flask连接数据库,就不得不提flak_sqlalchemy 这个扩展,这个扩展采用orm 机制(关系对象映射)连接数据,使得我们操作数据库(增删改查)不在写SQL语句,只需调用方法即可。看到前面的orm 不知是否勾起了你的回忆,这东西是如何做的呢?还记得超类 type 吗?若是遗忘了,该看看之前的笔记了。
文章目录
一、ORM
关系对象映射:
关系指的是数据库,对象指的是我们定义的类或创建的对象,映射:数据库字段和对象属性的映射。

优点:
①只需要面向对象编程, 不需要面向数据库编写代码.
- 对数据库的操作都转化成对类属性和方法的操作.
- 不用编写各种数据库的sql语句.
②实现了数据模型与数据库的解耦, 屏蔽了不同数据库操作上的差异.
- 不在关注用的是mysql、oracle…等.
- 通过简单的配置就可以轻松更换数据库, 而不需要修改代码.
缺点:
- 相比较直接使用SQL语句操作数据库,有性能损失.
- 根据对象的操作转换成SQL语句,根据查询的结果转化成对象, 在映射过程中有性能损失.
二、Flask-SQLAlchemy 安装与配置
1、安装
对于安装就不需要多言了,直接使用pip安装。
pip install flask-sqlalchemy
我接下来要使用mysql数据库,还需安装:
pip install flask-mysqldb
2、数据库连接配置
一下是数据库配置的可配置项(SQLAlchemy 类中)
app.config.setdefault('SQLALCHEMY_DATABASE_URI', 'sqlite:///:memory:')
app.config.setdefault('SQLALCHEMY_BINDS', None)
app.config.setdefault('SQLALCHEMY_NATIVE_UNICODE', None)
app.config.setdefault('SQLALCHEMY_ECHO', False)
app.config.setdefault('SQLALCHEMY_RECORD_QUERIES', None)
app.config.setdefault('SQLALCHEMY_POOL_SIZE', None)
app.config.setdefault('SQLALCHEMY_POOL_TIMEOUT', None)
app.config.setdefault('SQLALCHEMY_POOL_RECYCLE', None)
app.config.setdefault('SQLALCHEMY_MAX_OVERFLOW', None)
app.config.setdefault('SQLALCHEMY_COMMIT_ON_TEARDOWN', False)
track_modifications = app.config.setdefault(
'SQLALCHEMY_TRACK_MODIFICATIONS', None
)
查看SQLalchemy源码的方法如图:跳转的快捷键(ctrl+鼠标左键)
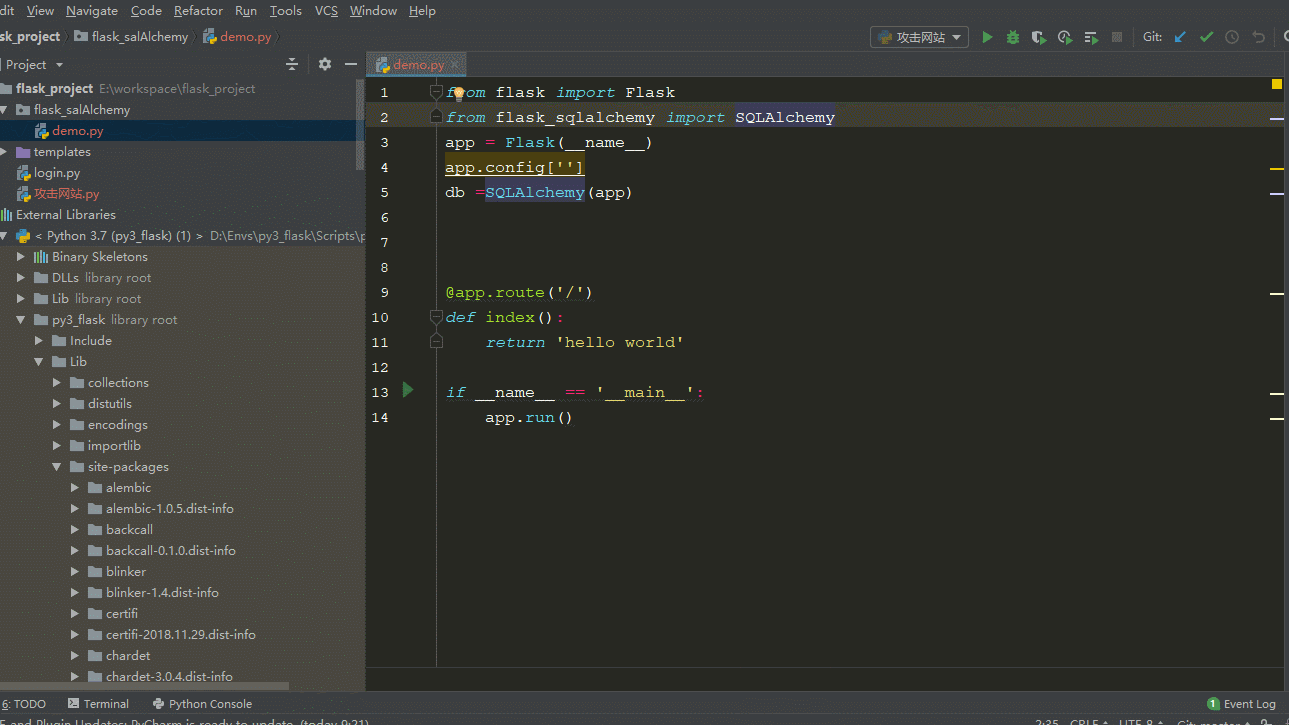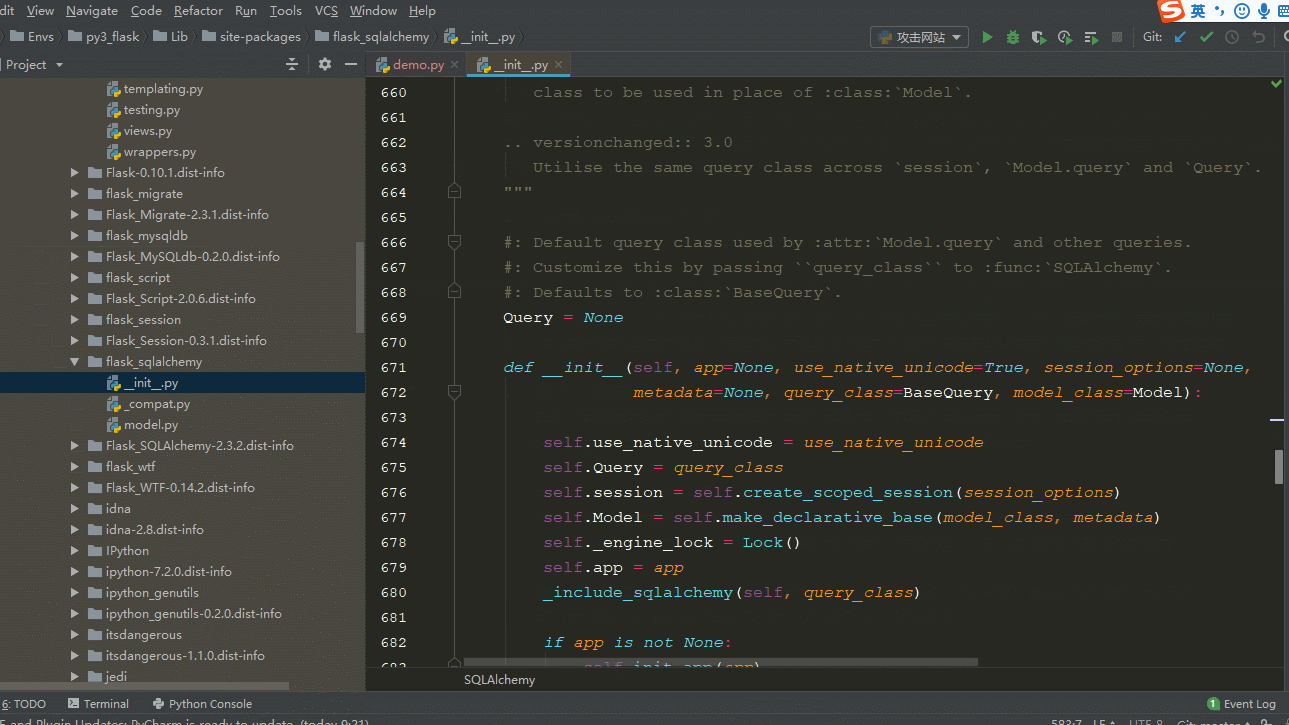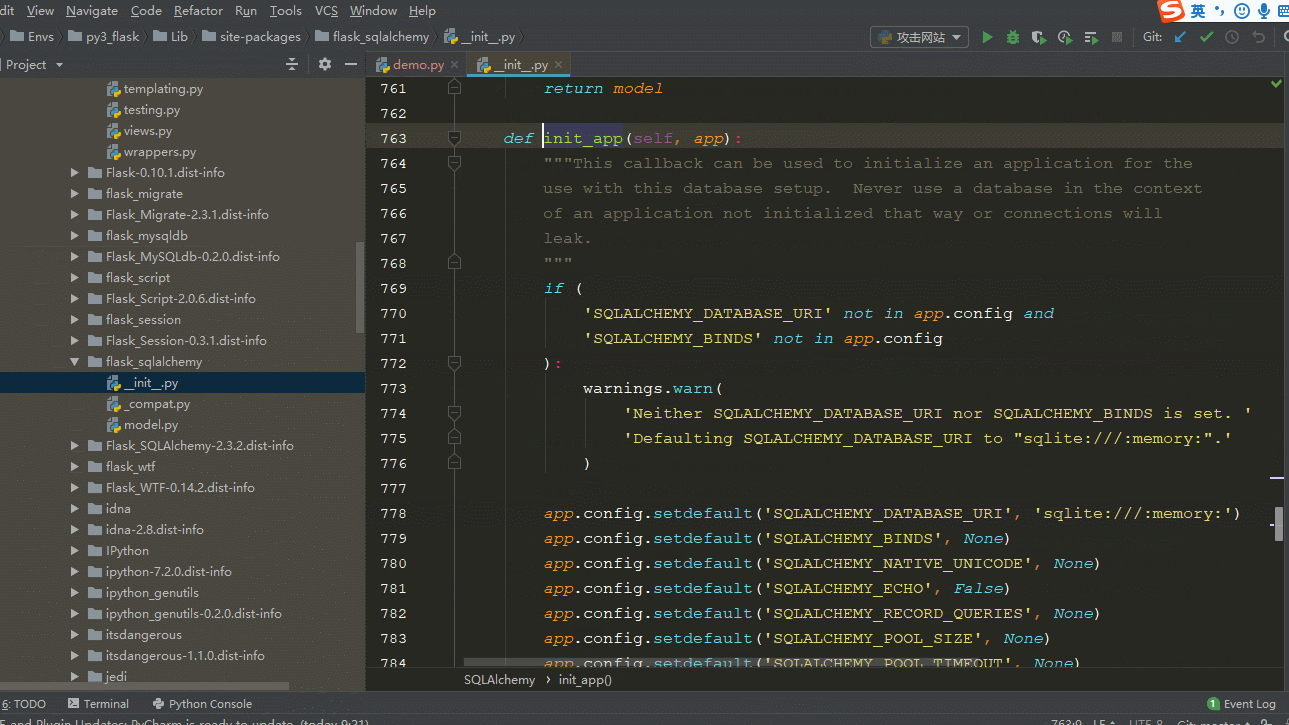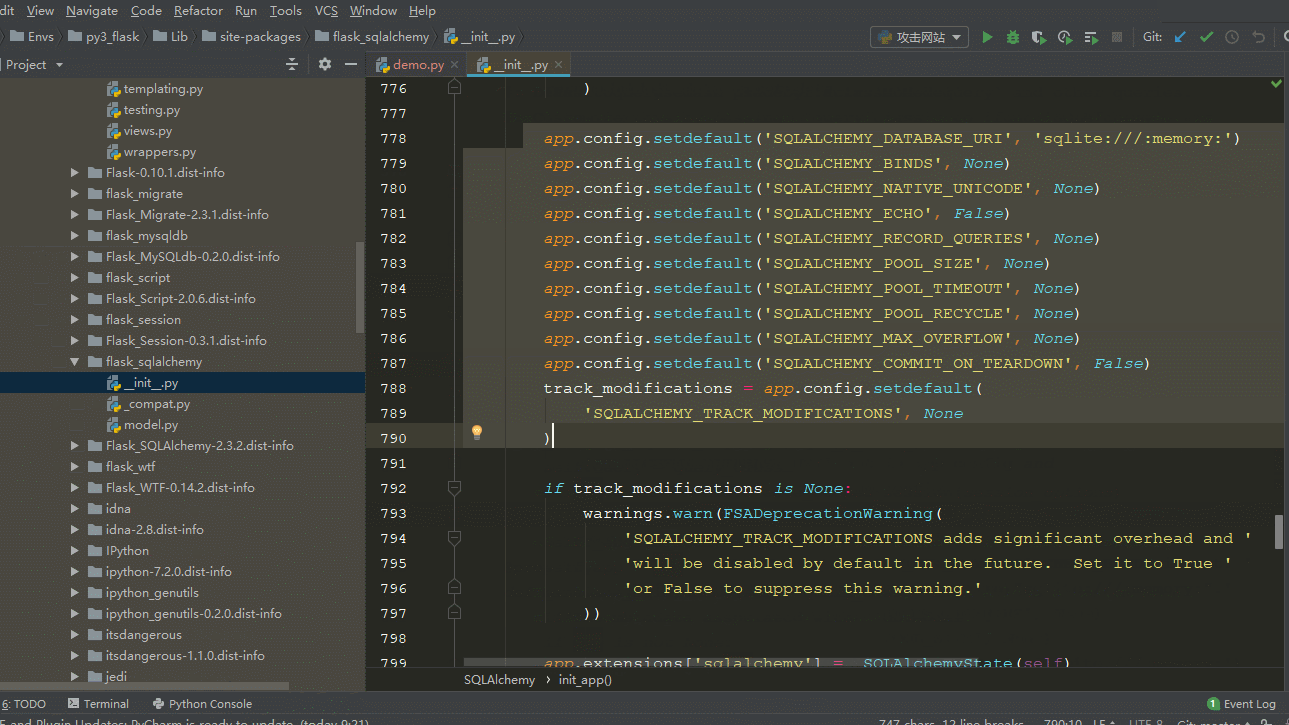
根据上面我们知道配置必须在初始化SQLAlchemy之前,而且是给flask应用配置,还记得flask 的配置方法吗?
讲解几个常用的配置:
- 连接数据库:
# 配置数据库URL,指定连接哪个数据库
# key: SQLALCHEMY_DATABASE_URI
# value格式(大部分数据库): 数据库类型://用户名:密码@ip:端口号/数据库名
app.config["SQLALCHEMY_DATABASE_URI"] = "mysql://root:[email protected]:3306/flask_test"
注意:这里使用的数据库必须先创建好。
连接其他数据库的字符串(value):
| 数据库类型 | 配置 |
|---|---|
| Postgres | postgresql://scott:tiger@localhost/mydatabase |
| MySQL | mysql://scott:tiger@localhost/mydatabase |
| Oracle | oracle://scott:[email protected]:1521/sidname |
| SQLite | sqlite:////absolute/path/to/foo.db (注意开头的四个斜线) |
- 显示原始SQL语句
#查询时会显示原始SQL语句
app.config['SQLALCHEMY_ECHO'] = True
- 追踪数据库
# 动态追踪修改设置,如未设置只会提示警告
app.config['SQLALCHEMY_TRACK_MODIFICATIONS'] = True
- 数据库修改自动提交
# 是否自动提交,不用自己调用 commit()
app.config['SQLALCHEMY_COMMIT_ON_TEARDOWN'] = True
- 其他配置
| 名字 | 备注 |
|---|---|
| SQLALCHEMY_BINDS | 一个映射 binds 到连接 URI 的字典。更多 binds 的信息见用 Binds 操作多个数据库。 |
| SQLALCHEMY_RECORD_QUERIES | 可以用于显式地禁用或启用查询记录。查询记录 在调试或测试模式自动启用。更多信息见get_debug_queries()。 |
| SQLALCHEMY_NATIVE_UNICODE | 可以用于显式禁用原生 unicode 支持。当使用 不合适的指定无编码的数据库默认值时,这对于 一些数据库适配器是必须的(比如 Ubuntu 上 某些版本的 PostgreSQL )。 |
| SQLALCHEMY_POOL_SIZE | 数据库连接池的大小。默认是引擎默认值(通常 是 5 ) |
| SQLALCHEMY_POOL_TIMEOUT | 设定连接池的连接超时时间。默认是 10 。 |
| SQLALCHEMY_POOL_RECYCLE | 多少秒后自动回收连接。这对 MySQL 是必要的, 它默认移除闲置多于 8 小时的连接。注意如果 使用了 MySQL , Flask-SQLALchemy 自动设定 这个值为 2 小时。 |
给 flask对象 配置完成数据库配置之后,初始化SQLAlchemy对象(flask 对象当参数),整体代码如下:
app = Flask(__name__)
app.config['SQLALCHEMY_DATABASE_URI'] = 'mysql://root:[email protected]:3306/book_test_flask'
app.config['SQLALCHEMY_TRACK_MODIFICATIONS'] = True
app.config['SQLALCHEMY_ECHO'] = True
# 创建SQLAlchemy对象,以后 增删查 使用这个对象的方法
db =SQLAlchemy(app)
三、类模型
# 继承Model
class Author(db.Model):
__tablename__ = authors
id = db.Column(db.Integer,primary_key=True)
name = db.Column(db.String(64),unique=True)

1、常用字段的类型
| 类型名 | python中类型 | 说明 |
|---|---|---|
| Integer | int | 普通整数,一般是32位 |
| SmallInteger | int | 取值范围小的整数,一般是16位 |
| BigInteger | int或long | 不限制精度的整数 |
| Float | float | 浮点数 |
| Numeric | decimal.Decimal | 普通整数,一般是32位 |
| String | str | 变长字符串 |
| Text | str | 变长字符串,对较长或不限长度的字符串做了优化 |
| Unicode | unicode | 变长Unicode字符串 |
| Boolean | bool | 布尔值 |
| Date | datetime.date | 时间 |
| Time | datetime.datetime | 日期和时间 |
| LargeBinary | str | 二进制文件 |
2、字段的类型
| 选项名 | 说明 |
|---|---|
| primary_key | 如果为True,代表表的主键 |
| unique | 如果为True,代表这列不允许出现重复的值 |
| index | 如果为True,为这列创建索引,提高查询效率 |
| nullable | 如果为True,允许有空值,如果为False,不允许有空值 |
| default | 为这列定义默认值 |
3、常用的关系选项(一对对,多对多,自关联)
| 选项名 | 说明 |
|---|---|
| backref | 在关系的另一模型中添加反向引用 |
| primary join | 明确指定两个模型之间使用的联结条件 |
| uselist | 如果为False,不使用列表,而使用标量值 |
| order_by | 指定关系中记录的排序方式 |
| secondary | 指定多对多关系中关系表的名字 |
| secondary join | 在SQLAlchemy中无法自行决定时,指定多对多关系中的二级联结条件 |
四、常用数据库操作
前面讲了那么多,只是讲解了如何定义一个模型,当然这里面还有数据库的关联关系,没有说明,我们后面在代码里说明:对于数据库操作,我们就先创建一些表:
1、创建表模型
class Role(db.Model):
# 定义表名
__tablename__ = 'roles'
# 定义列对象
id = db.Column(db.Integer, primary_key=True)
name = db.Column(db.String(64), unique=True)
us = db.relationship('User', backref='role')
#repr()方法显示一个可读字符串
def __repr__(self):
return 'Role:%s'% self.name
class User(db.Model):
__tablename__ = 'users'
id = db.Column(db.Integer, primary_key=True)
name = db.Column(db.String(64), unique=True, index=True)
email = db.Column(db.String(64),unique=True)
password = db.Column(db.String(64))
# 定义外键,传入的是“一”的一方唯一表示
role_id = db.Column(db.Integer, db.ForeignKey('roles.id'))
def __repr__(self):
return 'User:%s'%self.name
说明:
- 上面定义了两个模型:Role模型、User模型,Role 和 User 是 一对多的关系;Role是一,User是多,对于一对多我们给多的一方添加外键(这点应该没有疑义),外键约束ForeignKey(外键) ,这里外键可以传入 数据表名.字段名 ,方便操作。
- us = db.relationship(‘User’, backref=‘role’) , 可以在数据表中加入一列,好直接查询关联的数据表,直接可以查询当前role的用户有哪些和当前用户对应哪个role,只是为了查询方便才使用这个,真正关联数据库的是前面使用ForeignKey 进行关联
2、具体操作
创建(删除)表
# 删除表
db.drop_all()
# 创建表
db.create_all() # db为我们上面配置完flask创建的SQLAlchemy 对象
运行结果

插入数据
- add()
ro1 = Role(name='admin')
# 添加数据
db.session.add(ro1)
# 数据提交,pyhton默认开启事务了,所以必须自己提交
db.session.commit()

当然可以一次性插入多条数据:
- add_all():增加多条数据
#再次插入一条数据
ro2 = Role(name='user')
db.session.add(ro2)
db.session.commit()
us1 = User(name='wang',email='[email protected]',password='123456',role_id=ro1.id)
us2 = User(name='zhang',email='[email protected]',password='201512',role_id=ro2.id)
us3 = User(name='chen',email='[email protected]',password='987654',role_id=ro2.id)
us4 = User(name='zhou',email='[email protected]',password='456789',role_id=ro1.id)
us5 = User(name='tang',email='[email protected]',password='158104',role_id=ro2.id)
us6 = User(name='wu',email='[email protected]',password='5623514',role_id=ro2.id)
us7 = User(name='qian',email='[email protected]',password='1543567',role_id=ro1.id)
us8 = User(name='liu',email='[email protected]',password='867322',role_id=ro1.id)
us9 = User(name='li',email='[email protected]',password='4526342',role_id=ro2.id)
us10 = User(name='sun',email='[email protected]',password='235523',role_id=ro2.id)
db.session.add_all([us1,us2,us3,us4,us5,us6,us7,us8,us9,us10])
db.session.commit()
注意:
在这里,Role和User是一对多的数据关联,所以我们在多的一方引用一的一方的数据,就需要先将少的一方插入并且必须提交,不然会报错。

- commit():提交数据,默认开启了事务,需要自己提交,但也可以配置让代码自动提交。
- rollback() :回滚
查询数据
query
常见的过滤器
| 过滤器 | 说明 |
|---|---|
| filter() | 把过滤器添加到原查询上,返回一个新查询 |
| filter_by() | 把等值过滤器添加到原查询上,返回一个新查询 |
| limit | 使用指定的值限定原查询返回的结果 |
| offset() | 偏移原查询返回的结果,返回一个新查询 |
| order_by() | 根据指定条件对原查询结果进行排序,返回一个新查询 |
| group_by() | 根据指定条件对原查询结果进行分组,返回一个新查询 |
常见的查询执行器
| 方法 | 说明 |
|---|---|
| all() | 以列表形式返回查询的所有结果 |
| first() | 返回查询的第一个结果,如果未查到,返回None |
| first_or_404() | 返回查询的第一个结果,如果未查到,返回404 |
| get() | 返回指定主键对应的行,如不存在,返回None |
| get_or_404() | 返回指定主键对应的行,如不存在,返回404 |
| count() | 返回查询结果的数量 |
| paginate(n,m) | 返回一个Paginate对象,它包含指定范围内的结果,n:第几页 m:每页的个数 |
查询练习
# 查询所有用户数据
User.query..all()
# 查询有多少个用户
User.query.count()
# 查询第1个用户
User.query.first()
# 查询id为4的用户[3种方式]
User.query.filter(User.id == 4).first()
User.query.get(4)
User.query.filter_by(id=4).first()
# 查询名字结尾字符为g的所有数据[开始/包含]
User.query.filter(User.name.startswith('g')).all()
User.query.filter(User.name.endswith('g')).all()
User.query.filter(User.name.contains('g')).all()
# 查询名字不等于wang的所有数据[2种方式]
User.query.filter(User.name != 'wang').all()
User.query.filter(not_(User.name=='Wang')).all()
# 查询名字和邮箱都以 li 开头的所有数据[2种方式]
User.query.filter(User.name.startswith('li'),User.email.startswith('li')).all()
User.query.filter(and_(User.name.startswith('li'),User.email.startswith('li'))).all()
# 查询password是 `123456` 或者 `email` 以 `itheima.com` 结尾的所有数据
User.query.filter(or_(User.password=='123456',User.email.endswith('itheima.com'))).all()
# 查询id为 [1, 3, 5, 7, 9] 的用户列表
User.query.filter(User.id.in_([1,3,5,7,9])).all()
# 查询name为liu的角色数据
User.query.filter(User.name == 'liu').first().role
# 查询所有用户数据,并以邮箱排序,升序 asc(默认) 降序: desc()
User.query.order_by(User.email.desc())
# 每页3个,查询第2页的数据 paginate(n,m) n:第几页 m:每页的个数
paginate = User.query.paginate(2,3) # 返回值是个paginate对象
current_page = paginate.page # 当前页
total_pages = paginate.pages # 总页数
query_data = paginate.items # 当前页的具体内容,返回值为一个列表,列表中的每一个数据都是一个User对象
删除和修改数据
- delete():删除数据
del_prv_data = User.query.all() # 查询所有数据'
print(del_prv_data)
user = User.query.filter(User.name=='wang').first() # 查询name为wang的数据
db.session.delete(user) # 删除name为wang 的数据
db.session.commit() # 提交
del_after_data = User.query.all() # 查询所有数据进行对比
print(del_after_data )
结果展示:

- 修改数据
update_prv_data = User.query.all() # 查询所有数据'
print(update_prv_data)
user = User.query.filter(User.name=='wang').first() # 查询name为wang的数据
# 修改name为wang 的数据
user.name = '请叫我好人,不要叫我老王'
db.session.commit() # 提交
update_after_data = User.query.all() # 查询所有数据进行对比
print(update_after_data )
