一、单机搭建
1.上传并解压jar包
2.在storm目录下创建logs目录,以保存程序运行时的信息
mkdir logs3.在bin目录下执行命令,启动zookeeper
./storm dev-zookeeper >> ../logs/dev-zookeeper.out 2>&1 &4.启动nimbus
./storm nimbus >> ../logs/nimbus.out 2>&1 &5.启动supervisor
./storm supervisor >> ../logs/supervisor.out 2>&1 &6.启动UI界面
./storm ui >> ../logs/ui.out 2>&1 &7.打开ui界面
http://192.168.30.141:8080/index.html
8.改造提交主类
Config conf = new Config();
if (args.length>0){
try {
StormSubmitter.submitTopology(args[0],conf,tb.createTopology());
} catch (AlreadyAliveException e) {
e.printStackTrace();
} catch (InvalidTopologyException e) {
e.printStackTrace();
}
}else {
LocalCluster lc =new LocalCluster();
lc.submitTopology("wordcount",conf,tb.createTopology());
}9.将项目打包并运行jar包
jar包路径+主类的绝对路径+任务名(随意取)
./storm jar /usr/local/spark-1.0-SNAPSHOT.jar Test wordcount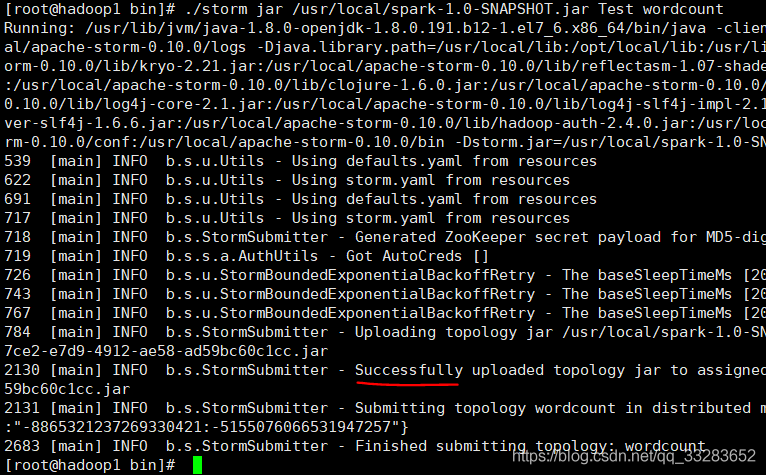
二、集群搭建
| Nimbus | Supervisor | Zookeeper | |
| hadoop1 | 1 | 1 | |
| hadoop2 | 1 | 1 | |
| hadoop3 | 1 | 1 |
1.上传并解压jar包
2.在storm目录下新建文件夹logs
3.修改conf下的storm.yaml
storm.zookeeper.servers:
- "hadoop1"
- "hadoop2"
- "hadoop3"
nimbus.host: "hadoop1"
storm.local.dir: "/tmp/storm"
supervisor.slots.ports:
- 6700
- 6701
- 6702
- 6703
4.分发到其他机子上
scp -r storm-0.10.0/ hadoop3:/usr/local/5.启动zookeeper
6.在hadoop1启动nimbus和ui界面
./bin/storm nimbus >> ./logs/nimbus.out 2>&1 &./bin/storm ui >> ./logs/ui.out 2>&1 &7.在hadoop2,hadoop3启动supervisor
./bin/storm supervisor >> ./logs/supervisor.out 2>&1 &8.提交任务:可以在从节点提交任务,但最后任务都会提交到主节点,任务信息也会保存在主节点中
./storm jar /usr/local/spark-1.0-SNAPSHOT.jar Test wordcount9.调节命令
调节worker个数,executor个数
//Topology名为wordcount的worker个数改为4,名为wcountbolt的executor的线程个数改为4
./bin/storm rebalance wordcount -n 4 -e wcountbolt=4