视频列表:
24 汉语语料库的多级加工(一)
25 汉语语料库的多级加工(二)
26 汉语语料库的多级加工(三)
27 汉语语料库的多级加工(四)
28 汉语语料库的多级加工(五)
29 汉语语料库的多级加工(六)
30 汉语语料库的多级加工(七)
24 汉语语料库的多级加工(一)
第四章 汉语语料库的多级加工
语料库语言学
- 以语料库为主要资源从事语言研究
- 通过对大规模真实语料的调查来发现并总结自然语言的各种语言事实和语法规律
- 并非新的学科,而仅仅是一种研究手段
- 经常使用概率统计及信息论中的方法
语料库加工的意义
- 语料库的多级加工技术是语料库语言学研究的前沿课题。
- 它的处理目标是对生语料文本进行多级加工(分词、词性标注、句法分析、语义、语用分析等等)形成熟语料。
- 目的:大规模的语料库中提取应用所需要的各个语言单位上的语言学知识。
语料库功能的决定性因素
- 语料库的规模
语料库容量的大小直接影响到统计结果的可靠性 - 语料的分布
语料分布的考虑则关系到统计结果的适用范围 - 语料的加工深度
加工深度则决定了该语料库能为自然语言处理提供什么样的知识
示例 - 生语料
中国是一个大国 - 经多级加工后结果
(IP (NP-SBJ (NR 中国))
(VP (VC 是)(NP-PRD(QP (CD 一)
(CLP (M 个)))
(ADJP(JJ 大))
(NP(NN 国)))))
语料的加工顺序
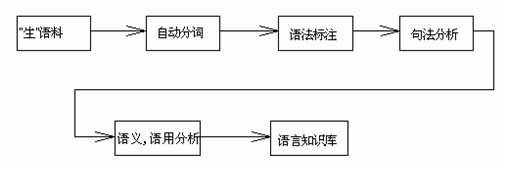
经过不同阶段的处理,语料库包含的各类信息也不断增加,最终将成为一个名副其实的语言知识库。这样的知识库可以为汉语统计分析、汉语理解和机器翻译等资源提供重要的资源和有力的支持
语料库的加工规范
- 北大计算语言学研究所1994年制订了《现代汉语文本切分与词性标注规范V1.0》
- 北大计算语言学研究所于1998年10月制订了《现代汉语文本切分与词性标注规范V2.0》
- 后改名为《现代汉语语料库加工规范》
现代汉语语料库加工规范主要内容
- 切分规范
- 切分和标注相结合的规范
- 标注规范
- 专有名词的标注
25 汉语语料库的多级加工(二)
分词
主要难点
切分歧义
- 交集型
- 覆盖型
未登录词
- 就是在词典中没有登录过的人名 地名,机构名, 新词语等
- 歧义切分字段在汉语书面文本中所占的比例并不很大,在实际的书面文本中,特别是在新闻类文本中,未登录词的处理是书面文本自动切分的一个十分突出的问题。这是汉语书面语自动切分的另一个难点
命名实体的识别方法
- 字串本身的特性
- 上下文特性
- 两者结合
示例:
“于中华”
于中华同志是湖南人
迎奥运活动今天于中华世纪坛举行
中国人名识别
人名用字的统计特征
根据统计, 汉语姓氏大约有1000多个, 姓氏中使用频度最高的是“王”姓, “王, 陈, 李, 张, 刘” 等5个大姓覆盖率达32%, 姓氏频度表中的前14个高频度的姓氏覆盖率为50%, 前400个姓氏覆盖率达99%。 人名的用字也比较集中。 频度最高的前6个字覆盖率达10.35%, 前10个字的覆盖率达14.936%, 前15个字的覆盖率达19.695%, 前400个字的覆盖率达90%。
- 第一次出现的人名叫做“定义性出现”,尔后出现的人名叫做“使用性出现”。 为此, 在切分时可根据人名在定义性出现时的限制性成分首先建立人名表
- 对定义性出现的识别是关键
上下文特征
- 人名的限制性成分主要有
身份词:表示人的职务,职位,头衔的词语和亲属称谓的词语。有的出现在人名之前,如“工人,教师,丈夫, 妻子,犯人”。有的出现在人名之后, 如“先生,女士”,有的可以出现在人名的前面和后面,如“教授,总理”
许多身份词带有后缀字,如“在逃犯, 理发员,面包师,目击者”中的“犯,员,师,者”等。
地名和单位名:如“浙江绍兴周树人, 国家语委冯志伟”
复杂的定语:如“德高望重的吕叔湘先生”。 - 根据这些限制性成分,可以有效地识别人名
- 中国姓氏用字中有的是专用作姓氏的,如“赵,邓,潘,冯”等,有的则兼作其他词语使用,如“顾,黄,周”等,对于兼作其他词语的姓氏,需要建立规则来判断。
示例:
“顾”兼作动词
记者顾小东
只顾短期的经济利益
规则:如果“顾”前有副词(只),则“顾”不为姓氏。
“黄”兼作形容词
黄曾阳研究概念层次网络
彩色的光带射到黄玻璃上
规则: 如果“黄”后有物质名词,则“黄”不为姓氏。
“周”兼作量词
由周恩来任国务院总理
地球自转一周
规则: 如果“周”前有数词, 则“周”不为姓氏。
外国人名识别
- 《英语姓名译名手册》中共收英语姓氏, 教名约4万个, 经计算机统计得出英语姓名译名用字表共476个
- 利用这个译名表,可初步确定外国人名在句子中的位置和边界。
-设任一连续汉字串C1…Ci…Cn (n1), 如果对所有的Ci (i=1,…,n),都有Ci 属于译名表,则初步可认为该汉字串为外国人名。
-初步确定外国人名之后,再根据人名前后的限制性成分,进一步确定外国人名的界限。
示例:
政府总理卢卡诺夫参加了庆祝活动
英国首相撒切尔夫人访问美国 - 根据译名表切分时会认为“理卢卡诺夫, 撒切尔夫”是外国人,得出错误的切分。这时,还要利用限制性成分“总理”和“夫人”,使译名表中的汉字不能作用于限制性成分“总理”和“夫人”之上,便可以得到正确的切分:“总理/卢卡诺夫”, “撒切尔/夫人”。
- 我们也可以利用只能出现在外国人名首和外国人名末的汉字作为特征字来判定外国人名的边界。这需要分别建立相应的字表来作为判定外国人名左右边界的依据
- 还可以利用简单的上下文来进一步判定外国人名的边界
标点符号,数字,空格,西文字母,译名连接符号常常是人名的边界。
人名经常出现在一些表示行为的动词之前,如“率,说,抵,离,报道,率领,会见, 表示,接受,指出,认为,发现,主持,呼吁,出席”等。
地名识别
- 地名用字的分布比人名用字分散,处理起来困难更大。
- 中国地名委员会编写了《中华人民共和国地名录》,收集了全国乡镇以上(含乡镇)各级行政区域的名称,以乡镇人民政府所在地为主的居民聚落名称,山、河、湖、海、岛、高原、盆地、沙溪等自然地理实体名称,名胜古迹、纪念地、古遗址、水库、桥梁、电站等名称。
- 《中华人民共和国地名录》共收录地名10万多条。这个地名录中使用的汉字共2662个,频度最高的前65个汉字占总频度的50.22%,前622个汉字占总频度的90.01%,前1872个汉字占总频度的99%。与人名的用字情况相比较,地名用字分散得多。
- 中国地名的自动识别主要利用地名用字的频度信息以及关联信息对侯选的地名用词进行筛选,再利用出现在地名后部的特征字“省、是、县、乡、镇、山、湖、河、海”等进行判定。
- 还可以利用地名的上下文信息进一步判定
某些动词和介词(如“到、在、位于”等)的后面常常出现地名:例如,“到北京,在上海,位于八达岭”。
某些方位词(如“附近、内外”等)的前面常常出现地名:例如,“海淀附近,长城内外”。
某些机构名(如“邮电局、派出所”等)前面常常出现地名:例如,“东四邮电局,朝阳门派出所”
机构名识别
- 主要是机关、团体和企业事业单位的名称。
- 机构名数目庞大,并且随着社会的发展而不断变化。
- 机构名一般都比较长,处理时首先应该弄清它的内部结构。机构名在语法上属于定中结构,在中心语前面加上一个或几个修饰语,这些修饰语可以是地名、人名、学科名、行业名。例如,“北京(地名)大学”、“白求恩(人名)医科(学科名)大学”、“汽车制造(行业名)厂”。
- 识别机构名时,首先应找到作为中心语的机构称呼词,然后由后往前逐个识别其修饰语,判定修饰语是否合法,在处理过程中,还需要进行浅层的句法语义分析。
26 汉语语料库的多级加工(三)
最大熵模型
- 典型的基于统计与规则相结合统计分类模型
- 核心思想:系统在满足约束的条件下,熵会趋向于最大,即系统趋向于更均匀。
基于最大熵模型的中文名实体识别
- 任务:对文档中的人名(name)、地名(place)、机构名(org)、时间(time)、日期(date)、货币(money)、数量(number)、比例(rate)进行识别,可以作为分词的后处理过程
- NE recognition 是一个有指导的分类过程,即类别集合是确定的。本系统采用的自己定义的标记集,共有33种类别
- 采用监督学习方法,训练集是一些带有标记的汉语块
例如:从 nt 国家专利局 o 聘请 nt 的 nt 科技 nt 副 nt 县长 nt 李 nf 芝 nc 生 ne
参考文献
Adam.L.Berger A maximum entropy approach to natural language processing
27 汉语语料库的多级加工(四)
汉语的兼类词
- 汉语中的兼类词只占汉语词汇的一小部分。《中学生词典》收词1.4万,兼类词有820个,占5.86%。
- 兼类词数量虽小,但大多是常用词。往往越是常用的词,不同的用法就越多,兼类现象也就越多
- 兼类词主要集中在名词、动词、形容词、副词等类词上。《中学生词典》中,“动-名”(例如“计划、报告”)、“动-形”(例如“繁荣、普及”)、“名-形”(例如“科学、秘密”)、“形-副”(例如“直、白”)、“动-副”(例如“断、还”)、“名-副”(例如“极端”)、“名-动-形”(例如“严肃、巩固”)等7种兼类现象,就占了820个兼类词的95.5%。
如果我们把力量放在主要兼类现象的处理上,就可以收到事半功倍的效果。 - 在汉语中,兼类词主要集中在动词、名词、形容词等常用词上。各种兼类现象的比例如下:
动词-名词兼类:37.6% 如:计划不如变化快-我计划去开会
动词-形容词兼类:24.3% 如:繁荣市场经济-市场经济繁荣
名词-形容词兼类:10.4% 如:满腔热情-对客人非常热情
形容词-副词兼类:4.55% 如:一定的水分-我一定去
动词-介词兼类:4.04% 如:我到北京开会-到目前为止
动词-副词兼类:2.27%
名词-动词-形容词兼类:2.27%
名词-副词兼类:2.02%
其他兼类现象:12.55%
词性标注
基于规则的方法主要根据句法、语义、上下文等语言学规则来消解兼类歧义。
基于规则的词性标注
- 主要依靠上下文来判定兼类词。
示例:
这是一张白纸(“白‘出现在名词”纸’之前,判定为形容词)
他白跑了一趟(“白”出现在动词“跑”之前,判定为副词) - 词性连坐:在并列的联合结构中,联合的两个成分的词类应该相同,如果其中一个为非兼类词,另一个为兼类词,则可把非兼类词的词性判定为兼类词的词性。
示例:
我读了几篇文章和报告
“文章”为名词,是非兼类词,“报告”为动-名兼类词,由于处于联合结构中,故可判定“报告”为名词。
基于隐马尔可夫模型(HMM)的词性标注器
- 从语料库中选出一定数量的文本,作为训练集(training set),手工分析这个训练集,采用二元语法(bi-gram grammar),从中归纳出统计数据。
- 根据对训练集的语料分析得出的统计数据,构造统计模型;
- 根据统计模型去标注语料库中新的文本。
基于转移的词性标注器
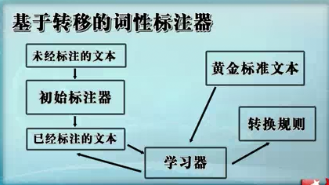
转换规则的两个组成部分
- 一个触发环境 (条件)
例如:前一个词是定冠词 - 一个改写规则 (采取的动作)

28 汉语语料库的多级加工(五)
基于转移的错误驱动学习系统的构成
一个初始标注器
例如:一个能够给每个词标上最大可能词性的词性标注器
转移模板
- 非词特征模板

- 词特征模板

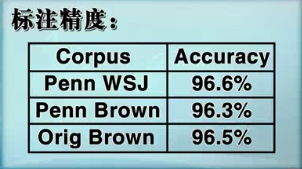
标注精度
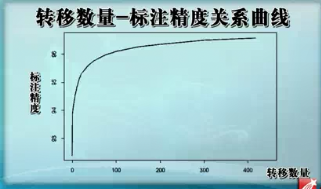
转移数量-标注精度关系曲线
基于转移的错误驱动的机器学习方法(TBL)
- 应用广泛
- 效果良好,但作用有限
- 可以作为一种辅助性的机器学习工具与其它分类器混合使用。
- 基于隐马尔科夫模型与TBL相结合的词性标注器
词性标注的其他方法
在上世纪90年代,词类标注问题得到了持续关注,不断有新的方法和模型提出,除我们介绍的方法外,下列方法也取得了较好的标注效果:
- 基于决策树(Schmid 1994)
- 基于神经元网络(Benello et al. 1989)
- 基于最大熵原则(Ratnaparkhi 1996)
短语定界和句法标注
句法分析的总体结构(清华大学,周强)
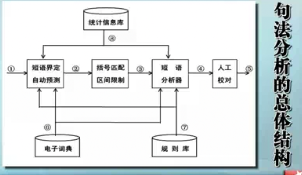
① 短语分析的输入数据:经过正确切词和词性标注处理的汉语句子。在正常情况下,每次分析一个输入句子。
② 短语界定预测输入数据:为输入句子中的每个词语预测产生了一个或多个短语界定,以此作为括号匹配的基础。
③括号匹配区间限制数据:在数据②上进一步附加了匹配区间限制数据,以进一步提高复杂句子的匹配处理效率。
④ 短语自动划分和标注结果:经过短语自动分析器处理数据③,得到了输入句子的最佳分析树,它们以匹配的括号对加上其短语标记的形式标注在句子的词语序列上。
⑤ 经过人工校对的正确短语划分和标注结果。
⑥ 词典信息数据:每个词语从词典中获得的复杂特征集描述,其基本形式为特征–值对。
⑦ 规则信息数据:对短语界定调整和分析器排歧所给出的各种特征约束规则。
示例:
- 输入语句
“安装/v 在/p 桌子/n 上/f 的/u 灯/n 亮/a 了/u ” - 经过短语界定
[安装/v [在/p [桌子/n 上/f] 的/u 灯/n] [亮/a 了/u]] - 经过括号匹配和区间限制
得到所有可能的局部分析树 - 经过短语分析器,得到最优分析树
[dj [np [vp 安装/v [pp 在/p [sp 桌子/n 上/f ]]] 的/u 灯/n ] [abar 亮/a 了/u ]]
29 汉语语料库的多级加工(六)
语义标注
什么是语义?
- 词的指称?心理图像、大脑图像或思想作为意义?说话者的意图作为意义?
- 我个人对“语义是语言符号使用者自认为所指的事物 ”比较认同
“所指事物”:语义的客观性因素
“自认为”:语义的主观性因素 - 语法与语义的关系
语法是形式
语义是内容 - 自动语义标注的工作
计算机对出现在一定上下文中的词语的语义进行判定,确定其正确的语义并加以标注。 - 确定词汇与其他词汇的关系
红楼梦与呼噜梦
语义判定
- 一词多义,形成了词的多义现象,自动语义标注主要是解决词的多义问题。
- 一词多义也是自然语言中的普遍现象,但是,在一定的上下文中,一个词一般只能解释为一种语义。
- 所谓自动语义标注,就是计算机对出现在一定上下文中的词语的语义进行判定,确定其正确的语义并加以标注。
- 以字义定词义:汉语中的绝大多数复合词,其字义与词义之间都有密切的联系,字义在词义中的作用十分明显,词义几乎等于它所包含的字义的相加,以少量的汉字来推知大量的词义,可以达到以简驭繁的效果。
示例:
“打”在现代汉语中是一个多义词,在《现代汉语词典》中,其义项达24项之多。
我们可以使用以字义定词义的方法来确定文本中“打”的词义。例如,“打鼓”中的“打”的字义是“用手或器具撞击物体”,“鼓”的字义是“打击乐器”,由此可以推知“打锣鼓”中“打”的词义。
其推理过程是:因为“打锣鼓”中的“锣鼓”与“打鼓”中的“鼓”在《同义词词林》中的语义分类相同,其代码都是BP13,“锣鼓”也是一种“打击乐器”,所以,可以推知“打锣鼓”中的“打”的词义是“用手或器具撞击物体”。 - 以单义词的词义定多义词的词义:如果某一单义词的义项包含在某个多义词的义项中,则可以根据单义词的搭配信息来确定在文本中多义词的义项。
示例:
“织毛衣”中的“织”是一个单义词,其义项是“用针使纱或线互相套住”,由此可以推知在“打毛衣”中的“打”的义项也是“用针使纱或线互相套住”,也就是“编织”。 - 利用词典条目的定义判断词义的亲和程度,从而确定多义词的词义
莱斯克(M. Lesk)提出利用既存的知识源来对多义词的义项进行优选。机器可读词典中词典条目的定义是一种既存的知识源,如果在两个单词的定义中都出现共同的词语,便可推断它们之间的亲和程度较大,从而据此优选出多义词的义项。
示例:
在英语中,pen是一个多义词,可以理解为“笔”,也可以理解为“动物的围栏”,如果在一个句子中既有pen,又有sheep,而在机器可读词典的pen 的定义中有“an enclosure in which domestic animals are kept”,在sheep的定义中有“There are many breeds of domestic sheep”,在这两个定义中都存在共同出现的单词domestic,从而可以判断,在这个句子中, pen的含义应该是“动物的围栏”,而不是“笔”,从而正确地确定了多义词pen 的义项。
英语attend是一个多义动词,其意义或者为“出席”,或者为“护理”,当它后面的名词的语义为“会议、宴会”,其义项取“出席”,当它后面的名词的语义为“人”时,其义项取“护理”。
在句子“ I attend a ceremony”中,名词 ceremony的语义为“会议、宴会”,所以,应翻译为“我参加典礼”;
在句子“Which doctor is attending this patient?”中,名词 patient的语义为“人”,所以,应翻译为“哪位医生护理这个病人?”为了采用这种上下文搭配关系的方法,需要认真研究动词和名词的搭配关系,并且还要结合这样的搭配关系建立名词的语义分类系统,使名词的语义分类系统与动词名词的搭配关系有机地结合起来,而不是貌合神离,或者各行其道。
词汇间语义关系
关系是词汇语义的灵魂
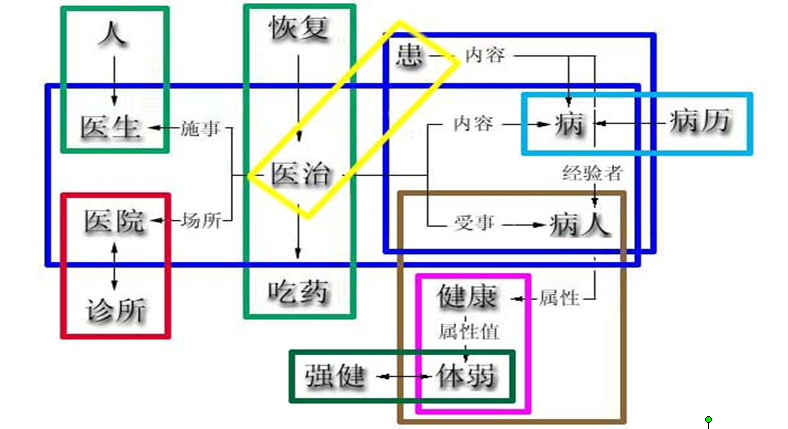
- Hownet (www.keenage.com)董振东等
上下位关系(X is a kind of Y)
整体-部分关系(X is a part of Y)
同义关系(X is a Y)
反义关系(举例:美 丑(多为a))
对义关系(举例:得到 失去(多为v))
等等
30 汉语语料库的多级加工(七)
语义标注举例
他在书店里看书。
semantic tree:
[(word_no=7,SENTENCE,)[SEN(word_no=4,看,v,vv2,2241101)[LOC(word_no=2,书店,n,sss,1132041)OBJ(word_no=5,书,n,nn1,1121)AGT(word_no=0,他,r,rr1,11111041)]]]
现有的语义资源举例
语义标注语料库
- Propbank
是在Penn TreeBank句法分析的基础上,对与动词有关的语义角色进行标注,包含50多个语义角色类型
语义知识库
- 英语
Wordnet
Mindnet
Framenet
加州大学伯克利分校构建,采用框架语义学为理论基础构建的英语语义词典 - 汉语
Hownet
中文Wordnet
中文Framenet
山西大学刘开瑛
汉语语料库多级加工系统
- 自动切词和词性标注子系统
- 自动短语定界和句法标注子系统
- 自动语义标注子系统
- 辅助工具,如:查询工具、样本采取工具、统计工具、语料库管理界面
人机互助的语料加工模型
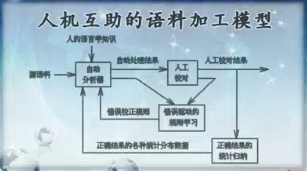
此模型具有以下几个特点:
- 普遍性知识和特殊性知识相结合
当正确标注的语料达到一定规模以后,从中统计得到的分布数据近似地反映了语言中的一些普遍规律,将这些数据运用于自动标注处理,可以期望获得较高的处理正确率。但语言是千变万化的,具有许多特例。因此系统配备了一个由错误驱动的规则学习程序,通过将自动处理结果和人工校对结果相比较,发现错误所在,从中可以总结归纳出若干特殊情况的处理规则。这样,将统计得到的普遍性知识和学习得到的特殊性知识相结合,可以大大提高自动标注处理的性能。 - 人机处理相结合
机器处理的优势在于它有强大的计算能力,可以大规模地处理语料。而人工标注的优势则在于它的精确性,因为人能利用上下文信息和知识来排歧。这两方面的优势在图1 所示的模型中都得到了充分的发挥:一是利用统计数据,构造适当的统计模型进行自动标注处理;二是通过人工校对,保证最终处理语料的正确性。而对于错误校正规则的学习,则要经历一个由手工到半自动再到全自动的发展过程。最初是人工总结,随着研究的深入,可以逐步利用一些统计工具降低人工处理的工作量,当技术成熟时,就可以利用机器学习技术自动习得有用的规则。 - 具有整体性能的增量提高性
- 随着正确标注语料规模的不断扩大,将使统计数据反映的信息更加全面,错误校正规则的条件约束更为精确,从而提高了自动标注处理的正确率,降低了人工校对的工作量,使系统的整体性能得到增强。
致谢
关毅老师,现为哈工大计算机学院语言技术中心教授,博士生导师。通过认真学习了《自然语言处理(哈工大 关毅 64集视频)》1(来自互联网)的课程,受益良多,在此感谢关毅老师的辛勤工作!为进一步深入理解课程内容,对部分内容进行了延伸学习2 3 4,在此分享,期待对大家有所帮助,欢迎加我微信(验证:NLP),一起学习讨论,不足之处,欢迎指正。

参考文献
《自然语言处理(哈工大 关毅 64集视频)》(来自互联网) ↩︎
王晓龙、关毅 《计算机自然语言处理》 清华大学出版社 2005年 ↩︎
哈工大语言技术平台云官网:http://ltp.ai/ ↩︎
Steven Bird,Natural Language Processing with Python,2015 ↩︎