一、文章概念描述
分布式缓存描述:
分布式缓存重点是在分布式上,相信大家接触过的分布式有很多中,像分布式开发,分布式部署,分布式锁、事物、系统 等有很多。使我们对分布式本身就有一个很明确的认识,分布式就是有多个应用程序组成,可能分布在不同的服务器上,最终都是在为web端提供服务。
分布式缓存有以下几点优点:
- 所有的Web服务器上的缓存数据都是相同的,不会因为应用程序不同,服务器的不同导致缓存数据的不一样。
- 缓存的是独立的不受Web服务器的重新启动或被删除添加的影响,也就是说这些Web的改变不到导致缓存数据的改变。
传统的单体应用架构因为用户的访问量的不高,缓存的存在大多数都是存储用户的信息,以及一些页面,大多数的操作都是直接和DB进行读写交互,这种架构简单,也称为简单架构,
传统的OA项目比如ERP,SCM,CRM等系统因为用户量不大也是因为大多数公司业务的原因,单体应用架构还是很常用的架构,但是有些系统随着用户量的增加,业务的扩张扩展,导致DB的瓶颈的出现。
以下我所了解到的关于这种情况的处理有以下两种
(1):当用户访问量不大,但是读写的数据量很大的时候,我们一般采取的是,对DB进行读写分离、一主多从、对硬件进行升级的方式来解决DB瓶颈的问题。
这样的缺点也同样纯在:
1、用户量大的时候怎么办?,
2、对于性能的提升有限,
3、性价比不高。提升一点性能就需要花费很多代价,(打个比方,现在的I/O吞吐量是0.9的需要提升到1.0,我们在增加机器配置的情况下这个价格确实很可观的)
(2):当用户访问量也增加的时候,我们就需要引入缓存了来解决了,一张图描述缓存的大致的作用。
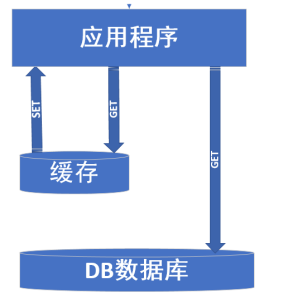
缓存主要针对的是不经常发生改变的并且访问量很大的数据,DB数据库可以理解为只作为数据固化的或者只用来读取经常发生改变的数据,上图中我没有画SET的操作,就是想特意说明一下,缓存的存在可以作为一个临时的数据库,我们可以通过定时的任务的方式去同步缓存和数据库中的数据,这样做的好处是可以转移数据库的压力到缓存中。
缓存的出现解决了数据库压力的问题,但是当以下情况发生的时候,缓存就不在起到作用了,缓存穿透、缓存击穿、缓存雪崩这三种情况。
缓存穿透:我们的程序中用缓存的时候一般采取的是先去缓存中查询我们想要的缓存数据,如果缓存中不存在我们想要的数据的话,缓存就失去了做用(缓存失效)我们就是需要伸手向DB库去要数据,这个时候这种动作过多数据库就崩溃了,这种情况需要我们去预防了。比如说:我们向缓存获取一个用户信息,但是故意去输入一个缓存中不存在的用户信息,这样就避过了缓存,把压力重新转移到数据上面了。对于这种问题我们可以采取,把第一次访问的数据进行缓存,因为缓存查不到用户信息,数据库也查询不到用户信息,这个时候避免重复的访问我们把这个请求缓存起来,把压力重新转向缓存中,有人会有疑问了,当访问的参数有上万个都是不重复的参数并且都是可以躲避缓存的怎么办,我们同样把数据存起来设置一个较短过期时间清理缓存。
缓存击穿:事情是这样的,对于一些设置了过期时间的缓存KEY,在过期的时候,程序被高并发的访问了(缓存失效),这个时候使用互斥锁来解决问题,
互斥锁原理:通俗的描述就是,一万个用户访问了,但是只有一个用户可以拿到访问数据库的权限,当这个用户拿到这个权限之后重新创建缓存,这个时候剩下的访问者因为没有拿到权限,就原地等待着去访问缓存。
永不过期:有人就会想了,我不设置过期时间不就行了吗?可以,但是这样做也是有缺点的,我们需要定期的取更新缓存,这个时候缓存中的数据比较延迟。
缓存雪崩:是指多种缓存设置了同一时间过期,这个时候大批量的数据访问来了,(缓存失效)数据库DB的压力又上来了。解决方法在设置过期时间的时候在过期时间的基础上增加一个随机数尽可能的保证缓存不会大面积的同事失效。
项目准备
1、首先安装Redis缓存,可以参考这里
2、然后下载安装:客户端工具:RedisDesktopManager(方便管理)
3、在我们的项目Nuget中 引用 Microsoft.Extensions.Caching.Redis
然后我们新建一个ASP.NET Core MVC项目,在