注:所有笔记内容均来自cs231n学习视频,部分英文是因为中文翻译太绕口
最简单的分类器:Nearest Neighbor(最临近算法)
训练阶段:记住所有的训练数据和标签(什么也不做)
预测阶段:take new image and go to try to find the most similar image in the training data to the new image and predict the lable of that most similar iamge
(从训练集中找和测试图片最相似的图片,从而把最相似图片的标签作为测试图片的标签以完成分类)
K-最临近算法
K–指的是从train data中选取前K个最相似的数据,并选取K个最相似数据中出现最多的分类作为test data的分类。
最邻近算法预测阶段的时间复杂度远大于训练阶段,即是不太符合实际应用的,实际生活中,我们需要预测阶段时间越少越好(CNN)
距离比较函数(相似性度量方法)(将测试图片和train data进行比较的方法)
L1 distance(曼哈顿距离)

曼哈顿距离取得是两幅图片像素值得绝对值之后相加,如上图两幅图不同之处有456,曼哈顿距离有时候是一种较为合理比较两幅图片的方法。
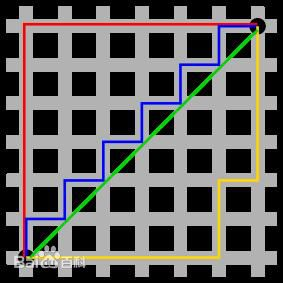
欧式距离(L2距离)

如何选择不同得距离度量函数是一个值得思考得问题,总的来说不同得距离函数will make different assumption about the underlying geometry or topology that you’ d expect in the space,二维平面内,曼哈顿距离是基于两个点之间的坐标轴差的绝对值之和,而欧式距离就是两点之间的直线距离。如下图绿色的为欧式距离,其他颜色均为曼哈顿距离。因此曼哈段距离是依赖于坐标系的选取,而欧式距离不依赖与坐标系。
if your input features ,if the individual entries in your vector have some important meaning for your task, maybe L1 might be a more natural fit;but if it is just a generic vector in some space and you don’t konw it means then maybe L2 is slightly more natural.
这两种距离度量算法应用十分广泛,不仅仅应用在图像中,此外还是处理相似性度量首先可以尝试的方法。
超参数hyper parameter
类似与K和距离度量这样的选择称为超参数,因为它们不一定能从训练数据中学到,你要提前为算法做出选择。这类参数的选择依赖于具体的问题,因此应该在实验中多次尝试选择最合适的。

IDEA 1#:the first idea you might think of is simply choosing the hyper parameter that give you the best accuracy or best performance on your train data.This is actually a terrible one.Never do this.在之前的K-最临近算法中选择K=1,会使train data分类是最完美的,然而选择更大的值,虽然train data中会错几个数据,但是对于训练集中从未出现的数据分类更佳。因为在机器学习中,我们关心的不是尽可能的拟合训练集,而是分类器能够在训练集以外的未知数据上表现得更好。
IDEA 2#:the another idea is also bad one.因为这一组测试集并不能代表在全新得数据上得表现。
IDEA 3#:更常见得做法是把数据集分为三组,大部分为训练集,还有validation set 和 test set.在训练集上用不同的超参来训练算法,然后在验证集上进行评估,选择一组在验证集上表现最好的超参,用验证集的标签来检查我们算法的表现。then run once on test data,and this is the number that tells you how your algorithm is doing on unseen data.
IDEA 4#:Cross Validation 交叉验证
划分出测试集后,把剩余的数据划分成很多份的训练集,然后轮流将每一份都当作验证集,如下图我们使用5份的交叉验证

不同的K值交叉验证的结果:

KNN performance

L1和L2距离用在比较图像上不太适合,因为这种向量化的距离函数不太适合表示图像之间视觉的相似度

维度灾难,KNN有点像是用训练数据将样本空间分为几块,要使分类器达到好的效果,我们需要训练数据能够密集地分布在空间里,否则训练数据和待测样本相似度不高也就是距离较远,而要想密集地分布,就要指数倍训练数据。实际上指数倍图片是不太可能得到。
KNN算法并没有对于潜在的分布情况进行任何预设,唯一可以使其正常工作的方法是在样本空间上有着分布密集的样本。