现在使用jpa的项目越来越多,它是封装的hibernate的高级类库,快捷的开发模式,让程序员脱离繁琐的sql语句,会让你爱不释手,下面进行介绍jpa的使用方法,让你快速入门
1.使用jpa的项目结构
下面进行按步骤介绍:.yml-----entity----dao
1.1 在yml中配置:
spring:
jpa:
hibernate:
ddl-auto: update
database: mysql
show-sql: true
database-platform: org.hibernate.dialect.MySQL5InnoDBDialect #改默认引擎
ddl-auto:成表的规则:
create 启动时删数据库中的表,然后创建,退出时不删除数据表
create-drop 启动时删数据库中的表,然后创建,退出时删除数据表 如果表不 存在报错
update 如果启动时表格式不一致则更新表,原有数据保留
jpa默认生产的表的引擎是:myisam引擎,所有进行修改引擎
2.jpa根据实体类自动生成表entity(最全注解)
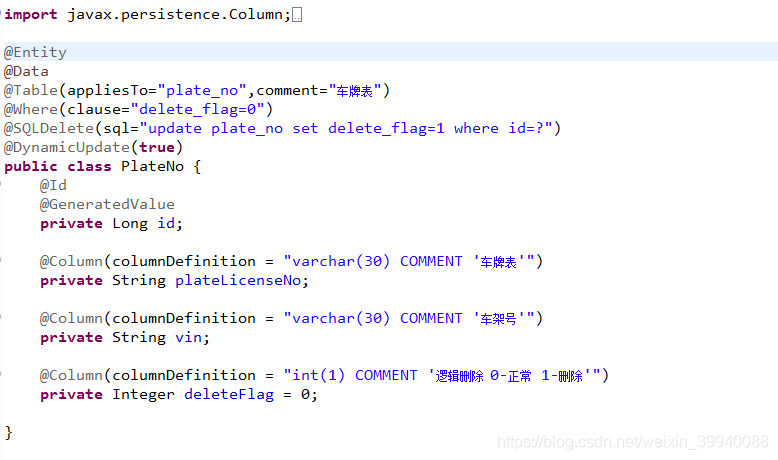
2.1创建一个实体类,在类上加注解
@entity 表明是个实体类
@Data是lombok注解,代替get,set
@Table()是导入的org.hibernate.annotations.Table;因为这个可以加表注解
appliesTo=“生成的表名”,comment=“表注解”,除此之外还有catalog 和 schema 用于设置表所属的数据库目录或模式,通常为数据库名
@where()和@SQLDelete用于逻辑删除,查询是自动添加where里的条件,具体可看实例
@DynamicUpdate (true)@DynamicInsert(true)表示更新和插入时只操作改变的数据,提高效率
2.2在id上加注解
@id表明是主键 @GeneratedValue(strategy = GenerationType.IDENTITY)
@GeneratedValue()提供主键生成策略,含两个属性strategy,generator(声明主键生成器名称,默认“”)
TABLE:使用一个特定的数据库表格来保存主键。
SEQUENCE:根据底层数据库的序列来生成主键,条件是数据库支持序列。
IDENTITY:主键由数据库自动生成(主要是自动增长型)
AUTO:主键由程序控制。
2.3在属性上加注解来生成表
@Column()用来生成表字段
name=“字段名”,length=“长度,varchar类型有效最大255”,nullable是否可为空,默认为true,unique是否唯一,默认为false ,updatable,insertable更新,插入时是否改变此字段,另一种可以加注解的写法colunmDifinition=“varchar(255),COMMENT ‘字段的注解’”
2.4其他注解
@LastModifiedDate @CreatedDate 自动填充创建时间更新时间
1.在实体类上加上注解@EntityListeners(AuditingEntityListener.class),
2.在application启动类中加上注解EnableJpaAuditing,
3.同时在需要的字段上加上@CreatedDate、@LastModifiedDate、
@DateTimeFormat(pattern = “yyyy-MM-dd HH:mm:ss”)几个注解

3.jpa封装的sql语句(写在dao里)
对于实体类User 在dao里创建public interface UserDao extends JpaRepository<User, Long>{},对于<操作的实体类,主键类型>,然后在接口里写方法就行了,不用写impl
3.1保存(封装好的,不用在dao接口里写任何方法,直接用)
UserDao .save(User),保存一个实体类,如果用User user= UserDao .save(User),来写,可以拿到id,user,getId(),这里是暂时保存在缓存区,事后会持久化,因为可能出现事务问题,建议使用下面的
UserDao.saveAndflush(User),保存并刷新直接写入数据库,不放缓存区
UserDao.saveAll(Users)这里是直接将一个集合写入数据库,
保存能用到的就这三个,全都是封装好的
3.2更新
如果是更新操作,依然用UserDao .save()几个操作,但在操作前要进行查找,找到要改变的实体类,再set更新的字段,然后调用save就是更新操作,他的底层原理是:如果要保存的对象的id字段存在值就进行更新,如果没有就进行保存,所以第一步查找的主要目的是拿到id值
3.3删除
UserDao .delete()就可以,逻辑删除,在@SQLdelete里写update方法,
3.4查找(写在UserDao里)
findBy+where后的条件
Optional yysArticle=yysArticleDao.findById(id);
YysArticle yysArticle=yysArticleDao.findById(id).get();也可以
根据字段查找:
List findByNameAndAge(String Name,Integer id);
User findByNameOrId(String Name,Integer id);
范围类:条件在参数里
findByDateBetween(String startdate,String enddate) between
findTop12ByStateNotOrderByCreatetimeDesc(String state)
sate不等于 后面不用加东西
findByAgeLessThan(Int age)age<? 小于
findByAgeGreaterThan(Int age)age>? 大于
findByAgeIn(Collection ages) 在集合中
findByAgeNotIn(Collection ages) 不在集合中
findFirst3ByNameOrderByAgeDesc 查询一到3条 也可不排序
findTop10ByName
判断类:
findByNameNot(String name) 不是时
findByNameIsNull() 为空时不用传参
findByNameNotNull() 为空时不用传参
findByNameLike(String name) 模糊查询名字
findByNameNotLike(String name)
注**:在使用模糊查询时,调用时传参加%**
UserDao.findByNameLike("%"+name+"%") 以此类推,可精确查找也可**?_来模糊匹配
排序类:
findByNameOrderBy**AgeDesc(String name) 根据年龄降序排列,
其他:返回众多数据的第一条:
findFirstByNameOrderByAgeDesc(String name) 不排序也行
计数:返回多少条数据:
Long countByName(String name)
4.jpa不使用封装的sql语句
如果你喜欢自己写sql也可以
@Query(value=“select order_id from flow_order_list where vin=1?”,nativeQuery=true)
public List findOrderIdByVin(String vin);
这样就可以了,nativeQuery=true意思是不使用原生的HQL
如果自己写修改和删除要在定义的方法上加上@Modifying 进行修饰. 以通知 SpringData, 这是一个 UPDATE 或 DELETE 操作
6.连表查询
表1:floor 实体类:Floor
表2:floor_c 实体类:FloorC
在映射表时要加上关联规则
FloorCDao:要连表查Floor表
FloorCDao. findBy Floor_Name And Name ();
Floor_Name是floor表的name Name是FloorC本表的Name
规则: 要关联的实体类_字段名
+++++++++++++++++++++++++++++++++++++++++
个人原创,复制转载请加上原博地址:
https://blog.csdn.net/weixin_39940088/article/details/84544840