Stream文件流模块
Node中File System 模块并没有提供一个 copy的方法,但是可以通过读取文件和写入文件的方式实现;
把文件A的内容全部读入Buffer缓冲区,然后再从缓冲区写入文件B,该过程的执行流程图如下:
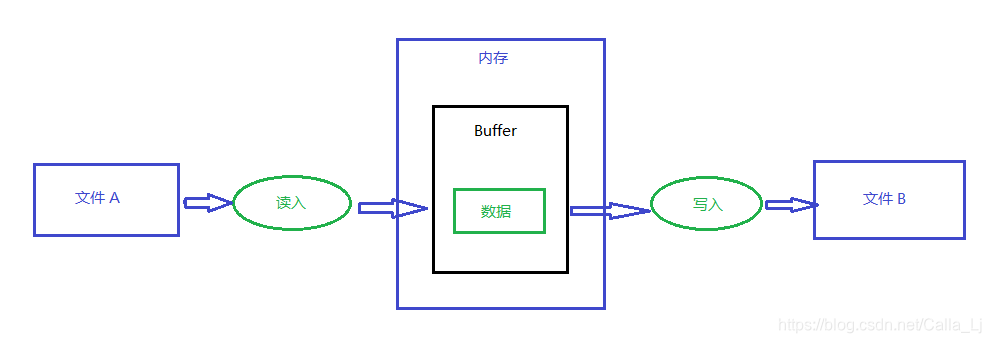
缺点:
Buffer缓冲区限制在1GB,这样的操作对于小型的文本文件,没有多大问题,但是对于较大的文件,比如音频,视频文件,如果使用这种方法很容易使内存爆仓.
解决思路:
采用"读一部分,写一部分"方式;不管文件有多大,只要时间允许,总会处理完成.
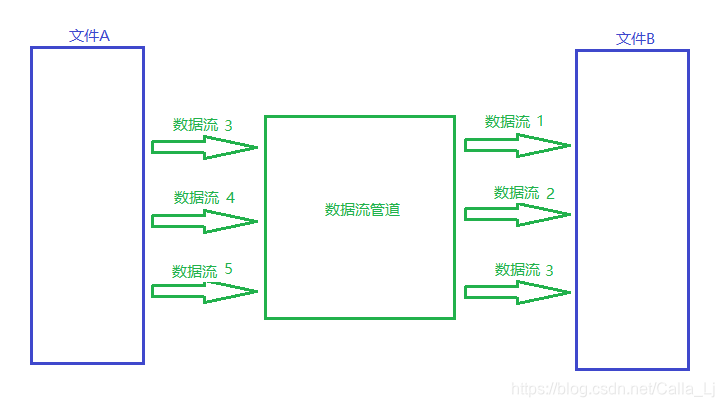
文件A中的数据以流动的形式通过数据管道,然后写入到文件B中
例如: 在网络上观看视频,并不是整个视频都下载好了才播放的,而是下一点播一点.
优点:
接收方可以提前处理,缩短等待时间,提高速度.
Node.js中文件流的操作由Stream模块提供
使用文件流进行文件复制,首先要创建一个可读流(Readable Stream),可读流可以让用户在源文件中分块读取文件中的数据,然后再从可读流中读取数据.创建可读流的语法如下:
fs.createReadStream(path[,options])
说明:由于流是基于EventEmitter的,从流读取数据的最好方法是监听数据事件,并附加一个回调函数
Stream常用事件表:
| 事件 | 说明 |
|---|---|
| data | 当有数据可读时触发 |
| end | 没有更多数据可读时触发 |
| error | 在接收和写入过程中发生错误时触发 |
| finish | 所有数据已经被写入到底层系统是触发 |
接下来我们可以结合一个案例演示进一步学习,
创建一个demo文件夹,在文件夹下创建一个input.txt文件,并写入一句话;然后再创建一个read.js文件,代码如下:
/**
* 从流中读取数据
*/
var fs = require('fs')
var total = ''
// 创建可读流
var readableStream = fs.createReadStream('input.txt')
// 设置编码为utf8
readableStream.setEncoding('UTF8')
// 处理流事件
readableStream.on('data', function (chunk) {
total += chunk
})
readableStream.on('end', function () {
console.log(total)
})
readableStream.on('error', function (err) {
console.log(err.stack)
})
console.log('程序执行完毕!')
打开终端,执行结果如图下:

可见,数据被成功读取了,由于事件流的操作都是异步的,所以说先输出"程序执行完毕!"
可写流(Writeable Stream)让用户可以写数据到目的地,像可读流一样,也是基于EventEmitter;创建可写流的语法如下:
fs.createWriteStream(path[,options])
write.js
/**
* 使用文件流进行文件复制
*/
var fs = require('fs')
// 创建可读流
var readableStream = fs.createReadStream('input.txt')
// 创建可写流
var writeableStream = fs.createWriteStream('output.txt')
// 设置编码为utf8
readableStream.setEncoding('UTF8')
// 处理流事件
readableStream.on('data', function (chunk) {
// 讲独处的数据写入可写流
writeableStream.write(chunk)
})
readableStream.on('end', function () {
// 将剩下的数据全部写入,并且关闭写入的文件,停止写入操作
writeableStream.end()
})
readableStream.on('error', function (err) {
console.log(err.stack)
})
console.log('程序执行完毕!')
运行结果:

使用文件流复制文件后的目录:
然后,打开output.txt文件,可以看到与input.txt文件内容相同:

在使用大文件复制的案例中,通过可读流的chunk参数来传递数据,如果把数据比作是水,这个chunk就相当于盆,使用盆来完成水的传递.在可读流中还有一个函数叫pipe(),这个函数是一个很高效的文件处理方式,可以简化之前复制文件的操作,pipe翻译成中文是管子的意思,使用pipe()对文件进行复制就相当于把盆换成管子,通过管子完成数据的读取和写入.
下面通过案例来演示如何使用pipe()处理大文件复制:
pipe.js
/**
* 使用pipe()进行文件复制
*/
var fs = require('fs')
// 原文件路径
var srcPath = "f:/music-player/demo2/input.txt"
// 目标文件路径
var distPath = "f:music-player/demo2/output.txt"
var readableStream = fs.createReadStream(srcPath)
var writeableStream = fs.createWriteStream(distPath)
// 可以通过使用可读流的函数pipe()接入到可写流中
// pipe()是一种很高效的数据处理方式
if (readableStream.pipe(writeableStream)) {
console.log('文件复制成功了')
} else {
console.log('文件复制失败了')
}
打开终端,执行pipe.js,运行结果如下:
文件目录:
然后,打开output.txt文件,可以看到与input.txt文件内容相同,文件复制成功
