实现分割
void QSort(SqList L,int low,int high)
{
if(low < high)
{
int pivot = Partition(L,low,high);
QSort(L,low,pivot-1);
QSort(L,pivot+1,high);
}
}
//为了形式统一,接口一致,才写了这个函数
void QuickSort(SqList L)
{
QSort(L,0,L.length - 1);
}
选择排序
算法思想
每趟选取一个最小值,往前放/每天选一个最大值,往后放
实现代码(C++)
//每趟选出一个最小值,从前往后放入第一个非有序位置
void SelectSort(SqList L)
{
for(int i = 0; i < L.length; i++)
{
int k = i;
for(int j = i + 1; j < L.length; j++)
{
if(L.elem[k] > L.elem[j]) k = j;//记录最小值下标
}
if(k != i)//如果ai不是最小值 ,交换ak,ai,使ai成为最小值
{
swap(L.elem[k],L.elem[i]);
}
}
}
堆排序(大顶堆)
大顶堆是完全二叉树,且任一子树根均大于左右孩子
算法思想
1,筛选(核心):堆排序关键是如何筛选出最大元素,可分为两种情况
- 1,完全二叉树除了根,左右子树均已为大顶堆
- 2,除了情况1的情况
A,第一种情况(好办)
- 1,令根a与其左右孩子中较大者a’比较,若a>=a’,无需再比;若a<a’,交换这两个节点
- 2,重复1,直至a为叶子
B,第二种情况(转化分解)
可以将情况二转化为多个情况一,从而解决问题。
倒过来反复使用解决方案A
- 1,完全二叉树的叶子左右子树均为大顶堆,所以可用A筛选
- 2,从最后向前一步步筛选,所以每个即将要筛选的节点的左右子树均已为大顶堆,所以均可使用A筛选
2,建大顶堆
使用反复筛选建立大顶堆,来一个元素,筛选一次。
3,排序
建好大顶堆后,将根元素与最后一个元素交换,同时完全二叉树去除最后一个元素,再利用筛选,得到元素少一个的新大顶堆,重复直至仅有一个元素即可。
实现代码(C++)
//大顶堆--》升序;小顶堆-》降序
//筛选函数,使用前提:根的左右子树都是堆,仅根破坏了大顶堆的定义
void HeapAdjust(SqList L,int low,int high)
{
int i,j;
i = low;
while(2*i <= high)//堆是完全二叉树:左子堆存在
{
j = 2*i;//初值 ,每次需更新
if(2*i+1 <= high && L.elem[2*i] < L.elem[2*i+1]) j = 2*i+1;//若右子堆也存在,选择左右大者
if(L.elem[i] < L.elem[j]) swap(L.elem[i],L.elem[j]);//若ai<aj,交换
else break;//否则立刻跳出,提升效率
i = j;//更新i
}
// TraverseSqList(L);
}
//乱序数列通过从最后一个开始向前反复筛选可变为堆
//0号单元不用
void HSort(SqList L,int low,int high)
{
for(int i = high; i >= 1; i--)//整理成大顶堆
{
HeapAdjust(L,i,high);
}
// cout<<"12:";TraverseSqList(L);
int i,j;
i = low;
j = high;
//for(int k = 1; k < L.length; k++)//次数必须为n-1次,多一次少一次都不行 ???
while(true)
{//因为0号单元有元素,但是堆不用,0*x=0。所以排序次数多了会把0号元素卷入排序,导致错误
//方案一:严格控制次数:n-1次
//方案二:利用j=0跳出循环
if(j == 0)break;
swap(L.elem[i],L.elem[j]);
j--;
HeapAdjust(L,i,j);
}
}
//与快排相同,该函数仅是为了接口统一
void HeapSort(SqList L)
{
HSort(L,1,L.length-1);
}
归并排序
两个有序序列合并成一个有序序列
代码实现(C++)
- 递归与非递归合并算法一致
- 递归简洁,但效率一般不如非递归高,且不易调试
合并两条有序序列
//=========================归并============================
void Merge(SqList &L1,int low,int m,int high)
{
int i,j,k=low;//错误示范:k=0。!!每次调用归并起点并不都是0
i = low;
j = m+1;
SqList L2;
L2.length = L1.length;
L2.elem = (int*)malloc(N*sizeof(int));
while(i <= m && j <= high)//两条序列均未走完
{
if(L1.elem[i] < L1.elem[j]) L2.elem[k++] = L1.elem[i++];
else L2.elem[k++] = L1.elem[j++];
}
//若是有一序列还未走完,直接将剩余部分全部赋给新序列
while(i <= m) L2.elem[k++] = L1.elem[i++];
while(j <= high) L2.elem[k++] = L1.elem[j++];
for(int t = low; t <= high; t++)//low->high 才需赋值
{
L1.elem[t] = L2.elem[t];
}
free(L2.elem);
}
递归形式
//递归形式
void MSort(SqList L,int low,int high)
{
if(low >= high ) return;
int m = (low + high)/2;
MSort(L,low,m);
MSort(L,m+1,high);
Merge(L,low,m,high);
}
//递归形式
void MergeSort_Recursion(SqList L)
{
MSort(L,0,L.length-1);
}
非递归:递推方程
//非递归:递推方程
void MergeSort_Iteration(SqList L)
{
int low,m,high;
for(int dk = 1; dk <= (L.length+1)/2; dk *= 2)//每个子序列个数,1~2的n次方
{
for(low = 0; low < L.length - 2*dk + 1; low = low+2*dk)//控制次数,high>low,避免溢出,最后若有剩余一部分等最后再处理
{
m = dk + low - 1;
high = 2*dk + low - 1;
Merge(L,low,m,high);
}
}
if(high < L.length - 1)//处理之前剩余的部分,在来一次归并
{
Merge(L,0,high,L.length-1);
}
}
基数排序
算法思想
以小于100000的自然数(五位数)举例
准备十个队列,分别表示编号0~9
分配:令关键字为个位,遍历L的同时,令个位为i的数进入第i个队列
收集:以第0个队列为首,将0~9个队列头尾相接,成为新序列
一次分配对应一次收集,依次对十位,百位,千位,万位进行分配,收集
实现代码(C++)
自定义队列
//数组到链式的转换
void SqToLink(SqList L1,LinkList &L)
{
L = (LinkList)malloc(sizeof(LNode));
L->next = NULL;
LNode* p;
for(int i = 0; i < L1.length; i++)//头插法
{
p = (LNode*)malloc(sizeof(LNode));
p->data = L1.elem[i];
p->next = L->next;
L->next = p;
}
}
//遍历链式序列,测试使用
void TraverseLinkList(LinkList L)
{
LNode* pcur = L->next;
while(pcur)
{
cout<<pcur->data<<" ";
pcur = pcur->next;
}
}
//基数排序的按位分配
void Distribute(LinkList &L,LinkQueue* Q,int n)
{
QNode* pcur = L->next;
while(pcur)
{
int a = pcur->data;
Enqueue(Q[(a/n)%10],a);
L->next = pcur->next;
free(pcur);
pcur = L->next;
}
}
//收集队列 :
void Collect(LinkList &L,LinkQueue* Q)
{
QNode* plast = L;
for(int i = 0; i < 10; i++)
{
if(!IsEmpty(Q[i]))
{
plast->next = Q[i].front->next;
plast = Q[i].rear;
Q[i].front->next = NULL;//注意对队列的清空,为下一次分配准备
Q[i].rear = Q[i].front;
}
}
}
//基数排序
void RadixSort(SqList L)
{
LinkList L2;
SqToLink(L,L2);
// TraverseLinkList(L2);cout<<endl;
LinkQueue Q[10];
for(int i = 0; i < 10; i++)
{
InitQueue(Q[i]);
}
// TraverseLinkList(L2);
for(int i = 1; i <= 10000; i *= 10)
{
Distribute(L2,Q,i);
Collect(L2,Q);
// cout<<"collect:";TraverseLinkList(L2);cout<<endl;
}//TraverseLinkList(L2);
}
测试
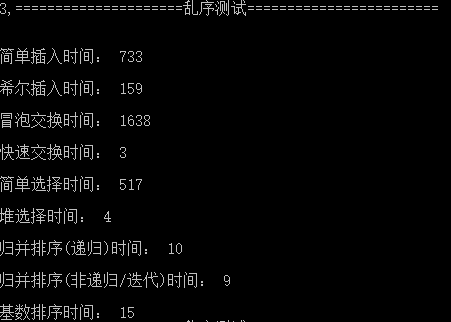
测试数据约定
- 共10组数据,每组有20000个不大于99999的随机自然数
- 第一组为降序,第二组升序,剩余八组随机乱序
测试结果
- 第一组降序
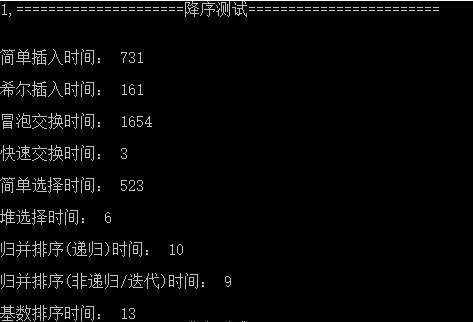
- 第二组升序
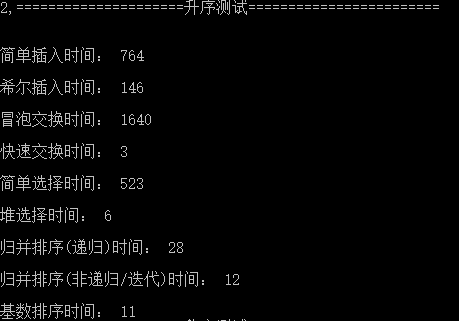
- 第三组乱序