摘自:http://pandas.pydata.org/pandas-docs/stable/generated/pandas.DataFrame.loc.html
具体用法,假设数据源为:
>>> df = pd.DataFrame([[1, 2], [4, 5], [7, 8]], ... index=['cobra', 'viper', 'sidewinder'], ... columns=['max_speed', 'shield']) >>> df max_speed shield cobra 1 2 viper 4 5 sidewinder 7 8
用法示例:
1)单独标签,返回的是一个Series

2) 内嵌List,返回一个DataFrame

3)Single label for row and column,注意,先索引,再列名

4)多个索引加列名

5)用布尔值:针对行进行过滤。False表示不取这一行。True表示取出这一行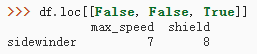
6)条件判断


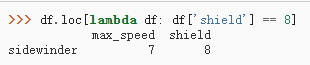
其中,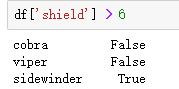
7)设置值:选中某些值;整行;整列



更多用法,请看官方文档