文章目录
log日志
最近小咸儿一直在潜心学习,发现很多有感日志的配置不是很懂,所以特地查询了一些资料学习一下,然后总结下来。
主要参考材料:https://www.cnblogs.com/leecong/p/5776970.html
首先小咸儿最近接触的项目是spring cloud的框架,所以也特地去看看了自己项目中日志的配置。
logback是如何加载配置的呢?
1、logback会先去查找logback.groovy文件
2、如果没有找到的话,会继续查找logback-test.xml文件
3、如果没有找到logback-test.xml文件,继续查找logback.xml文件
4、还没有找到的话,就会使用默认配置(打印到控制台了)
configuration:
configuration是配置文件的根节点,它包含的属性:
- Scan
当此属性设置为true时,配置文件如果发生改变,将会被重新加载。默认为true时 - scanPeriod
设置监测配置文件是否有修改的时间间隔,如果没有给出时间单位,默认单位是毫秒。但scan为true时,此属性生效,默认的时间间隔为1分钟 - Debug
当此属性设置为true时,将打印出logback内部日志信息,实时查看logback运行状态,默认值为false

Appender
appender是负责写日志的组件,常用的组件有:
- Encoder:对日志进行格式化
- Target:System.out或者System.err,默认是System.out
小咸儿在自己项目里找了找设置,发现没有有关ConsoleAppender这个节点,但是发现了一些其他有意思的事情,那就是p6spy

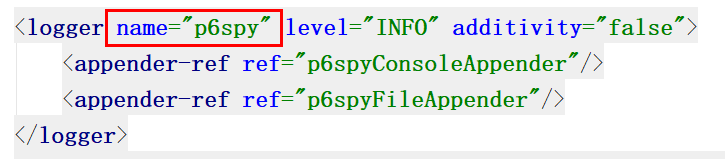
小咸儿百度之后才知道:
P6Spy 是针对数据库访问操作的动态监测框架(为开源项目,项目首页:www.p6spy.com)它使得数据库数据可无缝截取和操纵,而不必对现有应用程序的代码作任何修改。P6Spy 分发包包括P6Log,它是一个可记录任何 Java 应用程序的所有JDBC事务的应用程序。其配置完成使用时,可以进行数据访问性能的监测。
可以看出来它的功能真的是很强大啊!
在这里遇到,也是表明它具体标签的作用:
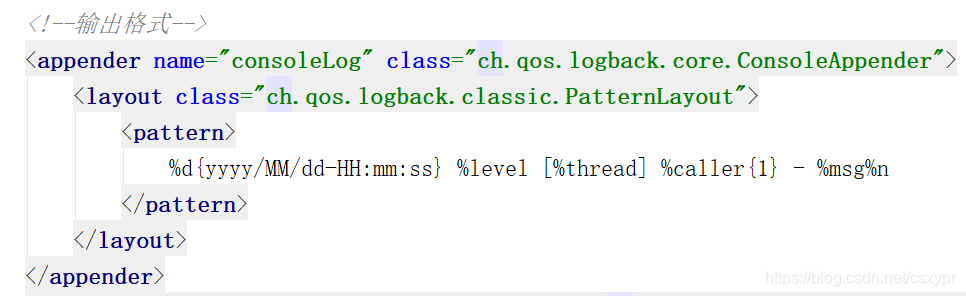
输出格式:
输出info文件并且过滤掉error日志:
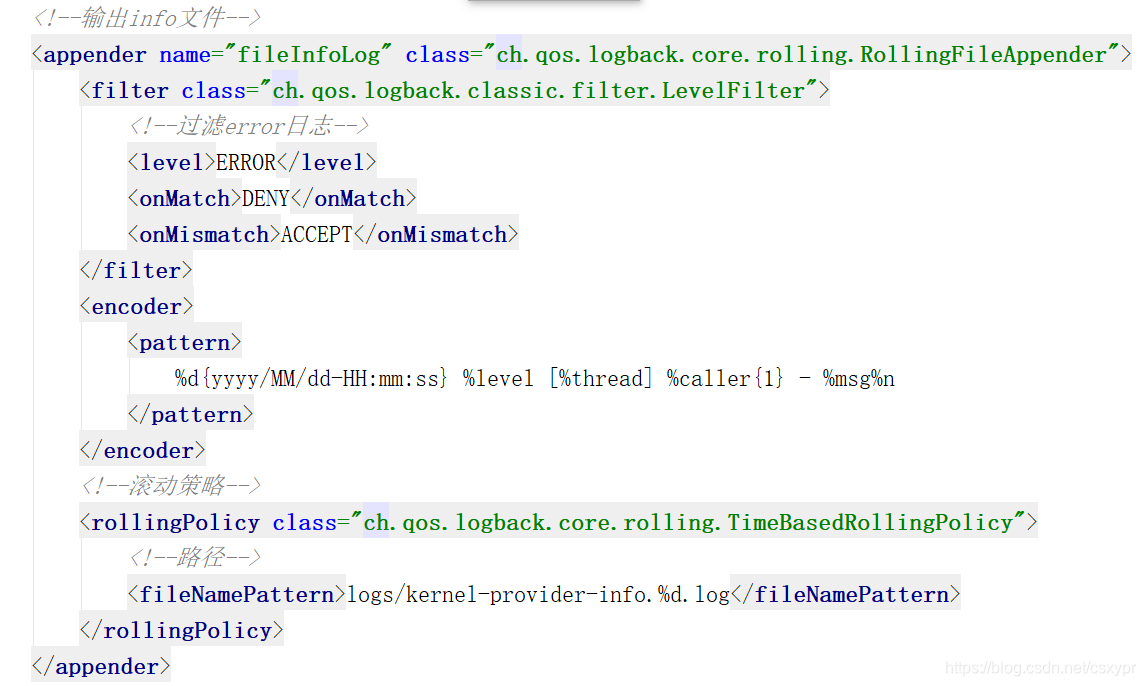
在这里又认识到了几个新的节点,但是还有其他的节点也顺便认识一下吧!
FileAppender
在这里又认识到了几个新的节点,但是还有其他的节点也顺便认识一下吧!
- file:被写入的文件名,可以是相对路径,也可以是绝对路径。如果上级目录不存在会自动创建,没有默认值
- append:如果是true,日志被追加到文件结尾;如果是false,清空现存文件,默认是true
- encoder:格式化
- v prudent:如果是true,日志会被安全的写入文件,即使其他的FileAppender也在向此文件做写入操作,效率低,默认是false
RollingFileAppender
滚动记录文件日志组件,先将日志记录记录到指定文件,当符合某个条件时,将日志记录到其他文件,该组件有一下节点:
- file:文件名
- encoder:格式化
- rollingPolicy:当发生滚动时,决定RollingFileAppender的行为,涉及文件移动和重命名
- triggeringPolicy:告知RollingFileAppender合适激活滚动
- prudent:当为true时,不支持FixedWindowRollingPolicy。支持TimeBasedRollingPolicy,但是有两个限制,一是不支持也不允许文件压缩,二是不能设置file属性,必须留空
rollingPolicy(滚动策略)
-
TimeBasedRollingPolicy:最常用的滚动策略,它根据时间来制定滚动策略,即负责滚动也负责触发滚动,包含节点:
- fileNamePattern:文件名模式
- maxHirouy:控制文件的最大数量,超过数量则删除旧文件
-
FixedWindowRollingPolicy:根据固定窗口算法重命名文件的滚动策略,包含节点:
- minIndex:窗口索引最小值
- maxIndex:串口索引最大值,当用户指定的窗口过大时,会自动将窗口设置为12
- fileNamePattern:文件名模式,必须包含%i,命令模式为log%i.log,会产生log1.log,log2.log这样的文件
-
triggeringPolicy:根据文件大小的滚动策略,包含节点:
- maxFileSize:日志文件最大的大小

- maxFileSize:日志文件最大的大小
filter过滤器
过滤器是用于日志组件中的,每经过一个过滤器都会返回一个确切的枚举值,分别是
- DENY:返回DENY,日志将立即被抛弃不再经过其他过滤器
- NEUTRAL:有序列表的下个过滤器接着处理日志
- ACCEPT:日志会被立即处理,不再经过剩余过滤器
常用过滤器
常用的过滤器有以下:
-
LevelFilter
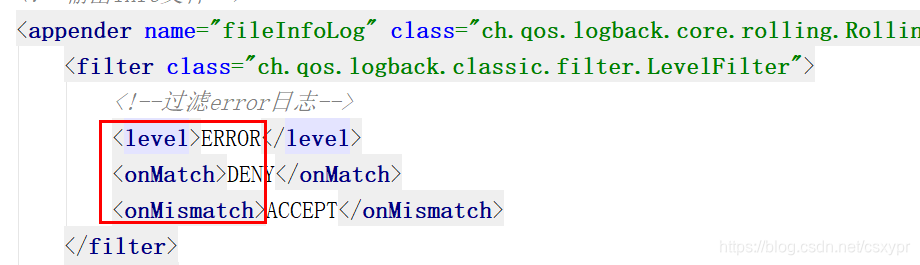
级别过滤器,根据日志级别进行过滤。如果日志级别等于配置级别,过滤器会根据omMatch和omMismatch接受或拒绝日志。他有以下节点:- level:过滤级别
- onMatch:配置符合过滤条件的操作条件
- onMismatch:配置不符合过滤条件的操作
目前小咸儿项目中使用就是levelFileter过滤器:
接下来的两种都是小咸儿第一次见,所以特地总结下来。
-
ThresholdFilter
临界值过滤器,过滤掉低于指定临界值的日志。当日志级别等于或高于临界值时,过滤器会返回NEUTRAL;当日志级别低于临界值时,日志会被拒绝。 -
EvaluatorFilter
求值过滤器,评估、鉴别日志是否符合指定条件,包含节点:- evaluator:鉴别器,通过子标签expression配置求值条件
- onMatch:配置符合过滤条件的操作
- onMismatch:配置不符合过滤条件的操作
日志在小咸儿做项目的时候真的感觉十分重要,因为日志配置的不同,对于开发人员来说,能够轻松的将自己需要的东西,明确的打印出来也能够提高开发效率。