Qlearning和policygradient学习
Qlearning:
Initialize Q arbitrarily //随机初始化Q值
Repeat (for each episode): //每一次游戏,从小鸟出生到死亡是一个episode
Initialize S //小鸟刚开始飞,S为初始位置的状态
Repeat (for each step of episode):
根据当前Q和位置S,使用一种策略,得到动作A //这个策略可以是ε-greedy等
做了动作A,小鸟到达新的位置S',并获得奖励R //奖励可以是1,50或者-1000
Q(S,A) ← (1-α)*Q(S,A) + α*[R + γ*maxQ(S',a)] //在Q中更新S
S ← S'
until S is terminal //即到小鸟死亡为止
这个更直白

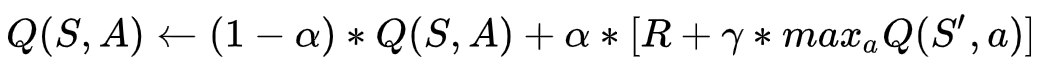
Q是最大未来奖励,从而作为最佳决策矩阵。(根据行状态对应的最大值,选择行为A的最大值。)
S是状态,A是S状态对应的行为。R是当前选择A之后产生的reward。
alpha是学习速率,表示决策更新的程度。
y是一个小于1的参数,代表未来状态的最佳选择(那时候Q最大)对现在的影响。
Q的理解:每一步有自己的reward,然而Q也是S和A都有关系。为获得更多的奖励,我们往往不能只看当前奖励,更要看将来的奖励。从当前时间 t 开始,总的将来的奖励为: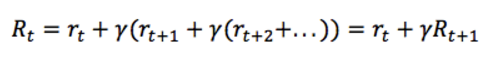
y的意义:Environment 往往是随机的,执行特定的动作不一定得到特定的状态。 γ 等于1,意味着环境是确定的,相同的动作总会获得相同的奖励。
所以说r+y*max(Q(t+1))是新的Q,减去原来的Q,表示更新的差值。
https://blog.csdn.net/itplus/article/details/9361915
介绍policy gradient:
可以在连续的空间选择action.
选出行为->反向传递->奖惩信息决定反向传递的多少。
状态和策略都是有分布的。
- python实现最基本的RL。莫烦教程很好。https://github.com/MorvanZhou/Reinforcement-learning-with-tensorflow/tree/master/contents/7_Policy_gradient_softmax
- 过程:游戏某一个eposide,通过choose_action函数(神经网络,两层)选择出一个action,通过env.step(内定的)输出下一个state,reward。储存状态,不停调用RL模块的choose_action产生新的状态。。。。。到游戏结束的时候,通过learn优化参数。learn是一个optimizer(针对loss的)
好!接下来看lijiwei3的代码
想想要实现哪些功能。
def train():
with tf.Session() as sess:
st_model = create_st_model(sess, gst_config, True, gst_config.name_model)
bk_model = create_st_model(sess, gbk_config, True, gbk_config.name_model)
cc_model = create_st_model(sess, gcc_config, True, gcc_config.name_model)
rl_model = create_rl_model(sess, grl_config, False, grl_config.name_model)
while True:
# Get a batch and make a step.
start_time = time.time()
encoder_inputs, decoder_inputs, target_weights, batch_source_encoder, _ = \
rl_model.get_batch(train_set,bucket_id)
updata, norm, step_loss = rl_model.step_rl(sess, st_model=st_model, bk_model=bk_model, encoder_inputs=encoder_inputs,
decoder_inputs=decoder_inputs, target_weights=target_weights,
batch_source_encoder=batch_source_encoder, bucket_id=bucket_id)
step_time += (time.time() - start_time) / grl_config.steps_per_checkpoint
loss += step_loss / grl_config.steps_per_checkpoint
current_step += 1
```
```
2.
def create_st_model(session, st_config, forward_only, name_scope):
with tf.variable_scope(name_or_scope=name_scope):
st_model = gst_rnn_model.gst_model(gst_config=st_config, name_scope=name_scope, forward_only=forward_only)
ckpt = tf.train.get_checkpoint_state(os.path.join(st_config.train_dir, "checkpoints"))
if ckpt and tf.train.checkpoint_exists(ckpt.model_checkpoint_path):
print("Read %s model from %s" % (name_scope, ckpt.model_checkpoint_path))
st_model.saver.restore(session, ckpt.model_checkpoint_path)
else:
print("Creating %s model with fresh parameters" % name_scope)
global_variables = [gv for gv in tf.global_variables() if name_scope in gv.name]
session.run(tf.variables_initializer(global_variables))
print("Created %s model with fresh parameters" % name_scope)
return st_model
3.
def create_rl_model(session, rl_config, forward_only, name_scope):
with tf.variable_scope(name_or_scope=name_scope):
rl_model = grl_rnn_model.grl_model(grl_config=rl_config, name_scope=name_scope, forward=forward_only)
ckpt = tf.train.get_checkpoint_state(os.path.join(rl_config.train_dir, "checkpoints"))
if ckpt and tf.train.checkpoint_exists(ckpt.model_checkpoint_path):
print("Read %s model from %s" % (name_scope, ckpt.model_checkpoint_path))
rl_model.saver.restore(session, ckpt.model_checkpoint_path)
else:
print("Creating %s model with fresh parameters" % name_scope)
global_variables = [gv for gv in tf.global_variables() if name_scope in gv.name]
session.run(tf.variables_initializer(global_variables))
print("Created %s model with fresh parameters" % name_scope)
return rl_model
create_st_model和create_rl_model实现功能:
就是字面意思的create了相关的model,所以重要的只有两个model,gst_model和grl_model.
grl_model又从grl_seq2seq来,不是很明白为什么要改。
def _extract_argmax_and_embed(embedding, output_projection=None, update_embedding=True):
def loop_function(prev, _):
def rnn_decoder(decoder_inputs, initial_state, cell, loop_function=None,
scope=None):
def beam_rnn_decoder
def embedding_rnn_decoder
def embedding_rnn_seq2seq
def attention_decoder
def embedding_attention_decoder
def embedding_attention_seq2seq
def decoder
def sequence_loss_by_example
def sequence_loss
def model_with_buckets
def decode_model_with_buckets
12.11
所以rl用于seq2seq&&传统的seq2seq没有太大区别,不过是在更新的时候theta的梯度变化了。是为了max(R)。