一、简介
本文是总结Oracle查询优化方法与改写技巧的第三篇文章,接着第二篇文章,继续。。。
二、优化技巧
【1】日期加减运算方法
--日期加减
select sysdate as today, --今天
sysdate + 1 as tomorrow, --明天
sysdate - 1 as yesterday, --昨天
add_months(sysdate, 1 * 12) as nextyear, --明年
add_months(sysdate, -1 * 12) as previousyear --去年
from dual;
【2】时、分、秒日期加减运算方法
--时分秒加减 一天24小时, 1小时 = 1 / 24 1分钟 = 1 / 24 /60 1秒钟 = 1 / 24 / 60 / 60
with temp as
(select sysdate as now from dual)
select t.now,
(t.now + 1 / 24) as next_hours, --后一小时
(t.now - 2 / 24) as prev_two_hours, --前两小时
(t.now + 1 / 24 / 60) as next_minute, --后一分钟
(t.now - 2 / 24 / 60) as prev_two_minutes, --前两分钟
(t.now + 10 / 24 / 60 / 60) as next_second, --后10秒
(t.now - 20 / 24 / 60 / 60) as prev_two_seconds --前20秒
from temp t;
【3】时间间隔计算方法
小时、分钟时间间隔计算方法:
with temp as
(select sysdate as time1, sysdate + 20 as time2 from dual)
--计算天、小时、分钟间隔时间
select t.time1,
t.time2,
(t.time2 - t.time1) as nm, --相隔天数
(t.time2 - t.time1) * 24 as hours, --相隔的小时数
(t.time2 - t.time1) * 24 * 60 as minutes --相隔的分钟数
from temp t;
年、月、日时间间隔计算方法:
with temp as
(select sysdate as time1, sysdate + 20 as time2 from dual)
--计算时、分、秒间隔时间
select t.time1,
t.time2,
(t.time2 - t.time1) as days, --相隔的天数
months_between(t.time2, t.time1) as mons, --相隔的月份数
months_between(t.time2, t.time1) / 12 as years --相隔的年份数
from temp t;


【4】计算一年中周内各日期的次数
这个问题就是统计一年中有多少个星期一、多少个星期二、、、
(a)第一步:统计一年中有多少天
select r.startdate, r.enddate, (r.enddate - r.startdate) as days
from (select trunc(sysdate, 'yy') as startdate,
add_months(trunc(sysdate, 'yy'), 12) as enddate
from dual) r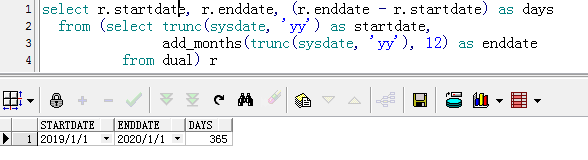
(b)第二步:生成日期列表
select (tt.startdate + (level - 1)) as rq
from (select r.startdate, r.enddate, (r.enddate - r.startdate) as days
from (select trunc(sysdate, 'yy') as startdate,
add_months(trunc(sysdate, 'yy'), 12) as enddate
from dual) r) tt
connect by level <= tt.days
(c)第三步:转换每天对应的周几
select (tt.startdate + (level - 1)) as rq,
to_char(tt.startdate + (level - 1), 'DY') as weeks
from (select r.startdate, r.enddate, (r.enddate - r.startdate) as days
from (select trunc(sysdate, 'yy') as startdate,
add_months(trunc(sysdate, 'yy'), 12) as enddate
from dual) r) tt
connect by level <= tt.days
(d)第四步:统计数量
select count(*), ttt.weeks
from (select (tt.startdate + (level - 1)) as rq,
to_char(tt.startdate + (level - 1), 'DY') as weeks
from (select r.startdate,
r.enddate,
(r.enddate - r.startdate) as days
from (select trunc(sysdate, 'yy') as startdate,
add_months(trunc(sysdate, 'yy'), 12) as enddate
from dual) r) tt
connect by level <= tt.days) ttt
group by ttt.weeks

【5】确定当前记录与下一条记录日期的间隔时间
要实现这个查询,要使用到lead() over()分析函数 或者 lag() over()函数:
--计算当前记录与下一条、上一条日期字段的时间间隔
select e.empno,
e.ename,
e.deptno,
lag(e.hiredate) over(order by e.hiredate) as pre_hiredate, --上一条记录
e.hiredate,
lead(e.hiredate) over(order by e.hiredate) as next_hiredate --下一条记录
from emp e

统计间隔天数:
--计算当前记录与下一条、上一条日期字段的时间间隔
select r.ename,
r.deptno,
r.pre_hiredate,
r.hiredate,
r.next_hiredate,
(r.next_hiredate - r.pre_hiredate) as days
from (select e.empno,
e.ename,
e.deptno,
lag(e.hiredate) over(order by e.hiredate) as pre_hiredate, --上一条记录
e.hiredate,
lead(e.hiredate) over(order by e.hiredate) as next_hiredate --下一条记录
from emp e) r
【6】常用的一些日期函数
(a) to_char()函数:
select sysdate,
to_char(sysdate, 'yyyy-mm-dd hh24:mi:ss') as 格式化日期, --当前日期
to_char(sysdate, 'yyyy') as 当前年份, --当前年份
to_char(sysdate, 'mm') as 当前月份, --当前月份
to_char(sysdate, 'dd') as 当前天, --当前天
to_char(sysdate, 'hh24') as 当前小时数, --当前小时数
to_char(sysdate, 'mi') as 当前分钟数, --当前分钟数
to_char(sysdate, 'ss') as 当前秒数, --当前秒数
to_char(sysdate, 'ddd') as 年内第几天, --年内第几天
to_char(sysdate, 'month') as 月份, --月份
to_char(sysdate, 'day') as 当前星期几, --星期几
to_char(sysdate, 'dy') as 当前星期几, --星期几
from dual
(b)trunc()函数:
select sysdate,
trunc(sysdate, 'dd') as 当天, --当天
trunc(sysdate, 'day') as 周初, --周初
trunc(sysdate, 'mm') as 月初, --月初
trunc(sysdate, 'yy') as 年初, --年初
add_months(trunc(sysdate, 'mm'), 1) as 下月初, --下月初
last_day(sysdate) as 月末 --月末
from dual
注意:last_day()返回的时间的时分秒与日期的相同,不建议使用它作为时间区间条件的计算,假如要计算一个月内的所有时间,可以先计算这个月的月初与下个月的月初,然后计算两者之间的时间即可。sql如下:
select r.startdate, r.enddate, r.time1
from (select sysdate,
to_date('2019-1-5 00:00:00', 'yyyy-mm-dd hh24:mi:ss') as time1,
trunc(sysdate, 'mm') as startdate,
add_months(trunc(sysdate, 'mm'), 1) as enddate
from dual) r
where r.time1 >= r.startdate --月初
and r.time1 < r.enddate --下月初

(c) extract()函数:可以提取时间字段中的年、月、日、时、分、秒等,返回的是number类型的结果。
--extract()可以提取日期中的年、月、日、时、分、秒,但是提取时、分、秒必须使用时间戳才能获取
select extract(year from sysdate) as y, --年
extract(month from sysdate) as m, --月
extract(day from sysdate) as d, --日
extract(hour from systimestamp) as h, --时
extract(minute from systimestamp) as m, --分
extract(second from systimestamp) as s --秒
from dual;
注意点:提取时、分、秒必须要是时间戳类型的日期才能提取,否则报错,如下图:

【7】确定一年是否是闰年
思路:计算中二月份最后一天是28号还是29号就知道是闰年还是平年。
(1)第一步:获取今年年初的日期:
select trunc(sysdate, 'yyyy') as y,
from dual
(2)第二步:获取二月份的第一天日期和最后一天的日期:
select t.y,
add_months(t.y, 1) as firstday,
last_day(add_months(t.y, 1)) as lastday
from (select trunc(sysdate, 'yyyy') as y from dual) t
(3)第三步:得到二月份最后一天日期的日,判断是否是28或者29即可:
--计算今年是闰年还是平年
select t2.y,
t2.firstday,
t2.lastday,
to_char(t2.lastday, 'dd') as rq,
decode(to_number(to_char(t2.lastday, 'dd')), 28, '平年', '闰年') as rpn
from (select t.y,
add_months(t.y, 1) as firstday,
last_day(add_months(t.y, 1)) as lastday
from (select trunc(sysdate, 'yyyy') as y from dual) t) t2

【8】确定一年内属于周内某一天的所有日期
案例:要求返回本年度所有星期五的所有日期:
(1)第一步:使用connect by ..构造全年的日期:
--统计本年度所有周五的日期
select t2.startdate + (level - 1) as rq --因为要从第一天开始统计,所有要减一
from (select t.startdate, t.enddate, (t.enddate - t.startdate) as cnt --全年天数
from (select trunc(sysdate, 'yy') as startdate,
add_months(trunc(sysdate, 'yy'), 12) as enddate
from dual) t) t2
connect by level <= t2.cnt

(2)第二步:使用to_cahr(xxx,'d') = 6统计周五的日期:
--统计本年度所有周五的日期
select t4.rq
from (select t3.rq, to_number(to_char(t3.rq, 'd')) as nm
from (select t2.startdate + (level - 1) as rq --因为要从第一天开始统计,所有要减一
from (select t.startdate,
t.enddate,
(t.enddate - t.startdate) as cnt --全年天数
from (select trunc(sysdate, 'yy') as startdate,
add_months(trunc(sysdate, 'yy'), 12) as enddate
from dual) t) t2
connect by level <= t2.cnt) t3) t4
where t4.nm = 6
 .
.
- 注意点:统计星期几的时候,尽量使用to_char(xxx,'d'),因为to_char(xxx,'day')会受不同的字符集影响,返回的结果也不相同,所以使用to_char(xxxx,'d')可以避免因为字符集对结果集的影响。
【9】创建本月日历
(1)第一步:使用connect by ... 列出当前月份的所有日期
select t2.startdate + (level - 1) as rq
from (select t.startdate, t.enddate, (t.enddate - t.startdate) + 1 as ts
from (select trunc(sysdate, 'mm') as startdate,
last_day(trunc(sysdate, 'mm')) as enddate
from dual) t) t2
connect by level <= t2.ts
(2)第二步:统计每天日期对应第一周、星期几等数据
select t3.rq,
to_char(t3.rq, 'iw') as a, --属于第几周
to_char(t3.rq, 'dd') as b, --日号
to_number(to_char(t3.rq, 'd')) as c --周几 5 - 周四 6 - 周五 。。。
from (select t2.startdate + (level - 1) as rq
from (select t.startdate,
t.enddate,
(t.enddate - t.startdate) + 1 as ts
from (select trunc(sysdate, 'mm') as startdate,
last_day(trunc(sysdate, 'mm')) as enddate
from dual) t) t2
connect by level <= t2.ts) t3
(3)第三步:行转列显示本月日历
--本月日历
select max(case
when t4.c = 2 then
t4.b
else
null
end) as 周一,
max(case
when t4.c = 3 then
t4.b
else
null
end) as 周二,
max(case
when t4.c = 4 then
t4.b
else
null
end) as 周三,
max(case
when t4.c = 5 then
t4.b
else
null
end) as 周四,
max(case
when t4.c = 6 then
t4.b
else
null
end) as 周五,
max(case
when t4.c = 7 then
t4.b
else
null
end) as 周六,
max(case
when t4.c = 1 then
t4.b
else
null
end) as 周日
from (select t3.rq,
to_char(t3.rq, 'iw') as a, --属于第几周
to_char(t3.rq, 'dd') as b, --日号
to_number(to_char(t3.rq, 'd')) as c --周几 5 - 周四 6 - 周五 。。。
from (select t2.startdate + (level - 1) as rq
from (select t.startdate,
t.enddate,
(t.enddate - t.startdate) + 1 as ts
from (select trunc(sysdate, 'mm') as startdate,
last_day(trunc(sysdate, 'mm')) as enddate
from dual) t) t2
connect by level <= t2.ts) t3) t4
group by t4.a
order by t4.a

【10】计算指定年份的各个季度的开始时间和结束时间
思路:我们画一张图分析下要怎么统计出各个季度的起止时间:

通过上面的分析,就可以比较简单的写出下面的sql了:
(1)第一步:
select t.year, level as jd --当前第几季度
from (select to_date(extract(year from sysdate), 'yyyy') as year from dual) t
connect by level <= 4
(2)第二步:
select t2.year,
t2.jd,
add_months(t2.year, (t2.jd - 1) * 3) as startdate,
add_months(t2.year, (t2.jd * 3)) as 季度结束时间的后一天,
add_months(t2.year, (t2.jd * 3)) - 1 as enddate
from (select t.year, level as jd --当前第几季度
from (select to_date(extract(year from sysdate), 'yyyy') as year
from dual) t
connect by level <= 4) t2
【11】按照给定的时间单位过滤数据
案例:要求返回2月或12月聘用的员工信息,以及周二聘用的员工信息
思路:利用前面讲的to_char()函数将员工的聘用日期提取相应的月份信息、周几信息,然后再过滤即可。相应的sql如下:
select t.hiredate, t.sal, t.ename, t.month, t.week, t.weekstr
from (select e.hiredate,
e.ename,
e.sal,
to_char(e.hiredate, 'mm') as month,
to_number(to_char(e.hiredate, 'd')) as week, --注意要使用‘d’,这样不会受字符集影响
to_char(e.hiredate, 'day') as weekstr
from emp e) t
where t.month in ('02', '12') -- in ('2','12') 与 in ('02','12')的区别,查询结果都不一样
or t.week = 3
order by t.hiredate
【12】按指定间隔汇总数据
思路:使用to_char()和trunc()函数提取日期中的分钟之初以及算出每隔多少分钟的起始时间即可。
(1)第一步:构造测试数据
with temp as
(select to_date('2019-01-06 20:38:20', 'yyyy-mm-dd hh24:mi:ss') as times,
'a' as names
from dual
union all
select to_date('2019-01-06 20:48:50', 'yyyy-mm-dd hh24:mi:ss') as times,
'a' as names
from dual
union all
select to_date('2019-01-06 20:37:10', 'yyyy-mm-dd hh24:mi:ss') as times,
'a' as names
from dual
union all
select to_date('2019-01-06 20:44:00', 'yyyy-mm-dd hh24:mi:ss') as times,
'a' as names
from dual
union all
select to_date('2019-01-06 20:56:15', 'yyyy-mm-dd hh24:mi:ss') as times,
'a' as names
from dual)
select * from temp;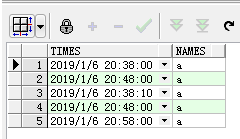
(2)第二步:提取相应的分钟数等
with temp as
(select to_date('2019-01-06 20:38:20', 'yyyy-mm-dd hh24:mi:ss') as times,
'a' as names
from dual
union all
select to_date('2019-01-06 20:48:50', 'yyyy-mm-dd hh24:mi:ss') as times,
'a' as names
from dual
union all
select to_date('2019-01-06 20:37:10', 'yyyy-mm-dd hh24:mi:ss') as times,
'a' as names
from dual
union all
select to_date('2019-01-06 20:44:00', 'yyyy-mm-dd hh24:mi:ss') as times,
'a' as names
from dual
union all
select to_date('2019-01-06 20:56:15', 'yyyy-mm-dd hh24:mi:ss') as times,
'a' as names
from dual)
select trunc(t.times, 'mi') as starttime,
to_char(t.times, 'mi') as minutes,
t.names
from temp t;
(3)第三步:计算相隔十分钟的时间并分组分别统计数量。
with temp as
(select to_date('2019-01-06 20:38:20', 'yyyy-mm-dd hh24:mi:ss') as times,
'a' as names
from dual
union all
select to_date('2019-01-06 20:48:50', 'yyyy-mm-dd hh24:mi:ss') as times,
'a' as names
from dual
union all
select to_date('2019-01-06 20:37:10', 'yyyy-mm-dd hh24:mi:ss') as times,
'a' as names
from dual
union all
select to_date('2019-01-06 20:44:00', 'yyyy-mm-dd hh24:mi:ss') as times,
'a' as names
from dual
union all
select to_date('2019-01-06 20:56:15', 'yyyy-mm-dd hh24:mi:ss') as times,
'a' as names
from dual)
select t3.mins, count(*)
from (select t2.mins
from (select trunc(t.times, 'mi') -
mod(to_char(t.times, 'mi'), 10) / 24 / 60 as mins --每隔十分钟
from temp t) t2) t3
group by t3.mins
order by t3.mins
【13】定位连续值的范围
案例:查询时间连续的数据
首先构造测试数据:
--定位连续值的范围
with temp as
(
select 1 as id,
to_date('2019-1-1', 'yyyy-mm-dd') as startdate,
to_date('2019-1-2', 'yyyy-mm-dd') as enddate
from dual
union all
select 2 as id,
to_date('2019-1-2', 'yyyy-mm-dd') as startdate,
to_date('2019-1-3', 'yyyy-mm-dd') as enddate
from dual
union all
select 3 as id,
to_date('2019-1-3', 'yyyy-mm-dd') as startdate,
to_date('2019-1-4', 'yyyy-mm-dd') as enddate
from dual
union all
select 4 as id,
to_date('2019-1-5', 'yyyy-mm-dd') as startdate,
to_date('2019-1-6', 'yyyy-mm-dd') as enddate
from dual
union all
select 5 as id,
to_date('2019-1-6', 'yyyy-mm-dd') as startdate,
to_date('2019-1-7', 'yyyy-mm-dd') as enddate
from dual
union all
select 6 as id,
to_date('2019-1-8', 'yyyy-mm-dd') as startdate,
to_date('2019-1-9', 'yyyy-mm-dd') as enddate
from dual)
select t.id, t.startdate, t.enddate from temp t;

如上,需要查询出符合enddate = 下一条记录.startdate的数据:
(1)第一种方法:使用自连接来实现:
--定位连续值的范围
with temp as
(select 1 as id,
to_date('2019-1-1', 'yyyy-mm-dd') as startdate,
to_date('2019-1-2', 'yyyy-mm-dd') as enddate
from dual
union all
select 2 as id,
to_date('2019-1-2', 'yyyy-mm-dd') as startdate,
to_date('2019-1-3', 'yyyy-mm-dd') as enddate
from dual
union all
select 3 as id,
to_date('2019-1-3', 'yyyy-mm-dd') as startdate,
to_date('2019-1-4', 'yyyy-mm-dd') as enddate
from dual
union all
select 4 as id,
to_date('2019-1-5', 'yyyy-mm-dd') as startdate,
to_date('2019-1-6', 'yyyy-mm-dd') as enddate
from dual
union all
select 5 as id,
to_date('2019-1-6', 'yyyy-mm-dd') as startdate,
to_date('2019-1-7', 'yyyy-mm-dd') as enddate
from dual
union all
select 6 as id,
to_date('2019-1-8', 'yyyy-mm-dd') as startdate,
to_date('2019-1-9', 'yyyy-mm-dd') as enddate
from dual)
--采用自关联查询连续的数据
select t1.id, t1.startdate, t1.enddate
from temp t1, temp t2
where t1.enddate = t2.startdate;

(2)第二种方法:使用分析函数来实现:
--定位连续值的范围
with temp as
(select 1 as id,
to_date('2019-1-1', 'yyyy-mm-dd') as startdate,
to_date('2019-1-2', 'yyyy-mm-dd') as enddate
from dual
union all
select 2 as id,
to_date('2019-1-2', 'yyyy-mm-dd') as startdate,
to_date('2019-1-3', 'yyyy-mm-dd') as enddate
from dual
union all
select 3 as id,
to_date('2019-1-3', 'yyyy-mm-dd') as startdate,
to_date('2019-1-4', 'yyyy-mm-dd') as enddate
from dual
union all
select 4 as id,
to_date('2019-1-5', 'yyyy-mm-dd') as startdate,
to_date('2019-1-6', 'yyyy-mm-dd') as enddate
from dual
union all
select 5 as id,
to_date('2019-1-6', 'yyyy-mm-dd') as startdate,
to_date('2019-1-7', 'yyyy-mm-dd') as enddate
from dual
union all
select 6 as id,
to_date('2019-1-8', 'yyyy-mm-dd') as startdate,
to_date('2019-1-9', 'yyyy-mm-dd') as enddate
from dual)
--采用分析函数查询连续的数据(效率高)
select t2.id, t2.startdate, t2.enddate
from (select t1.id,
t1.startdate,
t1.enddate,
lead(t1.startdate) over(order by t1.id) as next_startdate --取出下一条记录的开始时间
from temp t1) t2
where t2.next_startdate = t2.enddate --下一条记录的开始时间 = 该条记录的结束时间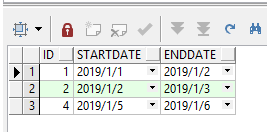
【14】查找同一组或分区中行之间的差
案例:要求计算同一个人本次登录时间与下一次登录时间相隔的时间差
首先构造测试数据:
--查找同一组或分区中行之间的差
--案例:要求计算同一个人本次登录时间与下一次登录时间相隔的时间差
with temp as
(
select 'a' as name,
to_date('2019-01-01 09:00:00', 'yyyy-mm-dd hh24:mi:ss') as logindate
from dual
union all
select 'b' as name,
to_date('2019-01-02 09:00:00', 'yyyy-mm-dd hh24:mi:ss') as logindate
from dual
union all
select 'a' as name,
to_date('2019-01-01 18:00:00', 'yyyy-mm-dd hh24:mi:ss') as logindate
from dual
union all
select 'b' as name,
to_date('2019-01-02 12:00:00', 'yyyy-mm-dd hh24:mi:ss') as logindate
from dual
union all
select 'a' as name,
to_date('2019-01-02 09:00:00', 'yyyy-mm-dd hh24:mi:ss') as logindate
from dual)
select * from temp t order by t.name, t.logindate
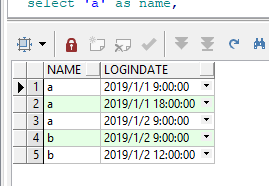
(1)第一种方法:使用rownum + 自连接的方法:
--查找同一组或分区中行之间的差
--案例:要求计算同一个人本次登录时间与下一次登录时间相隔的时间差
with temp as
(select 'a' as name,
to_date('2019-01-01 09:00:00', 'yyyy-mm-dd hh24:mi:ss') as logindate
from dual
union all
select 'b' as name,
to_date('2019-01-02 09:00:00', 'yyyy-mm-dd hh24:mi:ss') as logindate
from dual
union all
select 'a' as name,
to_date('2019-01-01 18:00:00', 'yyyy-mm-dd hh24:mi:ss') as logindate
from dual
union all
select 'b' as name,
to_date('2019-01-02 12:00:00', 'yyyy-mm-dd hh24:mi:ss') as logindate
from dual
union all
select 'a' as name,
to_date('2019-01-02 09:00:00', 'yyyy-mm-dd hh24:mi:ss') as logindate
from dual),
temp2 as
(select t2.*, rownum as rn
from (select t.* from temp t order by t.name, t.logindate) t2)
select t1.name,
t1.logindate, --本次登录时间
t2.logindate as nextlogindate, --下一次登录时间
(t2.logindate - t1.logindate) * 24 * 60 as minutes, --相隔的分钟数
t1.rn as 上一次rownum,
t2.rn as 下一次rownum
from temp2 t1
left join temp2 t2
on t1.name = t2.name
and t2.rn = t1.rn + 1;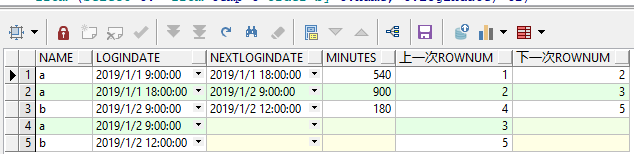
(2)第二种方法:使用lead() over()分析函数实现:
--查找同一组或分区中行之间的差
--案例:要求计算同一个人本次登录时间与下一次登录时间相隔的时间差
with temp as
(select 'a' as name,
to_date('2019-01-01 09:00:00', 'yyyy-mm-dd hh24:mi:ss') as logindate
from dual
union all
select 'b' as name,
to_date('2019-01-02 09:00:00', 'yyyy-mm-dd hh24:mi:ss') as logindate
from dual
union all
select 'a' as name,
to_date('2019-01-01 18:00:00', 'yyyy-mm-dd hh24:mi:ss') as logindate
from dual
union all
select 'b' as name,
to_date('2019-01-02 12:00:00', 'yyyy-mm-dd hh24:mi:ss') as logindate
from dual
union all
select 'a' as name,
to_date('2019-01-02 09:00:00', 'yyyy-mm-dd hh24:mi:ss') as logindate
from dual),
temp2 as
(select t2.* from (select t.* from temp t order by t.name, t.logindate) t2)
select t2.name,
t2.logindate,
t2.nextlogindate,
(t2.nextlogindate - t2.logindate) * 24 * 60 as minutes --使用分析函数效率比较高
from (select t1.name,
t1.logindate, --本次登录时间
lead(t1.logindate) over(partition by t1.name order by t1.logindate) as nextlogindate --按名称分区进行统计
from temp2 t1) t2

【15】模拟打卡记录,统计员工的上班时间和下班时间
--案例:统计每个员工的上班时间和下班时间
--以下是模拟打卡记录
with temp as
(select 'a' as name,
to_date('2019-01-01 09:00:00', 'yyyy-mm-dd hh24:mi:ss') as time
from dual
union all
select 'a' as name,
to_date('2019-01-01 09:10:00', 'yyyy-mm-dd hh24:mi:ss') as time
from dual
union all
select 'a' as name,
to_date('2019-01-01 12:00:00', 'yyyy-mm-dd hh24:mi:ss') as time
from dual
union all
select 'a' as name,
to_date('2019-01-01 18:00:00', 'yyyy-mm-dd hh24:mi:ss') as time
from dual
union all
select 'a' as name,
to_date('2019-01-02 09:00:00', 'yyyy-mm-dd hh24:mi:ss') as time
from dual
union all
select 'a' as name,
to_date('2019-01-02 12:00:00', 'yyyy-mm-dd hh24:mi:ss') as time
from dual
union all
select 'a' as name,
to_date('2019-01-02 12:00:00', 'yyyy-mm-dd hh24:mi:ss') as time
from dual
union all
select 'b' as name,
to_date('2019-01-01 10:00:00', 'yyyy-mm-dd hh24:mi:ss') as time
from dual
union all
select 'b' as name,
to_date('2019-01-01 18:00:00', 'yyyy-mm-dd hh24:mi:ss') as time
from dual
union all
select 'b' as name,
to_date('2019-01-02 09:00:00', 'yyyy-mm-dd hh24:mi:ss') as time
from dual
union all
select 'b' as name,
to_date('2019-01-02 18:00:00', 'yyyy-mm-dd hh24:mi:ss') as time
from dual
union all
select 'c' as name,
to_date('2019-01-02 09:00:00', 'yyyy-mm-dd hh24:mi:ss') as time
from dual)
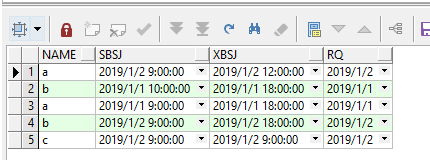
--统计每个员工的上班时间和下班时间
select t2.name, min(t2.time) as sbsj, max(t2.time) as xbsj, t2.rq
from (select t.name, t.time, trunc(t.time, 'dd') as rq from temp t) t2
group by t2.rq, t2.name;
【16】给结果集分页
oracle分页是基于rownum来进行分页的。
案例:假设每页显示5条数据,需要查询emp表6-10条的数据
(1)第一步:按员工工资排好序
--第一步:按员工工资排好序
select e.empno, e.ename, e.sal
from emp e
where e.sal is not null
order by e.sal
(2)第二步:排序后生成rownum排序号
--第二步:排序后生成rownum排序号
select rownum as pxh, t.empno, t.ename, t.sal
from (select e.empno, e.ename, e.sal
from emp e
where e.sal is not null
order by e.sal) t
where rownum <= 10
(3)第三步:使用嵌套子查询过滤rownum >= 6的数据
--第三步:使用嵌套子查询过滤rownum >= 6的数据
select t2.pxh, t2.empno, t2.ename, t2.sal
from (select rownum as pxh, t.empno, t.ename, t.sal
from (select e.empno, e.ename, e.sal
from emp e
where e.sal is not null
order by e.sal) t
where rownum <= 10) t2
where t2.pxh >= 6
- 注意点1:必须要排好序之后再次生成rownum作为排序号才正确
--注意:必须要排好序之后再次生成rownum作为排序号才正确
select rownum as pxh2, t2.pxh1, t2.empno, t2.ename, t2.sal
from (select rownum as pxh1, e.empno, e.ename, e.sal
from emp e
where e.sal is not null
order by e.sal) t2
- 注意点2:必须在外层使用rownum >= 6才能正确过滤数据,不能使用rownum >= 6 and rownum <= 10进行判断,因为rownum是先有数据才能生成的
--注意:必须在外层使用rownum >= 6才能正确过滤数据,不能使用rownum >= 6 and rownum <= 10进行判断,因为rownum是先有数据才能生成的
select count(*) from emp e;
--错误使用方法
select count(*) --统计不出数据
from emp e
where rownum <= 10
and rownum >= 6;
--正确使用方法
select count(*)
from (select rownum as rn --先有数据rownum才能确定是多少
from (select * from emp e where e.sal is not null order by e.sal) t) t2
where t2.rn <= 10
and t2.rn >= 6;【17】跳过n条记录
案例:隔行返回emp表的数据
select t4.*
from (select t3.*, mod(t3.rn, 3) as flag --第三步:使用求余函数mod(rn,x)隔x行显示
from (select rownum as rn, t2.* --第二步:使用rownum生成排序号
from (select * from emp e order by e.ename) t2) t3) t4 --第一步: 排序
where t4.flag = 1 --第四步:数据过滤,实际项目中根据需求随机抽取样本数据
【18】找到包含最大值和最小值的记录
案例:查询工资最高和最低的员工信息
(1)第一种方法:使用min()/max()函数实现
select *
from emp e
where e.sal in (select min(sal) as sal
from emp e
union all
select max(sal) as sal
from emp e)
(2)第二种方法:使用min() over() / max() over()分析函数实现
select *
from (select e.sal,
e.ename,
e.empno,
e.hiredate,
e.deptno,
e.job,
e.mgr,
min(sal) over() as minsal,
max(sal) over() as maxsal
from emp e) t
where t.sal in (t.minsal, t.maxsal)
【19】行转列
oracle中可以使用case when then end子句和oracle 11g之后新增的pivot函数来实现行转列功能
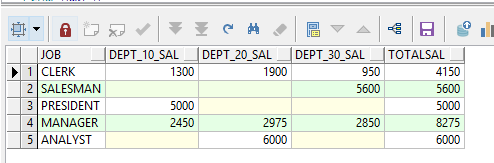
案例:对emp表按job分组,每个部门显示为一列
(1)第一种方法:使用case when then end子句实现
--行转列实现 case when then end..
select e.job,
sum(case
when e.deptno = 10 then
e.sal
else
null
end) as dept_10_sal,
sum(case
when e.deptno = 20 then
e.sal
else
null
end) as dept_20_sal,
sum(case
when e.deptno = 30 then
e.sal
else
null
end) as dept_30_sal,
sum(e.sal) as totalsal
from emp e
group by e.job
(2)第二种方法:使用pivot()函数实现
--行转列实现 pivot
--pivot无法实现合计工资的计算
--pivot只能按照一个条件进行分组统计,如果需要按照两个条件进行统计的话只能使用case when then end..子句
select *
from (select e.deptno, e.sal, e.job from emp e)
pivot(sum(sal) as sal
for deptno in(10 as dept_10, 20 as dept_20, 30 as dept_30))

- 注意点1:pivot无法实现合计工资的计算。
- 注意点2:pivot只能按照一个条件进行分组统计,如果需要按照两个条件进行统计的话只能使用case when then end..子句。
- 注意点3:pivot使用场景比较局限,而case when then end子句适用场景比较广,实际项目中,根据具体需求选择其中一种方式实现即可。
【20】列转行
首先构造测试数据:
with temp as
(select *
from (select e.deptno, e.sal from emp e)
pivot(count(*) as cnt, sum(sal) as dept_sal
for deptno in(10 as dept_10, 20 as dept_20, 30 as dept_30)))
select * from temp;
案例:要求三个部门的次数分为一列进行展示
(1)第一种方法:使用union all实现,但是这种方式效率不是特别高,尤其是字段多数据量大的情况下。
with temp as
(select *
from (select e.deptno, e.sal from emp e)
pivot(count(*) as cnt, sum(sal) as dept_sal
for deptno in(10 as dept_10, 20 as dept_20, 30 as dept_30)))
--select * from temp;
select 10 as deptno, dept_10_cnt as sal
from temp t
union all
select 20 as deptno, dept_20_cnt as sal
from temp t
union all
select 30 as deptno, dept_30_cnt as sal from temp t
(2)第二种方法:使用unpivot函数实现
with temp as
(select *
from (select deptno, sal from emp e)
pivot(count(*) as cnt, sum(sal) as dept_sal
for deptno in(10 as dept_10, 20 as dept_20, 30 as dept_30)))
select deptno, cnt
from temp t unpivot(cnt for deptno in(dept_10_cnt,
dept_20_cnt,
dept_30_cnt));
注意:unpivot同样只能处理一个条件,如果同时需要将工资和人次都转为一列显示。只能分别转换后再进行join连接即可。
思路:可以先拆分为两个分别按工资、人次unpivot的sql,然后再进行join
--按人次统计
with temp as
(select *
from (select deptno, sal from emp e)
pivot(count(*) as cnt, sum(sal) as dept_sal
for deptno in(10 as dept_10, 20 as dept_20, 30 as dept_30)))
select substr(deptno, 0, 7) as deptno, cnt
from temp t unpivot include nulls(cnt for deptno in(dept_10_cnt,
dept_20_cnt,
dept_30_cnt));
--按工资统计
with temp as
(select *
from (select deptno, sal from emp e)
pivot(count(*) as cnt, sum(sal) as dept_sal
for deptno in(10 as dept_10, 20 as dept_20, 30 as dept_30)))
select substr(deptno, 0, 7) as deptno, sal
from temp t unpivot(sal for deptno in(dept_10_dept_sal,
dept_20_dept_sal,
dept_30_dept_sal));
下面的sql就是内连接之后的sql:
with temp as
(select *
from (select deptno, sal from emp e)
pivot(count(*) as cnt, sum(sal) as dept_sal
for deptno in(10 as dept_10, 20 as dept_20, 30 as dept_30)))
select a.deptno, a.cnt, b.sal
from (select substr(deptno, 0, 7) as deptno, cnt
from temp t unpivot include nulls(cnt for deptno in(dept_10_cnt,
dept_20_cnt,
dept_30_cnt))) a
inner join (select substr(deptno, 0, 7) as deptno, sal
from temp t unpivot include nulls(sal for deptno in(dept_10_dept_sal,
dept_20_dept_sal,
dept_30_dept_sal))) b
on a.deptno = b.deptno如果不想使用内连接,也可以同时使用两次unpivot,但是主要要加上过滤条件,因为两次unpivot之后的是笛卡尔积。
--两个unpivot返回的笛卡尔积,上面的unpivot之后再进行unpivot
with temp as
(select *
from (select deptno, sal from emp e)
pivot(count(*) as cnt, sum(sal) as dept_sal
for deptno in(10 as dept_10, 20 as dept_20, 30 as dept_30)))
select *
from (select substr(deptno1, 0, 7) as deptno1,
substr(deptno2, 0, 7) as deptno2,
cnt,
sal
from temp t unpivot include nulls(cnt for deptno1 in(dept_10_cnt,
dept_20_cnt,
dept_30_cnt)) unpivot(sal for deptno2 in(dept_10_dept_sal,
dept_20_dept_sal,
dept_30_dept_sal)))
where deptno1 = deptno2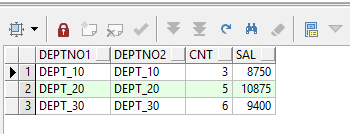
三、总结
这是第三部分的总结以及一些案例,后续会接着总结。积少成多,keeping....