版权声明:本文为博主原创文章,转载请注明出处。 https://blog.csdn.net/fgszdgbzdb/article/details/83659965
上篇文章BloomFilter介绍了Int型BloomFilter的基本用法,本篇则主要集中叙述针对String类型的BloomFilter
分为以下几点:
- 具体实现
- 一次Hash
- 多次Hash
- 试验比较
- 应用场景
针对String 型数据的BloomFilter
import java.util.BitSet;
import java.util.LinkedHashMap;
import java.util.Map;
/**
* BloomFilter 抽象类
*/
public abstract class AbstractBloomFilter {
/**
* 布隆过滤器的比特长度
*/
protected static final int DEFAULT_SIZE = 1 << 12;
/**
* 申请的 bit 位
*/
protected static BitSet bits = new BitSet(DEFAULT_SIZE);
/**
* bloom 测试
*
* @param bloomFilter
* @param times
*/
public static Map<Double, Double> hashCompareTest(AbstractBloomFilter bloomFilter, int times) {
if (times < 0 || times > 10) {
throw new ParamNotValidException(PrintUtil.format("times not valid:{}", times));
}
Map<Double, Double> fppMap = new LinkedHashMap<>();
String filterName = bloomFilter.getClass().getSimpleName();
PrintUtil.prettyPrint("BloomFilter————{}", filterName);
int insertNum = DEFAULT_SIZE << times;
int testNum = 1000000;
for (int i = 0; i < 15; i++) {
bloomFilter.insertStringArr(insertNum);
int errNum = bloomFilter.testStringArr(testNum);
double fpp = bloomFilter.printInfo(DEFAULT_SIZE, insertNum, testNum, errNum);
fppMap.put(insertNum * 1.0 / DEFAULT_SIZE, fpp);
bloomFilter.clearBloom();
// insertNum >>= 1;
insertNum = 3 * insertNum / 4;
}
PrintUtil.dotRow();
return fppMap;
}
/**
* 添加元素
*
* @param value
*/
abstract void add(String value);
/**
* 是否包含指定字符串
*
* @param value
* @return
*/
abstract boolean contains(String value);
/**
* 清空过滤器
*/
void clearBloom() {
bits.clear();
}
/**
* 插入指定数量的字符串
*
* @param insertNum
*/
protected void insertStringArr(int insertNum) {
String[] insertionStr = DataGenerator.getRandomStringArr(insertNum, 5);
for (String s : insertionStr) {
add(s);
}
}
/**
* 检测指定数量的字符串
*
* @param testNum
* @return
*/
protected int testStringArr(int testNum) {
int errNum = 0;
String[] testStr = DataGenerator.getRandomStringArr(testNum, 6);
for (String s : testStr) {
if (contains(s)) {
errNum++;
}
}
return errNum;
}
/**
* 打印测试结果
*
* @param cap
* @param insert
* @param test
* @param error
*/
protected double printInfo(int cap, int insert, int test, int error) {
double fpp = error * 100.0 / test;
PrintUtil.prettyPrint("cap:{} \t insert:{} \t test:{} \t error:{} \t fpp(%):{}", cap, insert, test, error, fpp);
return fpp;
}
}
- 一次Hash
public class SingleHashBloFilter extends AbstractBloomFilter {
private static int getIndex(String value) {
// 直接使用 hashCode
int hashCode = value.hashCode();
// 取余
return hashCode & (DEFAULT_SIZE - 1);
}
@Override
public void add(String value) {
if (value != null) {
int index = getIndex(value);
bits.set(index, true);
}
}
@Override
public boolean contains(String value) {
if (value == null) {
return false;
}
int index = getIndex(value);
return bits.get(index);
}
}
- 多次 Hash
public class MultiHashBloFilter extends AbstractBloomFilter {
/**
* 这里要选取质数,能很好的降低错误率
*/
private static final int[] SEEDS = {3, 5, 7, 11, 13, 31, 37, 61};
private static SimpleHash[] func = new SimpleHash[SEEDS.length];
/**
* 初始化 hash 函数
* 容量相同,种子不同
*/
static {
for (int i = 0; i < SEEDS.length; i++) {
func[i] = new SimpleHash(DEFAULT_SIZE, SEEDS[i]);
}
}
/**
* 简单测试
*/
public static void ordinaryTest() {
String value = "[email protected]";
MultiHashBloFilter bloFilter = new MultiHashBloFilter();
bloFilter.add(value);
System.out.println(bloFilter.contains(value));
String value2 = "[email protected]";
System.out.println(bloFilter.contains(value2));
}
private void addValue(String value) {
//将字符串value哈希为8个或多个整数,然后在这些整数的bit上变为1
for (SimpleHash f : func) {
int index = f.hash(value);
/**
* 8个函数,对同一区间进行的 bit分配
*/
bits.set(index, true);
}
}
@Override
public void add(String value) {
if (value != null) {
addValue(value);
}
}
@Override
public boolean contains(String value) {
if (value == null) {
return false;
}
for (SimpleHash f : func) {
boolean ret = bits.get(f.hash(value));
// false 直接返回
if (!ret) {
return ret;
}
}
return true;
}
}
- 试验比较
/**
* hash 测试
*/
public static void hashTimesCompare() {
// 单次 hash 过滤器测试入口
AbstractBloomFilter singFilter = new SingleHashBloFilter();
AbstractBloomFilter.hashCompareTest(singFilter, 4);
// 多次 hash 过滤器测试入口
AbstractBloomFilter multiFilter = new MultiHashBloFilter();
AbstractBloomFilter.hashCompareTest(multiFilter, 2);
}
public static void main(String[] args) {
hashTimesCompare();
}
执行结果:
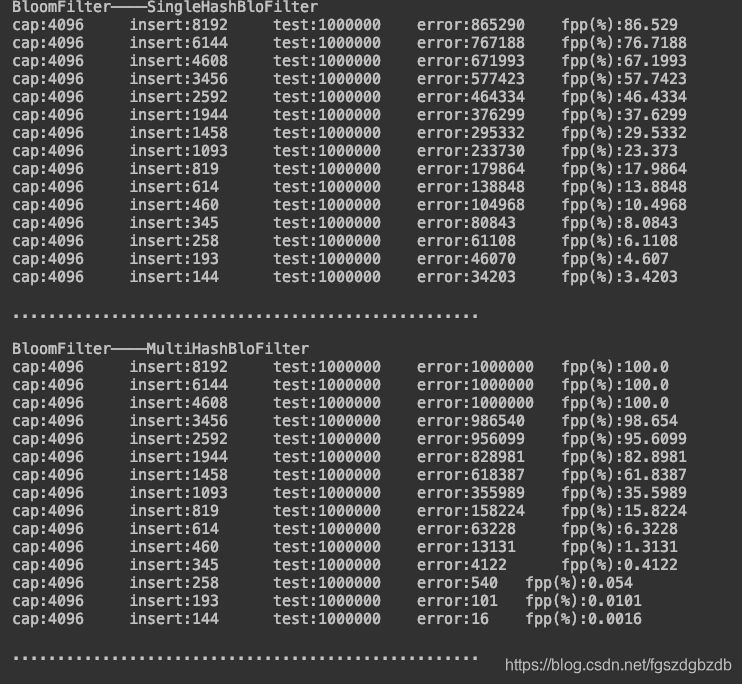
对比图表
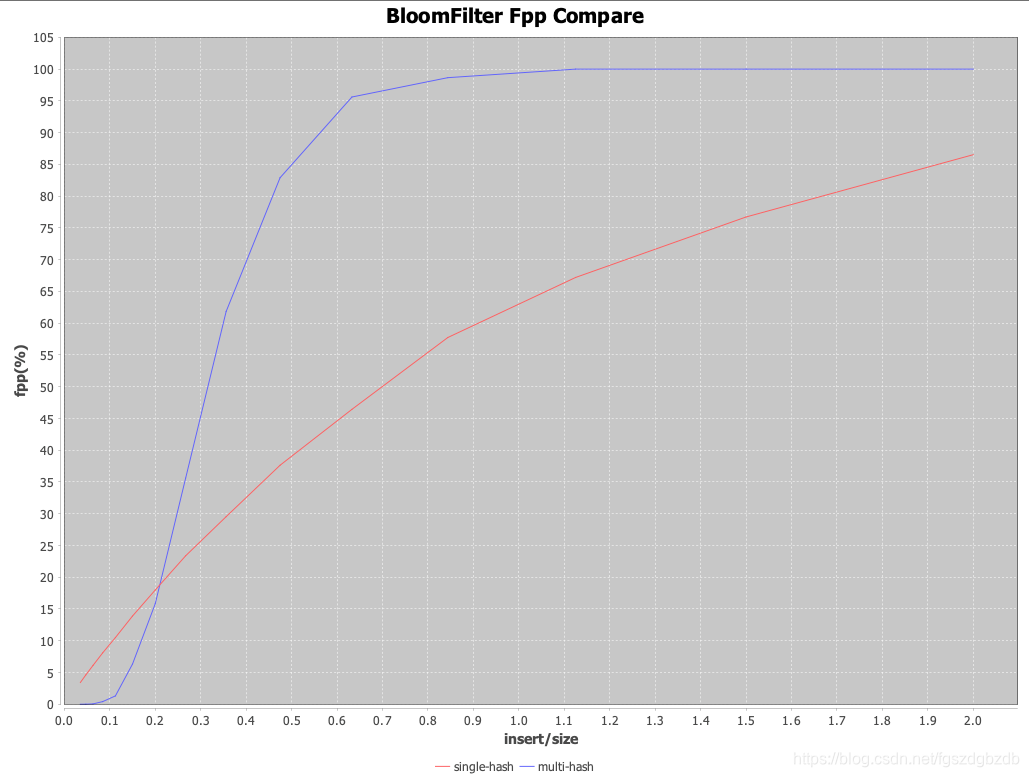
- 定性分析
1. BloomFilter内插入数据占比小的情况下,fpp较低,效果较好;
2. 一旦插入数据占比过高(>20%),fpp 激增。
3. 占比低(<20%)时,multihash fpp 比single hash好,20%以上的占比,multi-hash 出错率陡增
原因是:每次记录一个数据,多处被置为1,过多的1, 会导致fpp
因此,插入数据数量、空间分配数量 以及 fpp 三者之间要有一个权衡
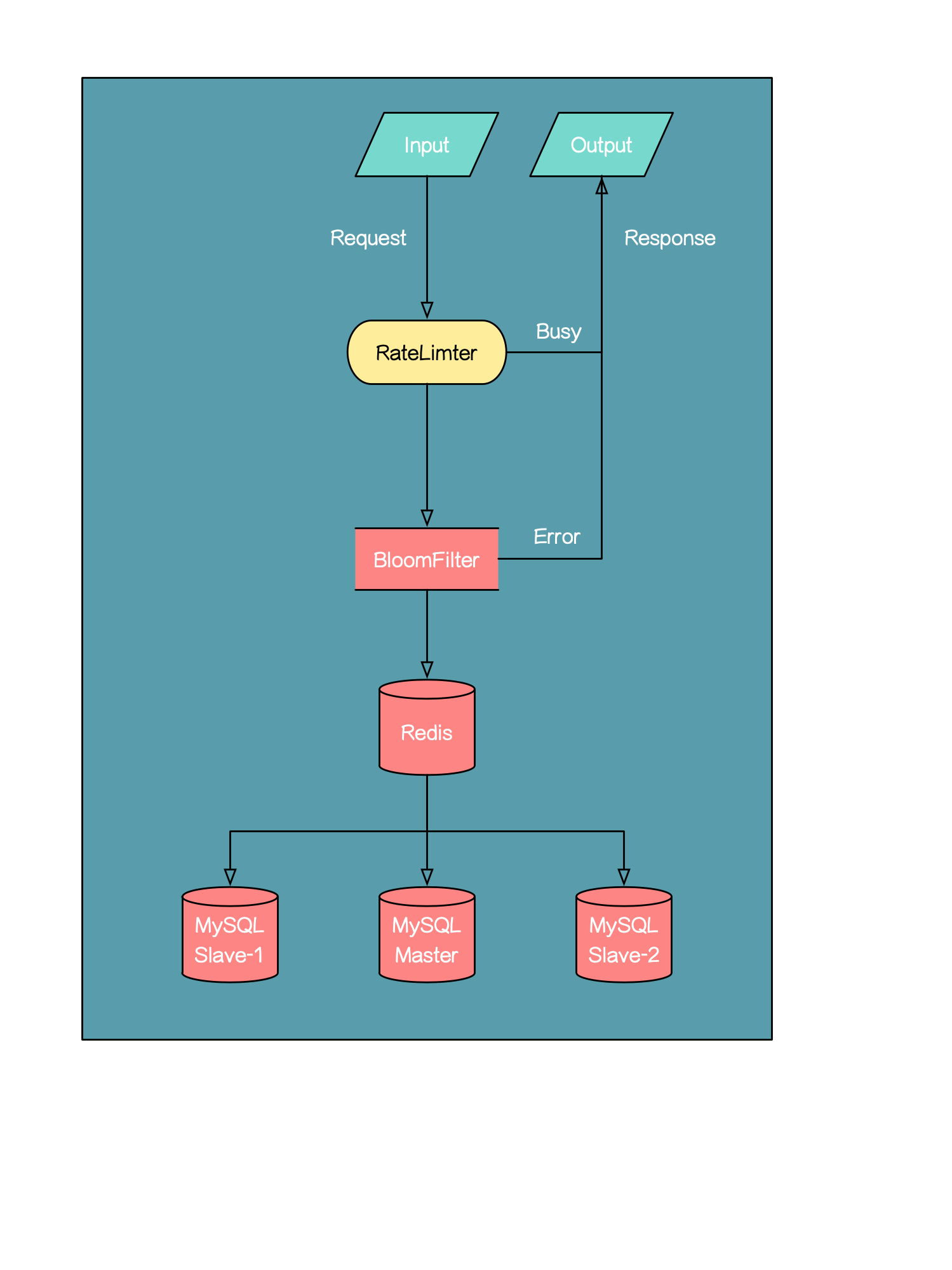
应用
字符串去重复:
- 网络爬虫抓取时URL去重
- 邮件提供商反垃圾黑名单Email地址去重
判断存在性:
- Redis 防止缓存穿透
- 元素是否在一个集合里
Reference
- https://blog.csdn.net/tianyaleixiaowu/article/details/74721877
- https://blog.csdn.net/tianyaleixiaowu/article/details/74739827
- https://blog.csdn.net/woaigaolaoshi/article/details/51283212
- https://blog.csdn.net/tianyaleixiaowu/article/details/74721877
- https://blog.csdn.net/tianyaleixiaowu/article/details/74739827