Jaxp是sun公司提供的针对dom和sax的解析器,同时jaxp也是JavaSE的一部分,在JDK的javax.xml.parsers包里,对dom有DocumentBuilder类和DocumentBuilderFactory类。
一、DocumentBuilder类
1、DocumentBuilder类是dom解析器类,同时也是 抽象类, 不可以通过new来获取该类实例,而是通过DocumentBuilderFactory.newDocumentBuilder()来获取实例
2、解析xml方法:
parse("xml路径")
返回是 Document 整个文档, 返回的document是一个接口,父节点是Node,如果在document里面找不到想要的方法,到Node里面去找
3、在document里的常用方法
#获取标签,返回集合 NodeList
getElementsByTagName(String tagname)
# 创建标签
createElement(String tagName)
#创建文本
createTextNode(String data)
#把文本添加到标签下面
appendChild(Node newChild)
#删除节点
removeChild(Node oldChild)
#获取父节点
getParentNode()
# 得到标签里面的内容
getTextContent()
NodeList常用方法
NodeList list
#得到集合的长度
getLength()
#下标取到具体的值
item(int index)
二、DocumentBuilderFactory类
DocumentBuilderFactory类是解析器工厂类,它也是抽象类,不可以通过new来获取该类的实例,通过方法newInstance()获取DocumentBuilderFactory的实例
三、jaxp的dom操作
对以下一个简单的xml文件进行操作
<?xml version="1.0" encoding="ISO-8859-1" standalone="no"?>
<person>
<p>
<name>zhangsna</name>
<age>20</age>
</p>
<p>
<name>lisi</name>
<sex>nv</sex>
</p>
</person>1、查询操作(查询name属性值)
public static void Chaxum() throws ParserConfigurationException, IOException, SAXException {
//创建解析工厂
DocumentBuilderFactory builderFactory= DocumentBuilderFactory.newInstance();
//创建解析器
DocumentBuilder builder =builderFactory.newDocumentBuilder();
//解析xml返回document
Document document=builder.parse("src/people.xml");
//得到name元素
NodeList list=document.getElementsByTagName("name");
//循环获得每一个name元素里的值
for(int i=0;i<list.getLength();i++){
Node name1=list.item(i);
String s=name1.getTextContent();
System.out.println(s);
}
}运行结果:

2、添加操作
在第一个p标签内添加一个<sex>nan<sex>
public static void add() throws IOException, SAXException, ParserConfigurationException, TransformerException {
//创建解析工厂
DocumentBuilderFactory builderFactory= DocumentBuilderFactory.newInstance();
//创建解析器
DocumentBuilder builder =builderFactory.newDocumentBuilder();
//解析xml返回document
Document document=builder.parse("src/people.xml");
//得到第一个p标签
Node list= (Node) document.getElementsByTagName("p").item(0);
//创建sex标签
Node sex1=document.createElement("sex");
//创建文本
Node s=document.createTextNode("nan");
//把文本添加到sex下面
sex1.appendChild(s);
//把sex添加到第一个p1下面
list.appendChild(sex1);
//回写xml
TransformerFactory transformerFactory=TransformerFactory.newInstance();
Transformer transformer=transformerFactory.newTransformer();
transformer.transform(new DOMSource(document),new StreamResult("src/people.xml"));
}运行后xml文件如下:
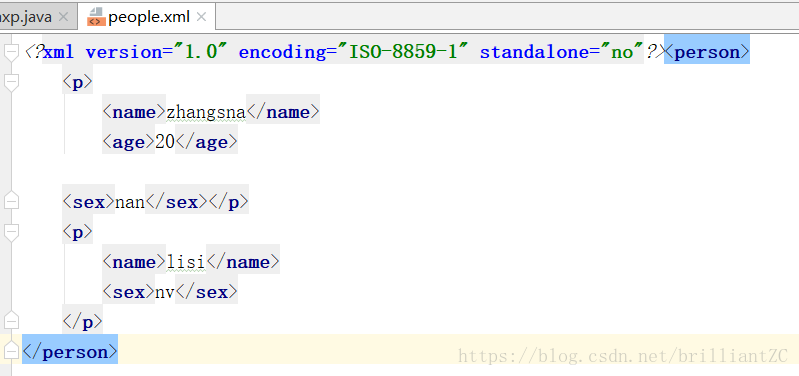
此时确实将<sex>nan<sex>添加了进去,但是jaxp对于格式化操作很弱,所以xml代码会乱掉
3、删除操作
将刚添加的<sex>nan<sex>删去
public static void remove() throws ParserConfigurationException, IOException, SAXException, TransformerException {
//创建解析工厂
DocumentBuilderFactory builderFactory= DocumentBuilderFactory.newInstance();
//创建解析器
DocumentBuilder builder =builderFactory.newDocumentBuilder();
//解析xml返回document
Document document=builder.parse("src/people.xml");
//获取sex元素
Node sex1= (Node) document.getElementsByTagName("sex").item(0);
//获取sex的父节点
Node parentnode=sex1.getParentNode();
//删除使用父节点删除
parentnode.removeChild(sex1);
//回写xml
TransformerFactory transformerFactory=TransformerFactory.newInstance();
Transformer transformer=transformerFactory.newTransformer();
transformer.transform(new DOMSource(document),new StreamResult("src/people.xml"));
}运行后xml文件如下:
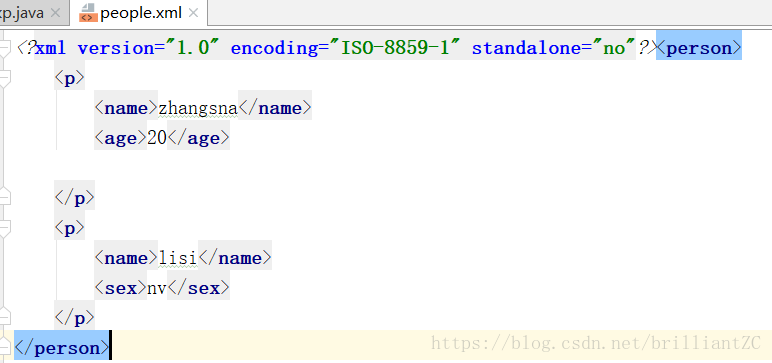
此时就删去了刚添加的<sex>nan<sex>,同样jaxp对于格式化操作很弱,所以xml代码会乱掉
4、替换操作
将第二个p标签下的<sex>nv<sex>换成<sex>nan<sex>
public static void replace() throws ParserConfigurationException, IOException, SAXException, TransformerException {
//创建解析工厂
DocumentBuilderFactory builderFactory= DocumentBuilderFactory.newInstance();
//创建解析器
DocumentBuilder builder =builderFactory.newDocumentBuilder();
//解析xml返回document
Document document=builder.parse("src/people.xml");
//获取sex元素
Node sex1= (Node) document.getElementsByTagName("sex").item(0);
//修改sex里面的值
sex1.setTextContent("nan");
//回写xml
TransformerFactory transformerFactory=TransformerFactory.newInstance();
Transformer transformer=transformerFactory.newTransformer();
transformer.transform(new DOMSource(document),new StreamResult("src/people.xml"));
}运行后xml文件如下:
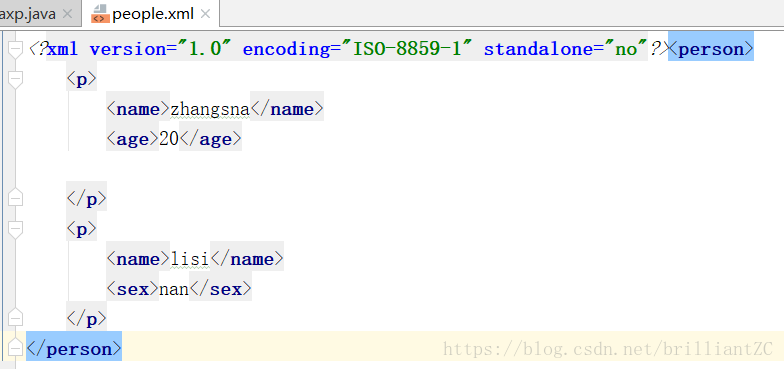
5、递归打印出所有元素
public static void listElement() throws ParserConfigurationException, IOException, SAXException {
//创建解析工厂
DocumentBuilderFactory builderFactory= DocumentBuilderFactory.newInstance();
//创建解析器
DocumentBuilder builder =builderFactory.newDocumentBuilder();
//解析xml返回document
Document document=builder.parse("src/people.xml");
//调用递归方法
digui(document);
}
public static void digui(Node node){
System.out.println(node.getNodeName());//打印元素
NodeList list=node.getChildNodes(); //得到一层子节点
for(int i=0;i<list.getLength();i++){
Node node1=list.item(i);
digui(node1);
}
运行结果:
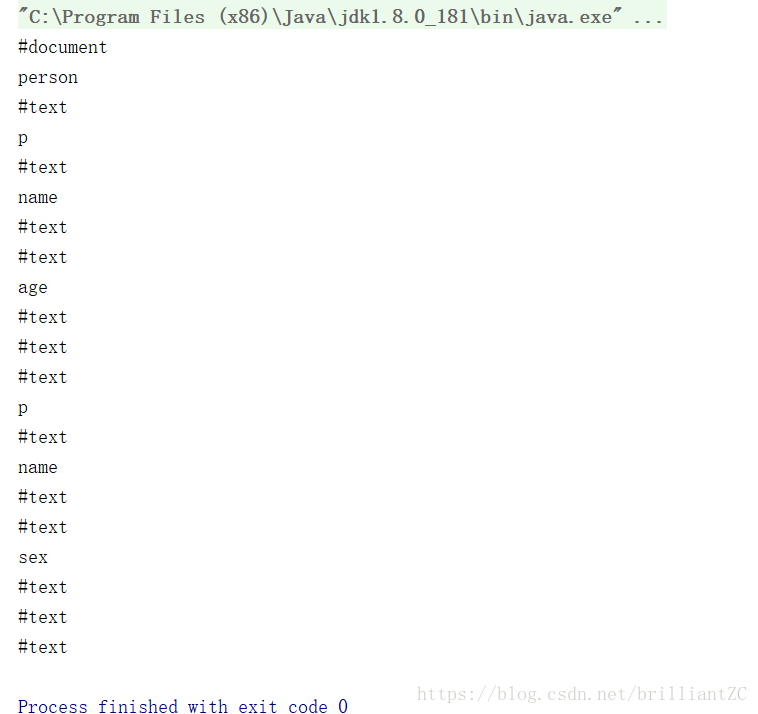
此时你会发现有很多#text,这是因为xml把空格和换行都当成内容去解析,所以会出现很多#text
你也可以在输出前加一个判断语句来规范输出:
if(node.getNodeType()==Node.ENTITY_NODE){ //判断是元素类型则进行打印
System.out.println(node.getNodeName());
}