https://www.cnblogs.com/pinard/p/7243513.html
http://www.cnblogs.com/pinard/p/7249903.html
- word2vec区别于one_hot映射方法,将词向量赋予含义并映射到向量空间,通过向量减法、点乘表示两词相差、相关性。
- 两种预测模型:Cbow(周围词向量预测中间词向量)和skip-gram(中间词向量预测周围词向量)。
- 两种训练模型:Hierachical softmax(huffman树)和negtive sampling(权重采样负例)。
- Hierachical softmax:(以Cbow为例, negative的区别只是一开始和误差叠加到一个向量。)
- 用huffman树代替传统神经网络, 速度快。但是对出现频率少对词需要对路径较长,比较慢。
- 按照词频构建哈夫曼树。
- 先把周围词向量加和,然后
为预测值。
- 顺着哈夫曼树走,与哈夫曼码比较。算梯度误差,累加误差给x,修正
。
推导过程:(人为规定左子树为负类0,右子树为负类1)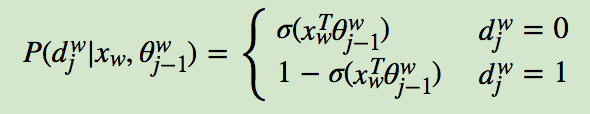
哈夫曼树往左走的时候,预测概率为1-sigmoid, 往右走为sigmoid。
先求似然函数,也就是(根据dj为0和为1记住)
取对数求导,得到梯度为1-d-sigmoid()。对于sita偏导数乘xi,对于xi偏导数乘sita。
修正sita,累加x。
- negtive sampling:以词频为依据赋权重建立单位线段。采用随机投影方式获取n个负样本。
- 将模型简化。
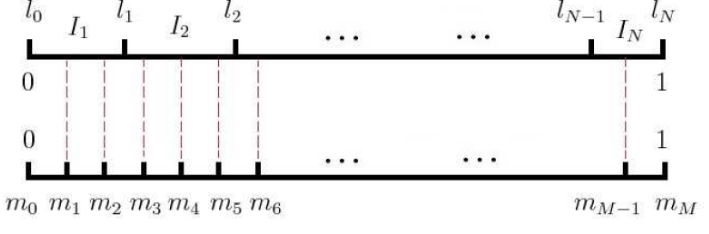
推导过程:假设上下文为y0=1,其他负例均为yi=0。

取对数求导得:采用梯度上升法,对sita导数为xi*(yi - sigmoid),对x为sita(yi-sigmoid)求和。