1、绪论
神经网络技术起源于上世纪五、六十年代,当时叫感知机(perceptron),拥有输入层、输出层和一个隐含层。输入的特征向量通过隐含层变换达到输出层,在输出层得到分类结果。但是,Rosenblatt的单层感知机有一个严重得不能再严重的问题,即它对稍复杂一些的函数都无能为力。随着数学的发展,这个缺点直到上世纪八十年代才被Rumelhart、Williams、Hinton、LeCun等人(反正就是一票大牛)发明的多层感知机(multilayer perceptron)克服。多层感知机,顾名思义,就是有多个隐含层的感知机。
2、感知机原理
先看下人工神经元的结构:
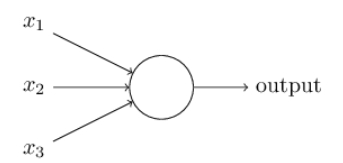
输出是线性的 :
因为感知机是二分类算法,所以会套一个函数:
在神经网络中,套在线性变换外面的这个函数称作激活函数,激活函数可以是线性的f(x)=xf(x)=x,或者是非线性的,例如sigmoid,tanh,relusigmoid,tanh,relu等常用的。
3、 DNN前向传播过程
DNN的前向传播算法不算太难。所谓的DNN的前向传播算法也就是利用我们的若干个权重系数矩阵,偏倚向量
来和输入值向量
进行一系列线性运算和激活运算,从输入层开始,一层层的向后计算,一直到运算到输出层,得到输出结果为值。
输入: 总层数,当前层是
,当前层隐藏层和输出层对应的矩阵
,偏倚向量
,输入值向量
,神经元个数
输出:输出层的输出
- 初始化
其中每个变量的维度是 ,
,
,
最后的结果即为输出。我们现在了解了DNN的前向传播的过程,但是我们会有疑问,DNN中如何更新这么多的W,b呢,当然还是运用神奇的梯度下降法来更新。在神经网络中运用梯度下降法的过程就是反向更新。
注意:其中公式里面的公式表示,参考吴恩达老师的机器学习或者深度学习。
上面只是一个参考。参考了作者:https://www.cnblogs.com/huangyc/p/9999855.html
