Map(没有迭代器):
要保证Map集合中键的唯一性。
问:ArrayList 和 HashMap 的默认大小是多数?
答:
ArrayList、Vector默认初始容量为10。
Vector:加载因子为1,如 Vector的容量为10,一次扩容后是容量为20。
ArrayList:扩容增量:原容量的 0.5倍+1,如 ArrayList的容量为10,一次扩容后是容量为16。
HashSet和HashMap默认初始容量为16(为何是16:16是2^4,可以提高查询效率)
加载因子为0.75:即当元素个数超过容量长度的0.75倍 时,进行扩容
扩容增量:原容量的1倍
如 HashSet的容量为16,一次扩容后是容量为32。
HashMap是通过"拉链法"实现的哈希表。它包括几个重要的成员变量:
table是一个Entry[]数组类型,而Entry实际上就是一个单向链表。哈希表的"key-value键值对"都是存储在Entry数组中的。 size是HashMap的大小,它是HashMap保存的键值对的数量。 threshold是HashMap的阈值,用于判断是否需要调整HashMap的容量。 threshold的值="容量*加载因子",当HashMap中存储数据的数量达到threshold时,就需要将HashMap的容量加倍。 loadFactor就是加载因子。 modCount是用来实现fail-fast机制的。
问:HashMap的工作原理是什么?内部的数据结构是什么?
答:
HashMap基于hashing原理,我们通过put()和get()方法储存和获取对象。当我们将键值对传递给put()方法时,它调用键对象的hashCode()方法来计算hashcode,然后找到bucket位置来储存值对象。当获取对象时,通过键对象的equals()方法找到正确的键值对,然后返回值对象。HashMap使用链表来解决碰撞问题,当发生碰撞了,对象将会储存在链表的下一个节点中。HashMap在每个链表节点中储存键值对对象。
当两个不同的键对象的hashcode相同时会发生什么? 它们会储存在同一个bucket位置的链表中。键对象的equals()方法用来找到键值对。
HashMap采取数组加链表的存储方式来实现。亦即数组(散列桶)中的每一个元素都是链表,如下图:
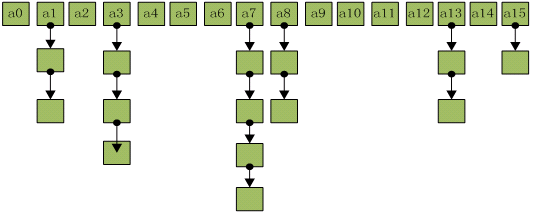
参考:HashMap的扩容
问:两个hashcode相同 的对象怎么存入hashmap的
HashMap的遍历方式:
1.遍历HashMap的键值对
根据entrySet()获取HashMap的“键值对”的Set集合。
通过Iterator迭代器遍历“第一步”得到的集合。
// 假设map是HashMap对象 // map中的key是String类型,value是Integer类型 Integer integ = null; Iterator iter = map.entrySet().iterator(); while(iter.hasNext()) { Map.Entry entry = (Map.Entry)iter.next(); // 获取key key = (String)entry.getKey(); // 获取value integ = (Integer)entry.getValue(); }
2.遍历HashMap的键
根据keySet()获取HashMap的“键”的Set集合。
通过Iterator迭代器遍历“第一步”得到的集合。
// 假设map是HashMap对象 // map中的key是String类型,value是Integer类型 String key = null; Integer integ = null; Iterator iter = map.keySet().iterator(); while (iter.hasNext()) { // 获取key key = (String)iter.next(); // 根据key,获取value integ = (Integer)map.get(key); }
3. 遍历HashMap的值
根据value()获取HashMap的“值”的集合。
通过Iterator迭代器遍历“第一步”得到的集合。
// 假设map是HashMap对象 // map中的key是String类型,value是Integer类型 Integer value = null; Collection c = map.values(); Iterator iter= c.iterator(); while (iter.hasNext()) { value = (Integer)iter.next(); }
例子1:
public class Test1 { /*分析以下需求,并用代码实现: (1)有类似这样的字符串:"1.2,3.4,5.6,7.8,5.56,44.55"请按照要求,依次完成以下试题 (2)以逗号作为分隔符,把已知的字符串分成一个String类型的数组,数组中的每一个元素类似于"1.2","3.4"这样的字符串 (3)把数组中的每一个元素以"."作为分隔符,把"."左边的元素作为key,右边的元素作为value,封装到Map中,Map中的key和value都是Object类型 (注意, 这里有5.6与5.56两个数字, 这样切分出来后会有两个相同的key, 值都为5, 思考一下,这里应该怎么做才能将这两个key都保留???) (4)把map中的key封装在Set中,并把Set中的元素输出 (5)把map中的value封装到Collection中,把Collection中的元素输出 */ public static void main(String[] args) { String s="1.2,3.4,5.6,7.8,5.56,44.55"; String[] arr = s.split(","); HashMap<Object,Object>hm=new HashMap<>(); for (int i = 0; i < arr.length; i++) { String[]arr2=arr[i].split("\\.");//把每个字符串的.切掉 if(arr2[0].equals("5")){ hm.put(!hm.containsKey("5") ? arr2[0] : Integer.parseInt(arr2[0]), arr2[1]); //之所以定为Object类型就是为了这里 把两个"5"一个存储String类型 一个存储Integer类型 }else { hm.put(arr2[0], arr2[1]); } } Set<Object> keySet = hm.keySet(); System.out.println(keySet); Collection<Object> value = hm.values(); System.out.println(value); } }
TreeMap用比较器,要想直接存入重复的键的话,只能通过entrySet()方法,keySet()方法不行,
因为它的getkey()方法底层依靠的是compareTo来确定如何获取键值的。
例子2:
//键唯一性问题 public class Test02 { // 所谓的Map集合中键要保持唯一性 针对的就是keySet()这个方法 // 而entrySet()获取的是键值对对象 绕过了这个限制 public static void main(String[] args) { TreeMap<String, Integer> ts = new TreeMap<>(new Comparator<String>() { @Override public int compare(String s1, String s2) { int num = s1.compareTo(s2); return num == 0 ? 1 : num; } }); ts.put("a", 1); ts.put("b", 2); ts.put("c", 3); ts.put("c", 3); /* * Set<String> keySet = ts.keySet(); Iterator<String>it=keySet.iterator(); while(it.hasNext()){ String key=it.next(); System.out.println(key+"="+ts.get(key)); */ // 这里不能用keySet只能用entrySet // 因为keySet里面的getkey()方法底层是根据ComparaTo来确定如何获取键值的 Set<Entry<String, Integer>> entrySet = ts.entrySet(); Iterator<Entry<String, Integer>> it = entrySet.iterator(); while (it.hasNext()) { Entry<String, Integer> en = it.next(); String key = en.getKey(); Integer value = en.getValue(); System.out.println(key + "=" + value); } } }
补充:存储重复键
1.IdentityHashMap(可以存储重复键的集合 用法罕见),在IdentityHashMap中,是判断key是否为同一个对象,而不是普通HashMap的equals方式判断。
IdentityHashMap类利用哈希表实现Map接口,比较键(和值)时使用引用相等性代替对象相等性。该类不是通用 Map 实现!
2.HashMap也可以存储重复建(数字),不过只针对两个键,一个用String类型存入,一个用Integer存入-->局限性很大。
问:set和map的区别?
答:
map可以存储重复键,set不可以。
问:HashMap和Hashtable有什么区别?
答:不同点:
1.HashMap允许键和值是null,而Hashtable不允许键或者值是null。 2.Hashtable是同步的,而HashMap不是。因此,HashMap更适合于单线程环境,而Hashtable适合于多线程环境。 3.HashMap提供了可供应用迭代的键的集合,因此,HashMap是快速失败的。另一方面,Hashtable提供了对键的列举(Enumeration)。
问:快速失败(fail-fast)和安全失败(fail-safe)的区别是什么?
答:
Iterator的安全失败是基于对底层集合做拷贝,因此,它不受源集合上修改的影响。
java.util包下面的所有的集合类都是快速失败的,而java.util.concurrent包下面的所有的类都是安全失败的。
快速失败的迭代器会抛出ConcurrentModificationException异常,而安全失败的迭代器永远不会抛出这样的异常。
问:简述一致性 Hash 算法
答:
一致性哈希修正了CARP使用的简单哈希算法带来的问题,在分布式系统中也得到了广泛应用。
一致性hash算法(DHT)通过减少影响范围的方式解决了增减服务器导致的数据散列问题,从而解决了分布式环境下负载均衡问题,如果存在热点数据,那么通过增添节点的方式,对热点区间进行划分,将压力分配至其他服务器。重新达到负载均衡的状态。
同步容器类 ConcurrentHashMap锁分段机制:

默认提高16倍效率。Jdk1.8后把ConcurrentHashMap底层的锁分段改为CAS算法了。