目前pentaho——kettle已经到了8.1的版本了,本文主要介绍如何利用kettle进行大数据处理。
好,下面上货。
1、下载shims,简单的说这个shim可以理解成针对不同cdh的版本的插件,具体下载地址在这里:
我用的是cdh510.
https://sourceforge.net/projects/pentaho/files/Pentaho%208.1/
在下载的时候如果发现没有对应的版本,那么可以去其他的pentaho版本中去找。经过我的试验,我发现,这个shim是针对第三方的版本,而不是pentaho 的版本,也就是说,无论你用的是pentaho——kettle的哪个版本,这个shim是通用的,只需要找到你的第三方针对的版本即可。
我从pentaho7.1中找到了下载cdh510的包(下载地址在下面)
以下步骤主要参考:
https://help.pentaho.com/Documentation/8.2/Setup/Configuration/Hadoop_Clusters/Cloudera
2、下载完成后需要简单的安装。其实就是把对应的cdh510文件夹生成一下,生成好后,直接copy到kettle的文件夹中。
/pentaho/data-integration/plugins/pentaho-big-data-plugin/hadoop-configurations
3、修改kettle连接的cdh版本
/pentaho/data-integration/plugins/pentaho-big-data-plugin
active.hadoop.configuration=cdh510
4、从hadoop集群中复制文件到shim文件夹中,替换已有的文件。
- core-site.xml
- hbase-site.xml
- hdfs-site.xml
- hive-site.xml
- mapred-site.xml
- yarn-site.xml.
这里可以优先替换core-site.xml,其他的等到使用到的时候再替换即可。
目前主要使用的就是core-site.xml这个文件,从hadoop集群中拷贝出这个文件。我目前用的是cdh,位置是在
/etc/hadoop/conf.cloudera.hdfs文件夹下。
5、然后我们还需要修改一下对应的权限问题:
目录是在cdh10的shims中
/pentaho/data-integration/plugins/pentaho-big-data-plugin/hadoop-configurations/cdh510
在文件config.properties最后,添加:
authentication.superuser.provider=NO_AUTH
6、我们尝试在kettle中创建一个hadoop cluster,具体我们可以参考这里:
上面的连接中有全部的连接。我们看一下这个基本的操作。


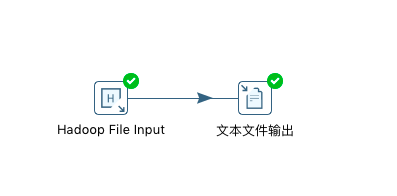
7、接下来我们可以做一个简单的读取hdfs文件内容,同时写入到本地文件系统的例子。
下图是预览数据后的截图:

8、 之后我们就可以简单的把文件处理输出到本地文件系统中了。从而我们成功的连接了hdfs,而且,我们也能够操作hdfs了。
最后我们本地文件的内容:
aa;bb;cc;dd
1;2;3;4
1;2;3;5
2;2;6;5
2;3;4;5
2;3;6;4
2;2;8;4
综上,我们能够使用kettle进行hdfs中数据的读取,这也就意味着,我们能够使用kettle进行hdfs上的大数据ETL了。