版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/Invokar/article/details/86608144
Tensorflow实现GoogleInceptionNet_V3
引言:Google Inception Net首次出现在ILSVRC 2014的比赛中,并且有非常好的性能——top-5的错误率6.67%,后来又逐渐提出了Inception V2、Inception V3和Incepiton V4。本文实现的网络结构为Inception V3
-
相关阅读:
Tensorflow实现VGGNet
Tensorflow实现AlexNet -
模块化方法:
本文将通过模块化加注释的方法,来实现GoogleInceptionNet,这样可以帮助初学者快速读懂其结果以及实现方法
- 定义网络中经常用的函数的默认参数:inception_v3_arg_scope()
- 定义Inception v3网络结构(前面部分):inception_v3_base()
- 定义Inception V3网络的最后一部分:incepiton_v3()
- 定义耗时:time_tensorflow_run()
- GoogleInceptionNet结构:



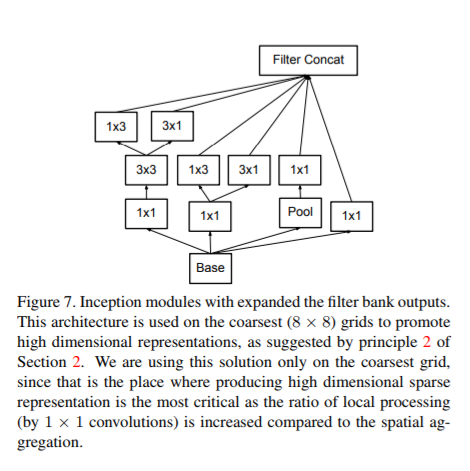
- GoogleInceptionNet创新之处:
- 去除了最后的全连接层,用全局平均池化层(即将图片尺寸变为1x1)来取代他
- 根据Hebbian原理,多次使用1x1卷积核(即将相关性很高、在同一个空间位置但是不同通道的特征连接起来)
- 使用了Inception Module提高了参数利用效率(上截图Fig5-Fig7)
- 提出了著名的Batch Normalization(BN)方法,该方法可以让大型卷积网络的训练速度加快很多倍,同时收敛后的分类内部准确率也可以得到大幅提高
- 引入Factorization into small convolutions的思想,将一个较大的2维卷积拆成两个较小的一维卷积,如把3x3卷积拆成1x3和3x1两个小卷积,不仅可以加速运算还可以减轻过拟合
导入包:
from datetime import datetime
import math
import time
import tensorflow as tf
slim = tf.contrib.slim
trunc_normal = lambda stddev: tf.truncated_normal_initializer(0.0, stddev) # 产生截断的正态分布
生成网络中经常用的函数的默认参数:
# 生成网络中经常用的函数的默认参数
def inception_v3_arg_scope(weight_decay = 4e-5,
stddev = 0.1,
batch_norm_var_collection = 'moving_vars'):
'''
weight_decay: L2正则weight_decay
stddev: 标准差
batch_norm_var_collection: 默认设置为moving_vars
'''
# 定义batch normalization的参数字典
batch_norm_params = {
'decay': 0.9997,
'epsilon': 0.001,
'updates_collections': tf.GraphKeys.UPDATE_OPS,
'variables_collections': {
'beta': None,
'gamma': None,
'moving_mean': [batch_norm_var_collection],
'moving_variance': [batch_norm_var_collection],
}
}
# 使用slim.arg_scope对参数进行自动复赋值
with slim.arg_scope([slim.conv2d, slim.fully_connected],
weights_regularizer=slim.l2_regularizer(weight_decay)):
with slim.arg_scope(
[slim.conv2d],
weights_initializer=trunc_normal(stddev),
activation_fn=tf.nn.relu,
normalizer_fn=slim.batch_norm,
normalizer_params=batch_norm_params) as sc:
return sc
定义Inception v3网络结构(前面部分):
# 定义Inception v3网络结构
def inception_v3_base(inputs, scope = None):
end_points = {}
with tf.variable_scope(scope, 'InceptionV3', [inputs]):
'''
前面的卷积层结构 类似于VGGNet
input:299x299x3
output:35x35x192
'''
with slim.arg_scope([slim.conv2d, slim.max_pool2d, slim.avg_pool2d],
stride = 1, padding = 'VALID'):
net = slim.conv2d(inputs, 32, [3, 3], stride = 2, scope = 'Conv2d_1a_3x3')
net = slim.conv2d(net, 32, [3, 3], scope = 'Conv2d_2a_3x3')
net = slim.conv2d(net, 64, [3, 3], padding = 'SAME', scope = 'Conv2d_2b_3x3')
net = slim.max_pool2d(net, [3, 3], stride = 2, scope = 'MaxPool_3a_3x3')
net = slim.conv2d(net, 80, [1, 1], scope = 'Conv2d_3b_1x1')
net = slim.conv2d(net, 192, [3, 3], scope = 'Conv2d_4a_3x3')
net = slim.max_pool2d(net, [3, 3], stride = 2, scope = 'MaxPool_5a_3x3')
with slim.arg_scope([slim.conv2d, slim.max_pool2d, slim.avg_pool2d],
stride = 1, padding = 'SAME'):
'''
第一个Inception模块组:第一个Module
input:35x35x192
output:35x35x256
'''
with tf.variable_scope('Mixed_5b'):
with tf.variable_scope('Branch_0'):
branch_0 = slim.conv2d(net, 64, [1, 1], scope = 'Conv2d_0a_1x1')
with tf.variable_scope('Branch_1'):
branch_1 = slim.conv2d(net, 48, [1, 1], scope = 'Conv2d_0a_1x1')
branch_1 = slim.conv2d(branch_1, 64, [5, 5], scope = 'Conv2d_0a_5x5')
with tf.variable_scope('Branch_2'):
branch_2 = slim.conv2d(net, 64, [1, 1], scope = 'Conv2d_0a_1x1')
branch_2 = slim.conv2d(branch_2, 96, [3, 3], scope = 'Conv2d_0b_3x3')
branch_2 = slim.conv2d(branch_2, 96, [3, 3], scope = 'Conv2d_0c_3x3')
with tf.variable_scope('Branch_3'):
branch_3 = slim.avg_pool2d(net, [3, 3], scope = 'AvgPool_0a_3x3')
branch_3 = slim.conv2d(branch_3, 32, [1, 1], scope = 'Conv2d_0b_3x3')
# 将四个分支在channel上连起来 64 + 64 + 96 + 32 = 256
net = tf.concat([branch_0, branch_1, branch_2, branch_3], 3)
'''
第一个Inception模块组:第二个Module
input:35x35x256
output:35x35x288
'''
with tf.variable_scope('Mixed_5c'):
with tf.variable_scope('Branch_0'):
branch_0 = slim.conv2d(net, 64, [1, 1], scope = 'Conv2d_0a_1x1')
with tf.variable_scope('Branch_1'):
branch_1 = slim.conv2d(net, 48, [1, 1], scope = 'Conv2d_0b_1x1')
branch_1 = slim.conv2d(branch_1, 64, [5, 5], scope = 'Conv_1_0c_5x5')
with tf.variable_scope('Branch_2'):
branch_2 = slim.conv2d(net, 64, [1, 1], scope = 'Conv2d_0a_1x1')
branch_2 = slim.conv2d(branch_2, 96, [3, 3], scope = 'Conv2d_0b_3x3')
branch_2 = slim.conv2d(branch_2, 96, [3, 3], scope = 'Conv2d_0c_3x3')
with tf.variable_scope('Branch_3'):
branch_3 = slim.avg_pool2d(net, [3, 3], scope = 'AvgPool_0a_3x3')
branch_3 = slim.conv2d(branch_3, 64, [1, 1], scope = 'Conv2d_0b_1x1')
# 64 + 64 + 96 + 64 = 288
net = tf.concat([branch_0, branch_1, branch_2, branch_3], 3)
'''
第一个Inception模块组:第三个Module(与第二个结构相同)
input:35x35x288
output:35x35x288
'''
with tf.variable_scope('Mixed_5d'):
with tf.variable_scope('Branch_0'):
branch_0 = slim.conv2d(net, 64, [1, 1], scope='Conv2d_0a_1x1')
with tf.variable_scope('Branch_1'):
branch_1 = slim.conv2d(net, 48, [1, 1], scope='Conv2d_0a_1x1')
branch_1 = slim.conv2d(branch_1, 64, [5, 5], scope='Conv2d_0b_5x5')
with tf.variable_scope('Branch_2'):
branch_2 = slim.conv2d(net, 64, [1, 1], scope='Conv2d_0a_1x1')
branch_2 = slim.conv2d(branch_2, 96, [3, 3], scope='Conv2d_0b_3x3')
branch_2 = slim.conv2d(branch_2, 96, [3, 3], scope='Conv2d_0c_3x3')
with tf.variable_scope('Branch_3'):
branch_3 = slim.avg_pool2d(net, [3, 3], scope='AvgPool_0a_3x3')
branch_3 = slim.conv2d(branch_3, 64, [1, 1], scope='Conv2d_0b_1x1')
# 64 + 64 + 96 + 64 = 288
net = tf.concat([branch_0, branch_1, branch_2, branch_3], 3)
'''
第二个Inception模块组:第一个Module
input:35x35x288
output:17x17x768
'''
with tf.variable_scope('Mixed_6a'):
with tf.variable_scope('Branch_0'):
branch_0 = slim.conv2d(net, 384, [3, 3], stride = 2, padding = 'VALID', scope = 'Conv2d_1a_1x1')
with tf.variable_scope('Branch_1'):
branch_1 = slim.conv2d(net, 64, [1, 1], scope = 'Conv2d_0a_1x1')
branch_1 = slim.conv2d(branch_1, 96, [3, 3], scope = 'Conv2d_0b_3x3')
branch_1 = slim.conv2d(branch_1, 96, [3, 3], stride = 2, padding = 'VALID', scope = 'Conv2d_1a_1x1')
with tf.variable_scope('Branch_2'):
branch_2 = slim.max_pool2d(net, [3, 3], stride = 2, padding = 'VALID', scope = 'MaxPool_1a_3x3')
# 384 + 96 + 288 = 768
net = tf.concat([branch_0, branch_1, branch_2], 3)
'''
第二个Inception模块组:第二个Module
input:17x17x768
output:17x17x768
'''
with tf.variable_scope('Mixed_6b'):
with tf.variable_scope('Branch_0'):
branch_0 = slim.conv2d(net, 192, [1, 1], scope = 'Conv2d_0a_1x1')
with tf.variable_scope('Branch_1'):
# Factorization into small convolutions思想,减少参数的同时也减轻了过拟合
branch_1 = slim.conv2d(net, 128, [1, 1], scope = 'Conv2d_0a_1x1')
branch_1 = slim.conv2d(branch_1, 128, [1, 7], scope = 'Conv2d_0b_1x7')
branch_1 = slim.conv2d(branch_1, 192, [7, 1], scope = 'Conv2d_0c_7x1')
with tf.variable_scope('Branch_2'):
branch_2 = slim.conv2d(net, 128, [1, 1], scope = 'Conv2d_0a_1x1')
branch_2 = slim.conv2d(branch_2, 128, [7, 1], scope = 'Conv2d_0b_7x1')
branch_2 = slim.conv2d(branch_2, 128, [1, 7], scope = 'Conv2d_0c_1x7')
branch_2 = slim.conv2d(branch_2, 128, [7, 1], scope = 'Conv2d_0d_7x1')
branch_2 = slim.conv2d(branch_2, 192, [1, 7], scope = 'Conv2d_0e_1x7')
with tf.variable_scope('Branch_3'):
branch_3 = slim.avg_pool2d(net, [3, 3], scope = 'AvgPool_0a_3x3')
branch_3 = slim.conv2d(branch_3, 192, [1, 1], scope = 'Conv2d_0b_1x1')
# 192 + 192 + 192 + 192 = 768
net = tf.concat([branch_0, branch_1, branch_2, branch_3], 3)
'''
第二个Inception模块组:第三个Module
input:17x17x768
output:17x17x768
'''
with tf.variable_scope('Mixed_6c'):
with tf.variable_scope('Branch_0'):
branch_0 = slim.conv2d(net, 192, [1, 1], scope = 'Conv2d_0a_1x1')
with tf.variable_scope('Branch_1'):
branch_1 = slim.conv2d(net, 160, [1, 1], scope = 'Conv2d_0a_1x1')
branch_1 = slim.conv2d(branch_1, 160, [1, 7], scope = 'Conv2d_0b_1x7')
branch_1 = slim.conv2d(branch_1, 192, [7, 1], scope = 'Conv2d_0c_7x1')
with tf.variable_scope('Branch_2'):
branch_2 = slim.conv2d(net, 160, [1, 1], scope = 'Conv2_0a_1x1')
branch_2 = slim.conv2d(branch_2, 160, [7, 1], scope = 'Conv2d_0b_7x1')
branch_2 = slim.conv2d(branch_2, 160, [1, 7], scope = 'Conv2d_0c_1x7')
branch_2 = slim.conv2d(branch_2, 160, [7, 1], scope = 'Conv2d_0d_7x1')
branch_2 = slim.conv2d(branch_2, 192, [1, 7], scope = 'Conv2d_0e_1x7')
with tf.variable_scope('Branch_3'):
branch_3 = slim.avg_pool2d(net, [3, 3], scope = 'AvgPool_0a_3x3')
branch_3 = slim.conv2d(branch_3, 192, [1, 1], scope = 'Conv2d_0b_1x1')
# 192 + 192 + 192 + 192 = 768
net = tf.concat([branch_0, branch_1, branch_2, branch_3], 3)
'''
第二个Inception模块组:第四个Module(与第三个结构相同)
input:17x17x768
output:17x17x768
'''
with tf.variable_scope('Mixed_6d'):
with tf.variable_scope('Branch_0'):
branch_0 = slim.conv2d(net, 192, [1, 1], scope = 'Conv2d_0a_1x1')
with tf.variable_scope('Branch_1'):
branch_1 = slim.conv2d(net, 160, [1, 1], scope = 'Conv2d_0a_1x1')
branch_1 = slim.conv2d(branch_1, 160, [1, 7], scope = 'Conv2d_0b_1x7')
branch_1 = slim.conv2d(branch_1, 192, [7, 1], scope = 'Conv2d_0c_7x1')
with tf.variable_scope('Branch_2'):
branch_2 = slim.conv2d(net, 160, [1, 1], scope = 'Conv2_0a_1x1')
branch_2 = slim.conv2d(branch_2, 160, [7, 1], scope = 'Conv2d_0b_7x1')
branch_2 = slim.conv2d(branch_2, 160, [1, 7], scope = 'Conv2d_0c_1x7')
branch_2 = slim.conv2d(branch_2, 160, [7, 1], scope = 'Conv2d_0d_7x1')
branch_2 = slim.conv2d(branch_2, 192, [1, 7], scope = 'Conv2d_0e_1x7')
with tf.variable_scope('Branch_3'):
branch_3 = slim.avg_pool2d(net, [3, 3], scope = 'AvgPool_0a_3x3')
branch_3 = slim.conv2d(branch_3, 192, [1, 1], scope = 'Conv2d_0b_1x1')
# 192 + 192 + 192 + 192 = 768
net = tf.concat([branch_0, branch_1, branch_2, branch_3], 3)
'''
第二个Inception模块组:第四个Module(与第三个结构相同)
input:17x17x768
output:17x17x768
'''
with tf.variable_scope('Mixed_6e'):
with tf.variable_scope('Branch_0'):
branch_0 = slim.conv2d(net, 192, [1, 1], scope = 'Conv2d_0a_1x1')
with tf.variable_scope('Branch_1'):
branch_1 = slim.conv2d(net, 192, [1, 1], scope = 'Conv2d_0a_1x1')
branch_1 = slim.conv2d(branch_1, 192, [1, 7], scope = 'Conv2d_0b_1x7')
branch_1 = slim.conv2d(branch_1, 192, [7, 1], scope = 'Conv2d_0c_7x1')
with tf.variable_scope('Branch_2'):
branch_2 = slim.conv2d(net, 192, [1, 1], scope = 'Conv2d_0a_1x1')
branch_2 = slim.conv2d(branch_2, 192, [7, 1], scope = 'Conv2d_0b_7x1')
branch_2 = slim.conv2d(branch_2, 192, [1, 7], scope = 'Conv2d_0c_1x7')
branch_2 = slim.conv2d(branch_2, 192, [7, 1], scope = 'Conv2d_0d_7x1')
branch_2 = slim.conv2d(branch_2, 192, [1, 7], scope = 'Conv2d_0e_1x7')
with tf.variable_scope('Branch_3'):
branch_3 = slim.avg_pool2d(net, [3, 3], scope = 'AvgPool_0a_3x3')
branch_3 = slim.conv2d(branch_3, 192, [1, 1], scope = 'Conv2d_0b_1x1')
# 192 + 192 + 192 + 192 = 768
net = tf.concat([branch_0, branch_1, branch_2, branch_3], 3)
end_points['Mixed_6e'] = net
'''
第三个Inception模块组:第一个Module
input:17x17x768
output:8x8x1280
'''
with tf.variable_scope('Mixed_7a'):
with tf.variable_scope('Branch_0'):
branch_0 = slim.conv2d(net, 192, [1, 1], scope = 'Conv2d_0a_1x1')
branch_0 = slim.conv2d(branch_0, 320, [3, 3], stride = 2, padding = 'VALID', scope = 'Conv2d_1a_3x3')
with tf.variable_scope('Branch_1'):
branch_1 = slim.conv2d(net, 192, [1, 1], scope = 'Conv2d_0a_1x1')
branch_1 = slim.conv2d(branch_1, 192, [1, 7], scope = 'Conv2d_0b_1x7')
branch_1 = slim.conv2d(branch_1, 192, [7, 1], scope = 'Conv2d_0c_7x1')
branch_1 = slim.conv2d(branch_1, 192, [3, 3], stride = 2, padding = 'VALID', scope = 'Conv2d_1a_3x3')
with tf.variable_scope('Branch_2'):
branch_2 = slim.max_pool2d(net, [3, 3], stride = 2, padding = 'VALID', scope = 'MaxPool_la_3x3')
# 320 + 192 + 768 = 1280
net = tf.concat([branch_0, branch_1, branch_2], 3)
'''
第三个Inception模块组:第二个Module
input:8x8x1280
output:8x8x2048
'''
with tf.variable_scope('Mixed_7b'):
with tf.variable_scope('Branch_0'):
branch_0 = slim.conv2d(net, 320, [1, 1], scope = 'Conv2d_0a_1x1')
with tf.variable_scope('Branch_1'):
branch_1 = slim.conv2d(net, 384, [1, 1], scope = 'Conv2d_0a_1x1')
branch_1 = tf.concat([
slim.conv2d(branch_1, 384, [1, 3], scope = 'Conv2d_0b_1x3'),
slim.conv2d(branch_1, 384, [3, 1], scope = 'Conv2d_0b_3x1')], 3)
with tf.variable_scope('Branch_2'):
branch_2 = slim.conv2d(net, 448, [1, 1], scope = 'Conv2d_0a_1x1')
branch_2 = slim.conv2d(branch_2, 384, [3, 3], scope = 'Conv2d_0b_3x3')
branch_2 = tf.concat([
slim.conv2d(branch_2, 384, [1, 3], scope = 'Conv2d_0c_1x3'),
slim.conv2d(branch_2, 384, [3, 1], scope = 'Conv2d_0c_3x1')], 3)
with tf.variable_scope('Branch_3'):
branch_3 = slim.avg_pool2d(net, [3, 3], scope = 'AvgPool_0a_3x3')
branch_3 = slim.conv2d(branch_3, 192, [1, 1], scope = 'Conv2d_0b_1x1')
# 320 + 384*2 + 384*2 + 192 = 2048
tf.concat([branch_0, branch_1, branch_2, branch_3], 3)
'''
第三个Inception模块组:第三个Module(与第二个完全一样)
input:8x8x2048
output:8x8x2048
'''
with tf.variable_scope('Mixed_7c'):
with tf.variable_scope('Branch_0'):
branch_0 = slim.conv2d(net, 320, [1, 1], scope = 'Conv2d_0a_1x1')
with tf.variable_scope('Branch_1'):
branch_1 = slim.conv2d(net, 384, [1, 1], scope = 'Conv2d_0a_1x1')
branch_1 = tf.concat([
slim.conv2d(branch_1, 384, [1, 3], scope = 'Conv2d_0b_1x3'),
slim.conv2d(branch_1, 384, [3, 1], scope = 'Conv2d_0b_3x1')], 3)
with tf.variable_scope('Branch_2'):
branch_2 = slim.conv2d(net, 448, [1, 1], scope = 'Conv2d_0a_1x1')
branch_2 = slim.conv2d(branch_2, 384, [3, 3], scope = 'Conv2d_0b_3x3')
branch_2 = tf.concat([
slim.conv2d(branch_2, 384, [1, 3], scope = 'Conv2d_0c_1x3'),
slim.conv2d(branch_2, 384, [3, 1], scope = 'Conv2d_0c_3x1')], 3)
with tf.variable_scope('Branch_3'):
branch_3 = slim.avg_pool2d(net, [3, 3], scope = 'AvgPool_0a_3x3')
branch_3 = slim.conv2d(branch_3, 192, [1, 1], scope = 'Conv2d_0b_1x1')
# 320 + 384*2 + 384*2 + 192 = 2048
tf.concat([branch_0, branch_1, branch_2, branch_3], 3)
return net, end_points
定义Inception V3网络的最后一部分:
# Inception V3网络的最后一部分
def incepiton_v3(inputs,
num_class = 1000,
is_training = True,
dropout_keep_prob = 0.8,
prediction_fn = slim.softmax,
spatial_squeeze = True,
reuse = None,
scope = 'InceptionV3'):
'''
inputs: 输入
num_class: 最后需要分类的总数
is_training: 标志是否是训练过程,对BN和Dropout有影响
dropout_keep_prob: 保留节点的比例
prediction_fn: 用来分类的函数
spatial_squeeze: 是否要将型如5x3x1--->5x3
reuse: 标志是否会对网络和Variable进行重复使用
scope: 包含函数默认参数的环境
'''
with tf.variable_scope(scope, 'InceptionV3', [inputs, num_class], reuse = reuse) as scope:
# 使用slim.arg_scope进行默认初始化设置
with slim.arg_scope([slim.batch_norm, slim.dropout], is_training = is_training):
net, end_points = inception_v3_base(inputs, scope = scope)
with slim.arg_scope([slim.conv2d, slim.max_pool2d, slim.avg_pool2d], stride = 1, padding = 'SAME'):
aux_logits = end_points['Mixed_6e'] # 辅助分类结点
with tf.variable_scope('AuxLogits'):
# 进行池化
aux_logits = slim.avg_pool2d(aux_logits, [5, 5], stride = 3, padding = 'VALID', scope = 'AvgPool_1a_5x5')
# 进行卷积
aux_logits = slim.conv2d(aux_logits, 128, [1, 1], scope = 'Conv2d_1b_1x1')
aux_logits = slim.conv2d(aux_logits, 768, [5, 5],
weights_initializer = trunc_normal(0.01),
padding = 'VALID', scope = 'Conv2d_2a_5x5')
aux_logits = slim.conv2d(aux_logits, num_class, [1, 1],
activation_fn = None,
weights_initializer = trunc_normal(0.001),
scope = 'Conv2d_2b_1x1')
if spatial_squeeze:
# [1, 2]表示把第2,3维出现的1去掉(前提得2,3本就存在1)
aux_logits = tf.squeeze(aux_logits, [1, 2], name = 'SpatialSqueeze')
end_points['AuxLogits'] = aux_logits
with tf.variable_scope('Logits'):
# 直接对Mixed_7e即最后一个卷积层的输出进行操作
net = slim.avg_pool2d(net, [8, 8], padding = 'VALID', scope = 'AvgPool_1a_8x8')
net = slim.dropout(net, keep_prob = dropout_keep_prob, scope = 'Dropout_1b')
end_points['PreLogits'] = net
logits = slim.conv2d(net, num_class, [1, 1], activation_fn = None,
normalizer_fn = None, scope = 'Conv2d_1c_1x1')
if spatial_squeeze:
logits = tf.squeeze(logits, [1, 2], name = 'SpatialSqueeze')
end_points['Logits'] = logits
# 使用softmax函数预测
end_points['Predictions'] = prediction_fn(logits, scope = 'Predictions')
return logits, end_points
定义耗时:
# 计算耗时
def time_tensorflow_run(session, target, info_string):
num_steps_burn_in = 10 # 打印阈值
total_duration = 0.0 # 每一轮所需要的迭代时间
total_duration_aquared = 0.0 # 每一轮所需要的迭代时间的平方
for i in range(num_batches + num_steps_burn_in):
start_time = time.time()
_ = session.run(target)
duration = time.time() - start_time # 计算耗时
if i >= num_steps_burn_in:
if not i % 10:
print("%s : step %d, duration = %.3f" % (datetime.now(), i - num_steps_burn_in, duration))
total_duration += duration
total_duration_aquared += duration * duration
mn = total_duration / num_batches # 计算均值
vr = total_duration_aquared / num_batches - mn * mn # 计算方差
sd = math.sqrt(vr) # 计算标准差
print("%s : %s across %d steps, %.3f +/- %.3f sec/batch" % (datetime.now(), info_string, num_batches, mn, sd))
测试:
注:CNN的训练都是比较耗时的,所以这里也就是测试一下几张随机生成图的前向和反向传播过程
batch_size = 32
height, width = 299, 299
inputs = tf.random_uniform((batch_size, height, width, 3))
# 加载前面定义好的inception_v3_arg_scope()
with slim.arg_scope(inception_v3_arg_scope()):
logits, end_points = incepiton_v3(inputs, is_training = False)
with tf.Session() as sess:
init = tf.global_variables_initializer()
sess.run(init)
num_batches = 100
time_tensorflow_run(sess, logits, "Forward")
运行效果:
2019-01-22 13:02:51.088969 : step 0, duration = 0.231
2019-01-22 13:02:53.406683 : step 10, duration = 0.231
2019-01-22 13:02:55.725737 : step 20, duration = 0.233
2019-01-22 13:02:58.050072 : step 30, duration = 0.231
2019-01-22 13:03:00.372407 : step 40, duration = 0.233
2019-01-22 13:03:02.694779 : step 50, duration = 0.234
2019-01-22 13:03:05.019621 : step 60, duration = 0.232
2019-01-22 13:03:07.343221 : step 70, duration = 0.234
2019-01-22 13:03:09.665730 : step 80, duration = 0.232
2019-01-22 13:03:11.990585 : step 90, duration = 0.233
2019-01-22 13:03:14.090070 : Forward across 100 steps, 0.232 +/- 0.001 sec/batch
[1] Szegedy C, Vanhoucke V, Ioffe S, et al. Rethinking the inception architecture for computer vision[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2016: 2818-2826.
[2] Tensorflo实战.黄文坚,唐源
如果觉得我有地方讲的不好的或者有错误的欢迎给我留言,如果对您有帮助,帮我点个赞哦~,感谢大家阅读