上一节介绍了基本工具,下面开始具体的操作流程
三、具体步骤
1.部署SecureCRT,通过ip和密码连接Linux系统,具体怎么连接就不多说了,不会的可以百度,很多教程。
2将下载好的Fuseki.tar文件传送到Linux系统上。
- 在SecureCRT上点击File——》Connect SFTP session进入SFTP窗口
-
SFTP中如果需要操作win系统,需要在linux命令前加个l。例如cd 表示进入linux系统某个文件,lcd表示进入win中某个文件。具体命令教程在此链接https://blog.csdn.net/qq_24309787/article/details/80117269
-
再linux中创建一个文件夹用来保存apache-jena-fuseki-3.10.0.tar.gz压缩包,在根目录下执行代码sudo mkdir Fuseki创建文件夹Fuseki
-
通过lcd E:/Fuseki进入fuseki压缩包根目录(我将apache-jena-fuseki-3.10.0.tar.gz保存在E:/Fuseki文件夹下)
-
在SFTP窗口通过put将文件上传到Linux系统。在进入apache-jena-fuseki-3.10.0.tar.gz根目录后执行put apache-jena-fuseki-3.10.0.tar.gz /Fuseki(此处填写需要将文件保存到的linux文件路径,我保存在)
-
到apache-jena-fuseki-3.10.0.tar.gz所在目录,通过执行tar -zxvf apache-jena-fuseki-3.10.0.tar.gz解压apache-jena-fuseki-3.10.0.tar.gz压缩文件。
-
进入解压后的apache-jena-fuseki-3.10.0.tar.gz文件目录,执行sudo ./fuseki-server --update启动服务。--update表示允许更新数据集。
-
之后会看到服务器的启动信息:
15:07:47 INFO Server :: Dataset: in-memory
15:07:47 INFO Config :: Home Directory: /home/tseg/my/jena-fusek i-0.2.7
15:07:48 INFO Server :: Dataset path = /ds
15:07:48 INFO Server :: Fuseki 0.2.7 2013-05-11T22:05:51+0100
15:07:48 INFO Server :: Started 2013/06/08 15:07:48 CST on port 3 030
表示服务以及启动完成。默认开放端口为3030,在win中可以通过访问linux的3030端口来进入Fuseki管理页面。 -
win中打开,浏览器,访问:http://(linux服务器Ip):3030 回车。出现如图所示的界面,说明配置成功。
-
- 通过点击add one 新增一个数据库
- 点击select files, 选择一个文件。比如yagoDataTest.ttl
- 单机upload now 开始上传
- Fuseki默认上传文件是有大小限制的,可以通过修改配置文件中的内存大小来改变
- 在linux中进入Fuseki根目录,执行sudo chmod -R 777 /Fuseki/fuseki-server修改该文件的只读权限
- 然后对fuseki-server文件进行编辑,具体编辑指令参考https://www.cnblogs.com/jameslif/p/7751567.html
- 执行vi fuseki-server进入该文件的编辑界面

- 将这个值改大点,大于自己上传ttl的文件大小即可。当然也不能大于自己的内存。
- 以上都完成之后可以通过python进行查询了,
-
from SPARQLWrapper import SPARQLWrapper, JSON
sparql = SPARQLWrapper("http://10.67.0.222:3030/DBpedia/query")
sparql.setQuery("""
PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#>
SELECT ?predicate ?object
WHERE { <http://dbpedia.org/resource/Zhang_Yimou> ?predicate ?object}
LIMIT 25
""")
sparql.setReturnFormat(JSON)
results = sparql.query().convert()for result in results["results"]["bindings"]:
# print result
print result["predicate"]["value"], result["object"]["value"] -
其中sparql = SPARQLWrapper("http://10.67.0.240:3030/DBpedia/query")中填写自己linux的ip和数据集的名字即可
-
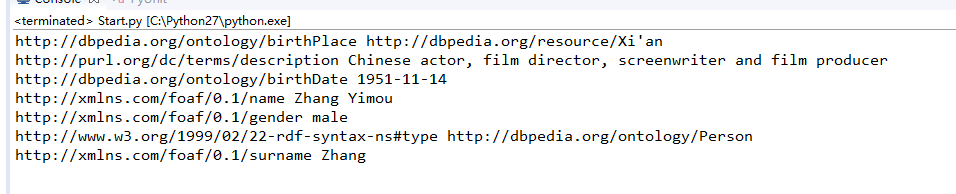
最后搜索结果
-





四、总结
按照这个步骤,就可以搭建一个简易的知识图谱查询Demo,之后我还会继续上传一些学习心得,大家一起进步