0.思路
这里的案例是 爬取敲哭博客首页的访问量是多少。
先看看网页代码中访问量附近容易 用正则表达式捕获的内容如下:
<dl>
<dt>访问:</dt>
<dd title="30634">
3万+ </dd>
</dl>所以我想用正则表达式匹配:
<dt>访问:</dt>
<dd title="30634"
然后用字符串截取出数字就行了。
1.代码如下:
using System;
using System.IO;
using System.Net;
using System.Text.RegularExpressions;
namespace JIeXi2Test
{
class Program
{
static void Main(string[] args)
{
WebRequest request = WebRequest.Create("https://blog.csdn.net/qq_38261174/article/list/1");
WebResponse response = request.GetResponse();
StreamReader reader = new StreamReader(response.GetResponseStream());
String page = reader.ReadToEnd();
//Console.WriteLine(page);
//String paattern = @"<dt>[\u2E80-\u9FFF]{2}:</dt>";
//网页代码中的换行只能用\s*匹配,\r\n匹配不到。用两个连着的双引号表示双引号
String paattern = @"<dt>访问:</dt>\s*<dd\stitle=""\d+""";
//匹配访问量附近容易寻找的东西,从而截取访问量
MatchCollection mc = Regex.Matches(page ,paattern);
String match = mc[0].Value;
String pageView = match.Substring(match.IndexOf('"')+1 , match.LastIndexOf('"')-match.IndexOf('"')-1);
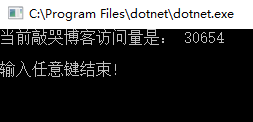
Console.WriteLine("当前敲哭博客访问量是: "+pageView);
Console.WriteLine("\r\n输入任意键结束!");
Console.ReadKey();
}
}
}
结果:
0.思路
学习的网址如下:
https://blog.csdn.net/luolan9611/article/details/79868517
https://blog.csdn.net/tindoc/article/details/53648189
下面的示例是抓取验证码图片并下载100张。
1.代码如下:
using System;
using System.IO;
using System.Net;
using System.Text;
using System.Text.RegularExpressions;
using System.Threading;
using System.Web;
namespace JIeXi2Test
{
class Program
{
static void Main(string[] args)
{
GraspBtmp();
Console.WriteLine("\r\n输入任意键结束!");
Console.ReadKey();
}
private static void GraspBtmp() {
String url = "https://login.sina.com.cn/cgi/pin.php?r=1523262272227&lang=zh&type=hollow";
String savePath = @"G:\新建文件夹\datas\";
int numbers = 0;
WebRequest request = null;
WebResponse response;
Stream inStream = null;
Stream outStream = null;
byte[] buffer = new byte[1024];
String newfile = String.Empty;
System.Console.Write("当前下载的图片数量:");
while (numbers < 100) {
request = WebRequest.Create(url);
response = request.GetResponse();
if (!response.ContentType.ToLower().StartsWith("text/")) { //简单判断网页内容类型
newfile = savePath + numbers + ".png";
outStream = File.Create(newfile);
inStream = response.GetResponseStream();
int read = 0;
do {
read = inStream.Read(buffer,0,buffer.Length);
if (read > 0) {
outStream.Write(buffer,0,read); //将图片写入文件,共下载100张
}
} while (read > 0);
inStream.Close();
outStream.Close();
System.Console.Write("{0,3}\b\b\b", numbers+1);
}
numbers++;
}
}
}
}
代码主要参考了: https://blog.csdn.net/luolan9611/article/details/79868517
其中小问题的解决: https://zhidao.baidu.com/question/1179198489209190179.html
输出结果如图:

0.
查看敲哭博客的文章是否更新。
思路:查看第一篇文章的名字,从而知道是否更新。
代码如下:
//博客第一篇文章是否改变
private static void CheckBKifChange() {
String BKurl = @"https://blog.csdn.net/qq_38261174";
WebRequest request = WebRequest.Create(BKurl);
WebResponse response = request.GetResponse();
StreamReader reader = new StreamReader(response.GetResponseStream());
StreamWriter writer = new StreamWriter(@"G:\新建文件夹\shouye.txt");
String page = reader.ReadToEnd().ToString();
writer.Write(page);
String pattern = @"<a.*\s*.*\s*.*\s*.*\s{2}</a>"; // \s的数量匹配不能少,因为有的有多个换行
MatchCollection mc = Regex.Matches(page, pattern);
String s = mc[1].Value; //这里自行解决
int startIndex = s.IndexOf("</span>")+7;
int endIndex = s.IndexOf("</a>");
s = s.Substring(startIndex , endIndex - startIndex).Trim();
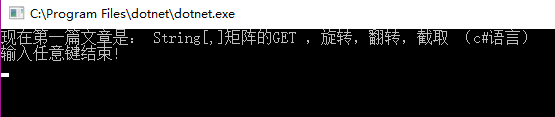
Console.Write("现在第一篇文章是: "+s);
reader.Close();
writer.Close();
}
改进如下:
正则表达式不匹配所有结果,而是匹配前N条记录,这里就是匹配前两条记录即可。
更改上面部分代码如下:
String pattern = @"<a.*\s*.*\s*.*\s*.*\s{2}</a>"; // \s的数量匹配不能少,因为有的有多个换行
Match mc = Regex.Match(page, pattern);
for (int i = 0; i < 1; i++) {
if (mc.Success) { //[0] //一开始就是一条,所以只需再匹配一条即可
mc = mc.NextMatch(); //[1] 可用list保存前N条匹配,而不用匹配所有结果
}
}
String s = mc.Value; //[1]