1、下列关于const和#define定义常量的区别,说法不正确的有?(D)
A.define宏是在预处理阶段展开。const常量是编译运行阶段使用
B.宏没有类型,不做任何类型检查,仅仅是展开。const常量有具体的类型,在编译阶段会执行类型检查
C.define宏仅仅是展开,有多少地方使用,就展开多少次,不会分配内存。const常量会在内存中分配(可以是堆中也可以是栈中)
D.const定义和#define定义的常量在程序运行过程中只有一份拷贝A,正确,#define定义的宏是在预处理阶段进行替换的,const常量是在编译、运行阶段进行使用的。
注意是仅仅的字符串替换,并不会检查其合法性。
预处理阶段做了的任务:
1:将头文件中的内容(源文件之外的文件)插入到源文件中
2:进行了宏替换的过程(简单的字符串替换),定义和替换了由#define指令定义的符号
3:删除掉注释的过程,注释是不会带入到编译阶段
4:条件编译
B,正确,所有的宏替换只是简单的字符串替换,注意是字符串替换,所以并不会检查其合法性,而const定义的常量依然是内置类型等,所以会对其进行类型安全检查。
C,正确,宏定义在程序中使用了几次在预处理阶段就会被展开几次,并不会增加内存占用,但是宏定义每展开一次,代码的长度就要发生变化(所以有利必有弊啊!),而const常量也会为其分配内存(如果是动态申请空间肯定就是堆中了)。
D,错误,const定义的常量只有一次拷贝没毛病,而define定义的变量在内存中并没有拷贝,因为所有的预处理指令都在预处理时进行了替换。
2、以下哪个值最大(A)
void test() {
int s1;
int s2;
int *s3 = (int *)malloc(4);
int *s4 = (int *)malloc(4);
}
A.&s1
B.&s2
C.s3
D.s4&属于HTML代码。表示符号 &
<显示<,>显示>,&显示&,&quo显示", 显示空格字符
栈空间内存是从高地址向低地址值分配的。
s3,s4是堆内存地质,与s1,s2无法作对比。
除非s1,s2,s3,s4都取地址,那么s1的地址值是最大的。此地址值对应于虚拟内存地址,非实际物理地址。
考察内存模型,栈向下生长,堆向上生长
虚拟地址大小从下往上递增
3、以下哪个数据结构不是二叉树(C)
A.AVL B.Huffman C.B+ D.红黑
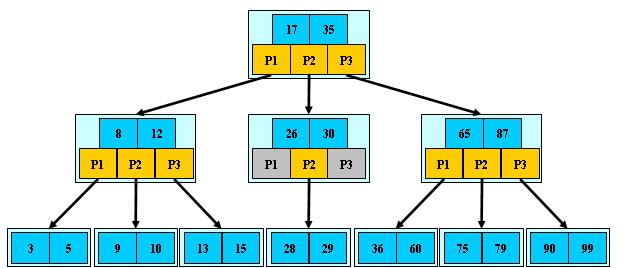
B-树
是一种多路搜索树(并不是二叉的):
1.定义任意非叶子结点最多只有M个儿子;且M>2;
2.根结点的儿子数为[2, M];
3.除根结点以外的非叶子结点的儿子数为[M/2, M];
4.每个结点存放至少M/2-1(取上整)和至多M-1个关键字;(至少2个关键字)
5.非叶子结点的关键字个数=指向儿子的指针个数-1;
6.非叶子结点的关键字:K[1], K[2], …, K[M-1];且K[i] < K[i+1];
7.非叶子结点的指针:P[1], P[2], …, P[M];其中P[1]指向关键字小于K[1]的
子树,P[M]指向关键字大于K[M-1]的子树,其它P[i]指向关键字属于(K[i-1], K[i])的子树;
8.所有叶子结点位于同一层;
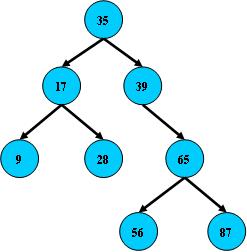
二叉树
1.所有非叶子结点至多拥有两个儿子(Left和Right);
2.所有结点存储一个关键字;
3.非叶子结点的左指针指向小于其关键字的子树,右指针指向大于其关键字的子树;
如:
4、以下说法正确的是(A、B、D)
A.gcc编译.c文件,__cplusplus没有定义,编译器按照c编译代码 B.gcc编译.cpp文件,__cplusplus有定义,编译器按照c++编译代码 C.g++编译.c文件, __cplusplus没有定义,编译器按照c编译代码 D.g++编译.cpp文件, __cplusplus有定义,编译器按照c++编译代码
gcc和g++的区别:
首先说明:gcc 和 GCC 是两个不同的东西
GCC:GNU Compiler Collection(GUN 编译器集合),它可以编译C、C++、JAV、Fortran、Pascal、Object-C、Ada等语言。
gcc是GCC中的GUN C Compiler(C 编译器)
g++是GCC中的GUN C++ Compiler(C++编译器)
就本质而言,gcc和g++并不是编译器,也不是编译器的集合,它们只是一种驱动器,根据参数中要编译的文件的类型,调用对应的GUN编译器而已,比如,用gcc编译一个c文件的话,会有以下几个步骤:
Step1:Call a preprocessor, like cpp.
Step2:Call an actual compiler, like cc or cc1.
Step3:Call an assembler, like as.
Step4:Call a linker, like ld
由于编译器是可以更换的,所以gcc不仅仅可以编译C文件
所以,更准确的说法是:gcc调用了C compiler,而g++调用了C++ compiler
gcc和g++的主要区别
1. 对于 *.c和*.cpp文件,gcc分别当做c和cpp文件编译(c和cpp的语法强度是不一样的)
2. 对于 *.c和*.cpp文件,g++则统一当做cpp文件编译
3. 使用g++编译文件时,g++会自动链接标准库STL,而gcc不会自动链接STL
4. gcc在编译C文件时,可使用的预定义宏是比较少的
5. gcc在编译cpp文件时/g++在编译c文件和cpp文件时(这时候gcc和g++调用的都是cpp文件的编译器),会加入一些额外的宏
5、编译过程中,语法分析器的任务是?(B、C、D)
A.分析单词是怎样构成的 B.分析单词串是如何构成语言和说明的 c.分析语句和说明是如何构成程序的 D.分析程序的结构
强化一下~~~~~~~~
1、32位机器上,以下结构的sizeof(P)为(C)
struct A {
int a;
char b;
int c;
char d;
}
struct P {
struct A w[2];
short b;
struct A* p;
}
A.26 B.38 C.40 D.30
/*结构体对齐和填充:
结构体每个成员相对于结构体首地址的偏移量都是成员大小的整数倍,如果不是,编译器会自动在成员间填充。*/
struct A {
int a; //4 bytes
char b; //1 bytes
//char pad[3] //3 bytes
int c; //4 bytes
char d; //1 bytes
//char pad[3] //3 bytes
} // total = 16 bytes
/* P中有结构体A的成员,但是计算时按照A中数据类型确定的*/
struct P {
struct A w[2]; // 2 * 16 bytes
short b; //2 bytes
//char pad[2] //2 bytes
struct A* p; //4 bytes
} // total = 40 bytes
2、以下哪个是带行缓冲的IO(C)
A.write(STDOUT_FILENO, "helloworld", 10); B.fprintf(stderr, "helloworld"); c.fwrite("helloworld", 10, 1, stdout); D.fo = fopen("a.txt", "w"); fwrite("helloworld", 10, 1, fo);
不带缓冲IO与带缓冲IO的区别分析:参考
https://blog.csdn.net/chenxiao_ji/article/details/45717651
3、父进程open了一个文件,并且通过fork产生一个子进程,以下说法正确的是(B)
A.父子进程不共享文件的偏移量 B.子进程复制了父进程的文件描述符表 C.子进程复制了父进程的文件表 D.子进程复制了父进程的v节点表
fork产生的子进程是正在运行父进程的拷贝,也就说运行状态是一样的。对于文件操作是通过文件描述符来操作的(fd=open(filename,mode,flag),fd就是文件描述符),所以子进程复制的是文件描述符表
4、在一个cpp文里面,定义了一个static类型的静态全局变量,下面说法正确的是(A)
A.只能在该cpp文件中使用该变量 B.该变量的值不可修改 C.该变量不能在类成员函数中出现 D.这种变量只能是基本类型(如int,char)不能是类或者struct
5、699个节点的完全二叉树,有叶子节点多少个(A)
A.350 B.699 C.1398 D.其他都不是
(1)完全二叉树如果有N个节点,那么叶子节点M=(N+1)/2。
(2)度为2的节点个数=叶子结点(度为0的结点)-1
证明:
