本文将详细讲解Hulu在NIPS 2018 会议上发表的《Fast Greedy MAP Inference for Determinantal Point Process to Improve Recommendation Diversity》中,提出的基于行列式点过程的推荐多样性提升算法。

引言
随着机器学习技术日益成熟,机器学习的应用领域也越来越广。其中,推荐领域是机器学习一个比较常见且成功的应用场景。推荐多样性和相关性是衡量推荐算法常用的标准,最近项目团队针对搜索多样性做了大量的研究工作。Hulu陈拉明的推荐算法研究团队在NIPS 2018会议上提出的基于DPP的推荐多样性算法,能较好地提高推荐的多样性和相关性,并且执行效率也十分可观。我们团队也复现了该算法,具有不错的上线效果。
DPP 的构造
行列式点过程(Determinantal Point Process, DPP)是一种性能较高的概率模型。DPP将复杂的概率计算转换成简单的行列式计算,并通过核矩阵的行列式计算每一个子集的概率。DPP不仅减少了计算量,而且提高了运行效率,在图片分割、文本摘要和商品推荐系统中均具有较成功的应用。
DPP通过最大后验概率估计,找到商品集中相关性和多样性最大的子集,从而作为推荐给用户的商品集。
行列式点过程刻画的是一个离散集合
中每一个子集出现的概率。当
给定空集合出现的概率时,存在一个由集合
的元素构成的半正定矩阵
,对于每一个集合
的子集
,使得子集
出现的概率
,其中,
表示由行和列的下标属于
构成的矩阵
的子矩阵。
为了更好地理解行列式点过程的定义,下面给出陈拉明在某次讲座中陈述的例子。
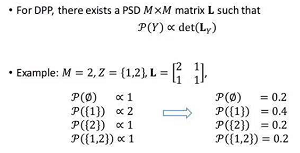
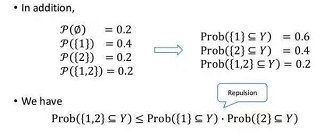
由于矩阵是半正定的,因此存在矩阵
,使得
,并且
这是因为行列式为方阵中的各个列向量张成的平行多面体体积的平方。
为了将DPP模型应用于推荐场景中,考虑将每个列向量分解为
,其中:
为item i与user之间的相关性,且
;
为item i 与 item j之间的相似度度量,且
;
那么,
从矩阵的构造可知,商品与用户之间相关性越大,且商品之间多样性越丰富,则矩阵
的行列式越大。因此,我们可以建立如下最优化问题:
但是,直接求解该优化问题是NP难的,陈拉明团队则利用贪婪算法,提出了一种能加速行列式点过程推理过程的方法。
首先,DPP取Log后的函数是满足次模函数的:
次模函数是一个集合函数,随着输入集合中元素的增加,增加单个元素到输入集合导致的函数增量的差异减小。
即,对于任意,
直观解释为,小集合和大集合增加同样一个元素,小集合带来的收益大于大集合的收益。
因此,可以将上述优化问题转化为贪婪的形式:
,
即,每次选择收益最大的item,直到满足条件为止。
DPP模型求解
求解该优化问题时,每次迭代的计算复杂度来源于行列式的计算,而求行列式的计算复杂度与该行列式长度的三次方成正比,即,这一结果显然不适用于实际线上实时性较高的场景。下面,叙述论文中所做的改进:
首先对子矩阵做Cholesky分解,使得
其中,是一个下三角矩阵。对于任意
,对子集
添加一个元素
之后的子矩阵做Cholesky分解,使得
其中,有以下等式成立
,
两边取行列式后再取log,可得:
应用Cholesky分解后,每次迭代只需要计算即可。而为了得到
,先需要求解线性方程组:
求解得到后,再带入
得到
。此过程的计算复杂度来源于求解线性方程组,虽然求解线性方程组的计算复杂度也是三次方,但是系数矩阵
是下三角矩阵,因此,每次迭代的计算复杂度可降到二次方。
即使计算复杂度降到了二次方,但是相比于目前主流的算法,可能依然没有优势。因此,作者又考虑每次迭代也用增量的方式更新和
,从而避免了求解线性方程组带来的计算复杂度。具体过程如下:
对于任意
,
将带入上式中,推导可得:
因此,每次迭代的计算复杂度进一步降低至一次方。

滑动窗口式多样性
在一些场景中,商品集是以一个长序列的形式展示的,每次仅展示其中一部分。其实,这和搜索展示十分类似。此时,多样性仅需要在当前的滑动窗口满足即可。定义是窗口的大小,对应的优化模型为:
其中,包含最近添加的
个商品。

总结
基于行列式点过程的推荐多样性提升算法使用贪婪算法推理最优的行列式点过程,并利用Cholesky加速行列式点过程的推理。该算法在推荐领域具有较好的应用,在丰富推荐多样性和相关性的同时,大大提升了计算速度。