4 Greenplum 初级使用
4.1 Greenplum 常用命令列表
4.1.1 常用命令列表
进入到安装目录下的bin目录下,查看常用的使用命令:
psql / clusterdb / createdb / dropdb / dropuser / gpbackup / gpcheck / gpcopy / gp_dump / gpkafka / gpload / gpssh / gpstart / gpstate / gpstop / pg_ctl / pg_dump / pg_dumpall / postgres / postmaster / psql
4.2 PSQL命令实例
4.2.1 PSQL客户端的安装
yum install postgresql -y
如果是在非数据库集群中使用psql加载数据需要配置数据库的密码,例如以下方式:
export PGPASSWORD=123456
psql -d chinadaas -h 192.168.209.11 -p 5432 -U gpadmin
或使用
psql -d chinadaas -h 192.168.209.11 -p 5432 -U gpadmin -W 123456
4.2.2 PSQL命令的使用
$ psql --help
This is psql 8.3.23, the PostgreSQL interactive terminal (Greenplum version).
Usage:
psql [OPTION]... [DBNAME [USERNAME]]
General options:
-c, --command=COMMAND run only single command (SQL or internal) and exit
-d, --dbname=DBNAME database name to connect to (default: "gpadmin")
-f, --file=FILENAME execute commands from file, then exit
-l, --list list available databases, then exit
-v, --set=, --variable=NAME=VALUE
set psql variable NAME to VALUE
-X, --no-psqlrc do not read startup file (~/.psqlrc)
-1 ("one"), --single-transaction
execute command file as a single transaction
--help show this help, then exit
--version output version information, then exit
Input and output options:
-a, --echo-all echo all input from script
-e, --echo-queries echo commands sent to server
-E, --echo-hidden display queries that internal commands generate
-L, --log-file=FILENAME send session log to file
-n, --no-readline disable enhanced command line editing (readline)
-o, --output=FILENAME send query results to file (or |pipe)
-q, --quiet run quietly (no messages, only query output)
-s, --single-step single-step mode (confirm each query)
-S, --single-line single-line mode (end of line terminates SQL command)
Output format options:
-A, --no-align unaligned table output mode
-F, --field-separator=STRING
set field separator (default: "|")
-H, --html HTML table output mode
-P, --pset=VAR[=ARG] set printing option VAR to ARG (see \pset command)
-R, --record-separator=STRING
set record separator (default: newline)
-t, --tuples-only print rows only
-T, --table-attr=TEXT set HTML table tag attributes (e.g., width, border)
-x, --expanded turn on expanded table output
Connection options:
-h, --host=HOSTNAME database server host or socket directory (default: "local socket")
-p, --port=PORT database server port (default: "5432")
-U, --username=USERNAME database user name (default: "gpadmin")
-w, --no-password never prompt for password
-W, --password force password prompt (should happen automatically)
For more information, type "\?" (for internal commands) or "\help" (for SQL
commands) from within psql, or consult the psql section in the PostgreSQL
documentation.
Report bugs to <[email protected]>.
以上常用的参数如下所示:
-d 链接数据库的名字,默认的名字是gpadmin
-h 数据库服务器链接地址,默认的是localhost
-p 数据库服务的端口
-U 数据库用户名
-W 链接用户密码
实例展示
$ psql -d chinadaas -h 192.168.209.11 -p 5432 -U gpadmin -W 123456
进入数据后可以查看帮助信息
chinadaas=# help
You are using psql, the command-line interface to PostgreSQL.
Type: \copyright for distribution terms
\h for help with SQL commands
\? for help with psql commands
\g or terminate with semicolon to execute query
\q to quit
4.2.2.2.1 COPY导入参数说明
COPY table [(column [, ...])] FROM {'file' | STDIN}
[ [WITH]
[BINARY]
[OIDS]
[HEADER]
[DELIMITER [ AS ] 'delimiter']
[NULL [ AS ] 'null string']
[ESCAPE [ AS ] 'escape' | 'OFF']
[NEWLINE [ AS ] 'LF' | 'CR' | 'CRLF']
[CSV [QUOTE [ AS ] 'quote']
[FORCE NOT NULL column [, ...]]
[FILL MISSING FIELDS]
[[LOG ERRORS]
SEGMENT REJECT LIMIT count [ROWS | PERCENT] ]
4.2.2.2.2 COPY 导出参数说明
COPY {table [(column [, ...])] | (query)} TO {'file' | STDOUT}
[ [WITH]
[ON SEGMENT]
[BINARY]
[OIDS]
[HEADER]
[DELIMITER [ AS ] 'delimiter']
[NULL [ AS ] 'null string']
[ESCAPE [ AS ] 'escape' | 'OFF']
[CSV [QUOTE [ AS ] 'quote']
[FORCE QUOTE column [, ...]] ]
[IGNORE EXTERNAL PARTITIONS ]
4.2.2.3.1 普通导出数据
psql -U gpadmin -d chinadaas -h 192.168.209.11 -p 5432 -c "copy (select * from tablename) to 'filepath' WITH DELIMITER AS E'\u0001' NULL as 'null string' "
tablename 表的名字
filepath 保存文件的路径
E'\u0001' 字段之间的分隔符,是二进制的,二进制显示为SOH,也可以是其他的分隔符,详见https://blog.csdn.net/xfg0218/article/details/80901752
注意:如果在非集群上master节点上执行命令请在copy前加\即为:\copy 会把文件落到本机器上

4.2.2.3.2 查看导出的数据
查看导出的数据

以上的分隔符便是SOH,二进制符号
4.2.2.3.3 导出数据带标题
# psql -U gpadmin -d stagging -h 192.168.209.11 -p 5432 -c "copy (select * from xiaoxu.table2) to '/home/xiaoxu/table2.csv' WITH DELIMITER AS E'\u0001' NULL as 'null string' ESCAPE as 'OFF' HEADER "
以下是在GP数据库中保存的数据样式
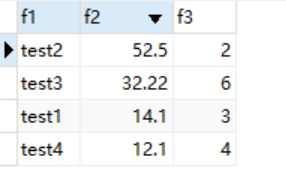
以下是导出到本地的数据样式

可以看到第一行已经有标题了,并且还是按照分隔符正确的分割
4.2.2.4.1 普通导入数据
psql -U gpadmin -d chinadaas -h 192.168.209.11 -p 5432 -U gpadmin -c "COPY tablename FROM 'filepath' WITH csv DELIMITER E'\001' LOG ERRORS SEGMENT REJECT LIMIT 3000 ROWS "
tablename 表的名字
filepath 保存文件的路径
NULL as 'null string' 表示在数据库中以空输入
LOG .. ROWS 是允许在加载数据时允许错误的数据行数,最小可以设置为2,如果去掉可以做该内容可以约束,不允许有错误数据。
注意:如果在非集群上master节点上执行命令请在copy前加\即为:\copy 会把本地的文件加载到GP中。在PSQL语句中添加NULL as 'null string' 即可实现空值。

4.2.2.4.2 替换表中的NULL
psql -U gpadmin -d chinadaas -h 192.168.209.11 -p 5432 -U gpadmin -c "COPY tablename FROM 'filepath' WITH csv DELIMITER E'\001' NULL as 'null string' LOG ERRORS SEGMENT REJECT LIMIT 3000 ROWS "

4.2.2.4.3 使用标准输入的方式加载数据
$ psql -U gpadmin -d stagging -h 192.168.209.11 -p 5432 -c "copy tablename from stdin WITH DELIMITER AS E'\u0001' NULL as 'null string' ESCAPE as 'OFF'" < filepath
tablename : 表的名字
filepath : 文件的路径
在以上可以看出stdin关键字即可实现标准输入的方式导入到数据,但该方式没有导入到多少行的提示
4.2.3 常用加载数据方式
$ psql -d stagging -h 192.168.209.11 -p 5432 -U gpadmin -f /home/xiaoxu/t_tmp.sql
INSERT 0 1
INSERT 0 1
在以上可以看出已经插入了两条数据
$ psql -d stagging -h 192.168.209.11 -p 5432 -U gpadmin -c “insert into test_schema.t_temp(id) values(1)”
INSERT 0 1
以上test_schema是schema的名字,t_temp是表名
4.3 数据库支持的数据类型
4.3.1 numeric类型
| 字段名字 |
存储大小 |
描述 |
范围 |
| smallint |
2 bytes |
小范围的整数类型 |
-32768 to +32767 |
| integer |
4 bytes |
常用整数类型 |
-2147483648 to +2147483647 |
| bigint |
8 bytes |
大范围的整数 |
-9223372036854775808 to +9223372036854775807 |
| decimal |
可变类型 |
用户指定精度 |
小数点前131072位,和小数点后16383位 |
| numeric |
可变类型 |
用户指定精度 |
小数点前131072位,和小数点后16383位 |
| real |
4 bytes |
用户指定精度 |
精确到6位小数 |
| double precision |
8 bytes |
用户指定精度 |
精确到15位小数 |
| smallserial |
2 bytes |
自增整数 |
1 to 32767 |
| serial |
4 bytes |
自动递增 |
1 to 2147483647 |
| bigserial |
8 bytes |
大自动递增整数 |
1 to 9223372036854775807 |
chinadaas=# CREATE TABLE ods.test_filed_type (filed1 smallint,filed2 integer,filed3 bigint,filed4 decimal,filed5 numeric,filed6 real) DISTRIBUTED BY (filed1);;
CREATE TABLE
Time: 122.507 ms
Time: 0.200 ms
chinadaas=# INSERT INTO ods.test_filed_type (filed1,filed2,filed3,filed4,filed5,filed6) values(1234,1234,1234,12.12,12.12,1.1234);
INSERT 0 1
Time: 113.667 ms
chinadaas=# select * from ods.test_filed_type;
filed1 | filed2 | filed3 | filed4 | filed5 | filed6
--------+--------+--------+--------+--------+--------
1234 | 1234 | 1234 | 12.12 | 12.12 | 1.1234
(1 row)
Time: 24.180 ms
4.3.2 二进制类型
| 字段名字 |
存储大小 |
描述 |
| bytea |
1或者4字节的二进制字符串 |
可变长度二进制字符串 |
创建支持二进制的表
chinadaas=# CREATE TABLE ods.test_filed_type (id serial NOT NULL ,filed1 bytea) DISTRIBUTED BY (id);
CREATE TABLE
Time: 498.208 ms
Time: 0.204 ms
插入二进制数据
chinadaas=# insert into ods.test_filed_type(id,filed1) values(1,decode('5L2g5aW9','base64'));
INSERT 0 1
Time: 122.989 ms
chinadaas=# select * from ods.test_filed_type;
id | filed1
----+--------------------------
1 | \344\275\240\345\245\275
(1 row)
Time: 21.901 ms
详情资料请查看以下资料:
https://gpdb.docs.pivotal.io/5140/ref_guide/data_types.html
https://blog.csdn.net/xinpo66/article/details/18961427
https://www.postgresql.org/docs/9.2/datatype-binary.html
https://jdbc.postgresql.org/documentation/publicapi/index.html
https://jdbc.postgresql.org/documentation/head/binary-data.html
4.3.3 日期/时间类型
| 字段名字 |
存储大小 |
描述 |
范围 |
精确度 |
| timestamp |
8 字节 |
日期和时间 |
4713 BC 到 294276 AD |
1 微妙 |
| timestamp |
8 字节 |
日期和时间和区域的时间 |
4713 BC 到 294276 AD |
1 微妙 |
| date |
4 字节 |
日期 |
4713 BC 到 294276 AD |
1 天 |
| time |
8 字节 |
当天的时间 |
0:00:00 到 1900/1/1 0:00:00 |
1 微妙 |
| time |
12 字节 |
当天的时间 |
00:00:00+145 到 24:00:00-1459 |
1 微妙 |
| interval [ |
16 字节 |
时间间隔 |
-178000000 |
1 微妙 |
chinadaas=# \timing
Timing is on.
chinadaas=# create table ods.test_timestamp(filed1 timestamp(4),filed2 date,filed3 time,filed4 interval) DISTRIBUTED BY (filed1);;
CREATE TABLE
Time: 16768.711 ms
Time: 0.192 ms
chinadaas=# insert into ods.test_timestamp(filed1,filed2,filed3,filed4) values('2018-12-10 10:44:05','2018-12-10','10:44:13','100');
INSERT 0 1
Time: 58.056 ms
chinadaas=# select * from ods.test_timestamp;
filed1 | filed2 | filed3 | filed4
---------------------+------------+----------+----------
2018-12-10 10:44:05 | 2018-12-10 | 10:44:13 | 00:00:10
2018-12-10 10:44:05 | 2018-12-10 | 10:44:13 | 00:01:40
(2 rows)
Time: 12.617 ms
在以上可以看出filed4储存的规则是可以直接储存秒,会自动转化为分钟或小时
4.3.4 boolean 类型
| 字段名字 |
存储大小 |
描述 |
| boolean |
1 byte |
只有true和false值 |
stagging=# create table test_boolean(index serial NOT NULL,judge boolean) DISTRIBUTED BY(index);
NOTICE: CREATE TABLE will create implicit sequence "test_boolean_index_seq" for serial column "test_boolean.index"
CREATE TABLE
Time: 107.003 ms
stagging=# insert into test_boolean(judge) values('false');
INSERT 0 1
Time: 102.984 ms
stagging=# insert into test_boolean(judge) values('true');
INSERT 0 1
Time: 44.549 ms
stagging=# select * from test_boolean;
index | judge
-------+-------
2 | t
1 | f
(2 rows)
Time: 10.397 ms
在以上中可以看出数据库中知保存了t或f,表示true或false
4.3.5 几何类型
| 字段名字 |
存储大小 |
描述 |
显示效果 |
| point |
16 bytes |
面板上的点 |
(x,y) |
| line |
32 bytes |
无限线段 |
{A,B,C} |
| lseg |
32 bytes |
有限线段 |
((x1,y1),(x2,y2)) |
| box |
32 bytes |
矩形盒 |
((x1,y1),(x2,y2)) |
| path |
16+16n bytes |
闭合路径(类似于多边形) |
((x1,y1),...) |
| path |
16+16n bytes |
开合路径 |
[(x1,y1),...] |
| polygon |
40+16n bytes |
多边形(类似于闭合路径) |
((x1,y1),...) |
| circle |
24 bytes |
圆形 |
<(x,y),r> (center pointand radius) |
chinadaas=# CREATE TABLE public.test_geometry (index serial NOT NULL,filed1 point,filed2 lseg,filed3 box) DISTRIBUTED BY (index);
NOTICE: CREATE TABLE will create implicit sequence "test_geometry_index_seq" for serial column "test_geometry.index"
CREATE TABLE
Time: 1648.150 ms
chinadaas=# insert into public.test_geometry(filed1,filed2,filed3) values('(10,3)','[(1,2),(3,4)]','(3,4),(1,2)');
INSERT 0 1
Time: 642.743 ms
chinadaas=# select * from public.test_geometry;
index | filed1 | filed2 | filed3
-------+--------+---------------+-------------
1 | (10,3) | [(1,2),(3,4)] | (3,4),(1,2)
(1 row)
Time: 25.347 ms
在以上可以看出能存一些简单集合类型数据
4.3.6 网络类型
| 字段名字 |
存储大小 |
描述 |
| cidr |
7 or 19 字节 |
IPv4 和 IPv6 网络 |
| inet |
7 or 19 字节 |
I Pv4 和 IPv6 地址 and 网络 |
| macaddr |
6 字节 |
MAC 地址 |
| macaddr8 |
8 字节 |
MAC 地址 (EUI-64 format) |
chinadaas=# CREATE TABLE public.test_address (filed1 cidr,filed2 inet,filed3 macaddr)WITH (OIDS=FALSE);
CREATE TABLE
Time: 3577.951 ms
chinadaas=# INSERT INTO "public"."test_address" VALUES ('192.168.30.123/32', '192.168.30.123', '80:18:44:f3:ab:b8');
INSERT 0 1
Time: 531.198 ms
chinadaas=# INSERT INTO "public"."test_address" VALUES ('192.168.30.200/32', '192.168.30.100', '80:18:44:f3:ab:b8');
INSERT 0 1
Time: 330.715 ms
以上的地址可以在linux使用ifconfig来获取,效果如下

4.3.7 常用数据类型
| 类型名称 |
存储空间 |
描述 |
范围 |
| smallint |
2字节 |
小范围整数 |
-32768到+32767 |
| integer |
4字节 |
常用的整数 |
-2147483648到+2147483647 |
| bigint |
8字节 |
常用的整数 |
-9223372036854775808到9223372036854775807 |
| decimal |
变长 |
用户制定精度 |
无限制 |
| numeric |
变长 |
用户制定精度 |
无限制 |
| real |
4字节 |
可变精度 |
6位十进制数字精度 |
| double precision |
8字节 |
可变精度 |
15位十进制数字精度 |
| serial |
4字节 |
自增整数,可做主键 |
1到2147483647 |
| bigserial |
8字节 |
大范围的自增整数 |
1到9223372036854775807 |
| timestamp |
8字节 |
日期和时间 |
4713 BC 到 294276 A |
| varchar |
变长 |
储存字符串类型 |
varchar()不写表示不受限制 |
chinadaas=# create table public.commonly_type(filed varchar,filed2 integer,filed3 numeric,filed4 timestamp,filed5 date,filed6 boolean);
CREATE TABLE
Time: 3493.506 ms
chinadaas=# insert into public.commonly_type values('1111',2222,3333,'2018-12-10 10:44:05','2018-12-10','t');
INSERT 0 1
Time: 485.904 ms
chinadaas=# select * from public.commonly_type;
filed | filed2 | filed3 | filed4 | filed5 | filed6
-------+--------+--------+---------------------+------------+--------
1111 | 2222 | 3333 | 2018-12-10 10:44:05 | 2018-12-10 | t
(1 row)
Time: 21.978 ms
4.4 常用函数
4.4.1 字符串函数
| 函数 |
返回类型 |
描述 |
| string||string |
text |
字符串连接 |
| length(string) |
int |
string中字符的数目 |
| position( |
int |
指定的子字符串的位置 |
| substring( |
text |
抽取子字符串 |
| trim([leading|trailing|both] |
text |
从字符串string的开头/结尾/两边 |
| lower(string) |
text |
把字符串转化为小写 |
| upper(string) |
text |
把字符串转化为大写 |
| overlay(string placing |
text |
替换子字符串 |
| replace(string text, |
text |
把字符串string中出现 |
| split_part(string text, |
text |
根据delimiter分隔string |
4.4.1.2.1 拼接字符串
# select 'green'||'plum';
?column?
-----------
greenplum
(1 row)
Time: 28.432 ms
4.4.1.2.2 查看字符的长度
chinadaas=# select length('greenplum');
length
--------
9
(1 row)
Time: 14.937 ms
4.4.1.2.3 查看制定字符在字符串的位置
chinadaas=# select position('pl' in 'greenplum');
position
----------
6
(1 row)
Time: 7.908 ms
4.4.1.2.4 获取制定的分割字段
chinadaas=# select split_part('green|plum','|',2);
split_part
------------
plum
(1 row)
Time: 7.776 ms
4.4.2 时间函数
| 函数 |
返回类型 |
描述 |
| age(timestamp,timestamp) |
interval |
减去参数后的”符号化”结果 |
| age(timestam) |
interval |
从current_date减去参数中的日期 |
| current_date |
date |
当前的日期 |
| current_date |
time with time zone |
当日时间 |
| current_timestamp |
timestamp with time zone |
当前事务开始时的事件戳 |
| date_part(text,timestamp) |
double precision |
当前事务开始时的事件戳 |
| date_trunc(text,timestamp) |
timestamp |
截断成指定的精度 |
| extract(field from timestamp) |
double precision |
获取子域 |
| now() |
double precision |
当前事务开始的时间戳 |
4.4.2.2.1 获取当前的日期
chinadaas=# select current_date;
date
------------
2018-12-11
(1 row)
Time: 8.275 ms
4.4.2.2.2 获取当前的时间戳
chinadaas=# select current_timestamp;
now
-------------------------------
2018-12-11 19:31:00.971091+08
(1 row)
Time: 8.348 ms
4.4.3 数值计算函数
| 函数 |
返回类型 |
描述 |
| abs(x) |
(与x相同) |
绝对值 |
| ceil(dp或numeric)\ceiling |
(与输入相同) |
不小于参数的最小整数 |
| exp(dp或numeric) |
(与输入相同) |
自然指数 |
| ln(dp或numeric) |
(与输入相同) |
自然对数 |
| log(dp或numeric) |
(与输入相同) |
以10 为底的对数 |
| log(b numeric,x numeric) |
numeric |
以b为底的对数 |
| mod(y,x) |
(与参数类型相同) |
y/x的余数 |
| pi() |
dp |
π |
| power(a numeric,b numeric) |
numeric |
a的b次幂 |
| radians(dp) |
dp |
把角度转为弧度 |
| random() |
dp |
0~1之间的随机数 |
| floor(dp或numeric) |
(与输入相同) |
不大于参数的最大整数 |
| round(v numeric,s int) |
numeric |
圆整为s位小数 |
| sign(dp或numeric) |
(与输入相同) |
参数的符号(-1,0,+1) |
| sqrt(dp或numeric) |
(与输入相同) |
平方根 |
| cbrt(dp) |
dp |
立方根 |
| trunc(v numeric,s int) |
numeric |
截断为s位小数 |
4.4.3.2.1 查看数据的绝对值
chinadaas=# select abs(100);
abs
-----
100
(1 row)
Time: 9.255 ms
4.4.3.2.2 查看π的数值
chinadaas=# select pi();
pi
------------------
3.14159265358979
(1 row)
Time: 8.524 ms
哇,好长的,记不住,脑子笨....
4.4.3.2.3 查看随机数
chinadaas=# select random();
random
------------------
0.73948382679373
(1 row)
Time: 3.776 ms
随机数在测试数据时用的比较多,须记住、、、
4.4.3.2.4 获取制定精度
chinadaas=# select trunc(123.123,2);
trunc
--------
123.12
(1 row)
Time: 7.359 ms
这个很有用奥,需要记住、、
4.4.4 其他常用函数
序列号生成函数语法generate_series(start,end,step)
实例如下:
chinadaas=# select generate_series(1,5,1);
generate_series
-----------------
1
2
3
4
5
(10 rows)
Time: 7.812 ms
一般的这个函数用于生成测试数据常用。
查看原始数据
chinadaas=# select * from test_t1;
name | id | age
-------+----+-----
test2 | 1 | 12
test1 | 1 | 10
(2 rows)
Time: 19.880 ms
转换后的数据,也可以把排序省略
chinadaas=# select string_agg(name,'|' order by name) from test_t1;
string_agg
-------------
test1|test2
(1 row)
Time: 22.533 ms
chinadaas=# select md5('greenplum');
md5
----------------------------------
91f00712a0843e1975f6a500ab90d3c4
(1 row)
Time: 33.693 ms
查看原始数据格式
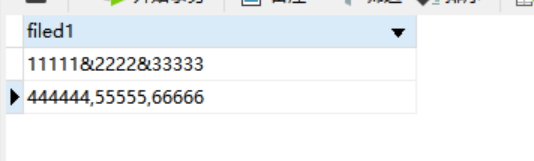
可以看到第一行的连接符是&,第二行的连接符是|
select regexp_split_to_table(filed1, '&') from public.test_test;

4.5 常见DDL语句
4.5.1 更改表名
# alter table t_tmp rename to t_temp;
t_tmp 原始表明
t_temp 需要修改后的表明
4.5.2 修改表字段
update tablename set fieldname=null where fieldname='null';
alter table tablename alter column "fieldname" type date using ("fieldname"::text::date);
tablename 需要修改的表明
fieldname 字段的名字
以上的语句是先把fieldname字段修改为text类型再修改为date类型,date类型接收null类型,但不接受’null’字符,使用第一个SQL修改即可。
alter table tablename alter column fieldname type character varying(40);
tablename 需要修改的表明
fieldname 字段的名字
以上语句是把原始字符串的长度修改为为40
alter table tablename add fieldname varchar(120);
alter table tablename drop column fieldname ;
tablename 需要修改的表明
fieldname 字段的名字
以上是先增加一个字段,再删除一个字段。
alter table tablename alter column fieldname type timestamp(6) using fieldname ::timestamp;
tablename 需要修改的表明
fieldname 字段的名字
以上的语句是把字段修改为timestamp类型,长度为6
alter table tablename alter column fieldname type numeric(26,6) using fieldname ::numeric;
tablename 需要修改的表明
fieldname 字段的名字
以上的语句是把字段修改为numeric类型,长度为26,保留精度为6
参考资料:https://www.postgresql.org/message-id/dcc563d11002241235x363052afm8b22fe9433c3cc36%40mail.gmail.com
alter table tablename alter column fieldname set not null;
tablename 需要修改的表明
fieldname 字段的名字
以上语句是修改字段部位null
4.5.2.7 字段重命名
alter table tablename rename column fieldname to newfieldname;
tablename 需要修改的表明
fieldname 字段的名字
newfieldname 新字段的名字
4.5.2.8.1 添加默认值
alter table tablename alter column fieldname set default defaulrvalue;
tablename 需要修改的表明
fieldname 字段的名字
defaulrvalue 默认的数值
4.5.2.8.2 删除默认值
alter table tablename alter column fieldname drop default;
tablename 需要修改的表明
fieldname 字段的名字
4.5.3创建与删除DATABASE语句
chinadaas=# create database test_database;
CREATE DATABASE
chinadaas=# drop database test_database;
DROP DATABASE
4.5.4创建与删除SCHEMA语句
stagging=# \timing
Timing is on.
stagging=# create schema temp_schema;
CREATE SCHEMA
Time: 1170.509 ms
stagging=# drop schema temp_schema cascade;
DROP SCHEMA
Time: 566.586 ms
4.5.5 更改表的分布键
alter table tablename set with (appendonly = true, compresstype = zlib, compresslevel = 5
,orientation=column, checksum = false,blocksize = 2097152) distributed by (fieldname1,fieldname2);
tablename : 表的名字
appendonly=true, orientation=column这两个属性决定了这是列存压缩表。
compresstype: 压缩方式,支持zlip,rte等
compresslevel: 压缩级别,0-9,一般压缩级别为5即可
blocksize: 块大小8KB-2MB, 大小在8192 - 2097152 之间并且是8192的倍数
distributed by(fieldname1,fieldname2) : 分布键可以以多个设置,也可以设置一个,GP会hash分布到不同的segment上
4.6 gpload命令使用
gpload命令的详细使用方法请查看:https://blog.csdn.net/xfg0218/article/details/85124211