什么是支持向量机
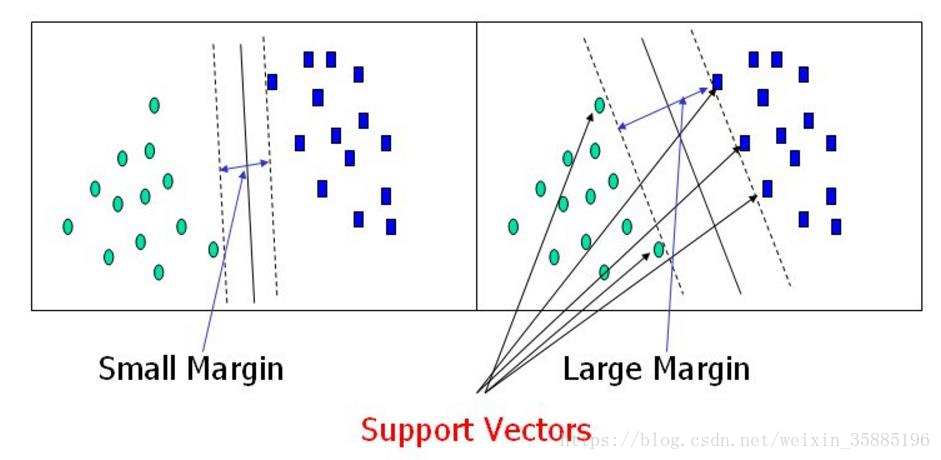
支持向量机是分类算法,目标是确立一个超平面来切分数据,(超平面在二维中是一条线,在三维中是一个面,以此类推),并且这个分类的边界要足够好,即离分割边界最近的数据点到分割边界的距离要越远越好(前提是所有的分类都是正确的,加入软间隔后可忽略部分离群点)。如图
点到面的距离
点到面的距离公式看这个链接:https://www.cnblogs.com/graphics/archive/2010/07/10/1774809.html
总之我们得到点到面的公式是
PQ 表示点P到平面上的点Q的向量,n表示平面的法向量
目标函数
- 设超平面的的一般公式为 , 等于法线量n
- 可表示为 , 由于 是平面上的点,所以 , ,
- 那么
- 要求 (距离超平面最近的点,求出的距离有可能是负的,加上绝对值)
- 假设
- 那么
- 通过放缩使得 ,那么距离最近的点的距离可表示为
- 最近的点的距离表示出来了,那么现在要求w和b使得这个距离最大,求 ,这就是我们的目标函数
目标函数求解(拉格朗日乘子法)
- 求解目标:
- 约束条件:
- 转换为求极小值: =>
- 拉格朗日求子法(有约束条件下的极值求法)
- 套公式转换为
- 设 ,那么 的最优解就是
- 因此问题转换成
- 根据拉格朗日乘子法对偶性质:
- 求解
- 在L(w,b,a)对w求偏导
- 在L(w,b,a)对b求偏导
- 代入L(w,b,a) 得
- 求解
- 转化为求极小值
- 注意条件
- 将实际中的数据,代入到
- 对每个 求偏导=0的值,可求出每个 的值,其中满足 的点为支持向量的点
- 利用支持向量的点的 的值,求出w,b,即最终的结果
软间隔soft-margin
引入松弛因子,C,C越大,越严格,分类错误越小,但是可能过拟合,C越大,容忍错误越大
核变换
低纬度不可分,转换为高维进行切分
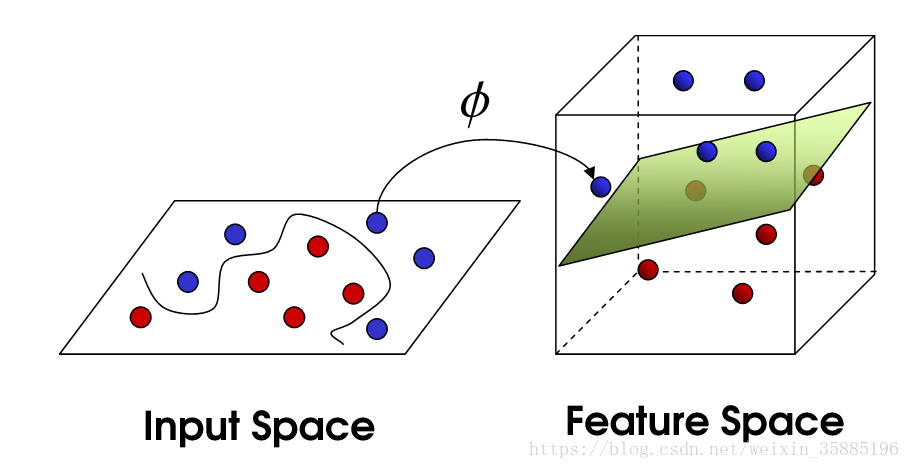
- 常用核函数 参考:https://blog.csdn.net/wsj998689aa/article/details/47027365
- 1.线性核 Linear Kernel (以一条直线切分)
- 2.多项式核 Polynomial Kernel (适合于正交归一化后的数据)
- 3.高斯核Gaussian Kernel
- 4.Exponential Kernel 指数核函数就是高斯核函数的变种,它仅仅是将向量之间的L2距离调整为L1距离
使用sklearn.SVM
import numpy as np
import matplotlib.pyplot as plt
from scipy import stats
import seaborn as sns; sns.set()
# 构造数据
from sklearn.datasets.samples_generator import make_blobs
X, y =make_blobs(n_samples=50, centers=2, random_state=0,cluster_std=0.60)
plt.scatter(X[:,0],X[:,1], c=y, s=50, cmap='autumn')
# 训练一个线性核SVM
from sklearn.svm import SVC
model = SVC(kernel='linear')
model.fit(X, y)
#绘图函数,用于绘制svm训练结果曲线
def plot_svc_decision_function(model, ax=None, plot_support=True):
if ax is None:
ax = plt.gca()#Get Current Axes获取当前轴线
xlim = ax.get_xlim()
ylim = ax.get_ylim()
# create grid to evaluate model
x = np.linspace(xlim[0], xlim[1], 30)
y = np.linspace(ylim[0], ylim[1], 30)
Y, X = np.meshgrid(y, x)
xy = np.vstack([X.ravel(), Y.ravel()]).T
P = model.decision_function(xy).reshape(X.shape)
# plot decision boundary and margins
ax.contour(X, Y, P, colors='k',
levels=[-1, 0, 1], alpha=0.5,
linestyles=['--', '-', '--'])
# plot support vectors
if plot_support:
ax.scatter(model.support_vectors_[:, 0],
model.support_vectors_[:, 1],
s=300, linewidth=1, facecolors='none');
ax.set_xlim(xlim)
ax.set_ylim(ylim)
#绘制散点图
plt.scatter(X[:,0],X[:,1],c=y,s=50,cmap='autumn')
# 绘制model的结果
plot_svc_decision_function(model)
#支持向量的点
print(model.support_vectors_)
# 生成圆形的散点数据,举例rbf和函数
from sklearn.datasets.samples_generator import make_circles
X, y = make_circles(100, factor=.1,noise=.1)
clf =SVC(kernel='rbf',C=10,gamma=1).fit(X,y)
plt.scatter(X[:,0],X[:,1],c=y,s=50,cmap='autumn')
plot_svc_decision_function(clf, plot_support=False)- 参数说明
sklearn.svm.SVC(C=1.0, kernel=’rbf’, degree=3, gamma=’auto’, coef0=0.0, shrinking=True, probability=False,
tol=0.001, cache_size=200, class_weight=None, verbose=False, max_iter=-1, decision_function_shape=None,random_state=None)
参数:
l C:C-SVC的惩罚参数C?默认值是1.0
C越大,相当于惩罚松弛变量,希望松弛变量接近0,即对误分类的惩罚增大,趋向于对训练集全分对的情况,这样对训练集测试时准确率很高,但泛化能力弱。C值小,对误分类的惩罚减小,允许容错,将他们当成噪声点,泛化能力较强。
l kernel :核函数,默认是rbf,可以是‘linear’, ‘poly’, ‘rbf’, ‘sigmoid’, ‘precomputed’
0 – 线性:u’v
1 – 多项式:(gamma*u’*v + coef0)^degree
2 – RBF函数:exp(-gamma|u-v|^2)
3 –sigmoid:tanh(gamma*u’*v + coef0)
l degree :多项式poly函数的维度,默认是3,选择其他核函数时会被忽略。
l gamma : ‘rbf’,‘poly’ 和‘sigmoid’的核函数参数。默认是’auto’,则会选择1/n_features
l coef0 :核函数的常数项。对于‘poly’和 ‘sigmoid’有用。
l probability :是否采用概率估计?.默认为False
l shrinking :是否采用shrinking heuristic方法,默认为true
l tol :停止训练的误差值大小,默认为1e-3
l cache_size :核函数cache缓存大小,默认为200
l class_weight :类别的权重,字典形式传递。设置第几类的参数C为weight*C(C-SVC中的C)
l verbose :允许冗余输出?
l max_iter :最大迭代次数。-1为无限制。
l decision_function_shape :‘ovo’, ‘ovr’ or None, default=None3
l random_state :数据洗牌时的种子值,int值
主要调节的参数有:C、kernel、degree、gamma、coef0。
问题
- 什么是支持向量
- 为什么要使用对偶