前言
pytest-html报告中当用到参数化时候,获取用例的nodeid里面有中文时候,会显示[\u6350\u52a9\u6211\u4eec]这种编码(再次声明,这个不叫乱码,这是unicode编码)
关于python2和python3里面Unicode编码转化可以参考之前写的一篇【python笔记6-%u60A0和\u60a0类似unicode解码】
本篇以python3.6版本为例
遇到问题
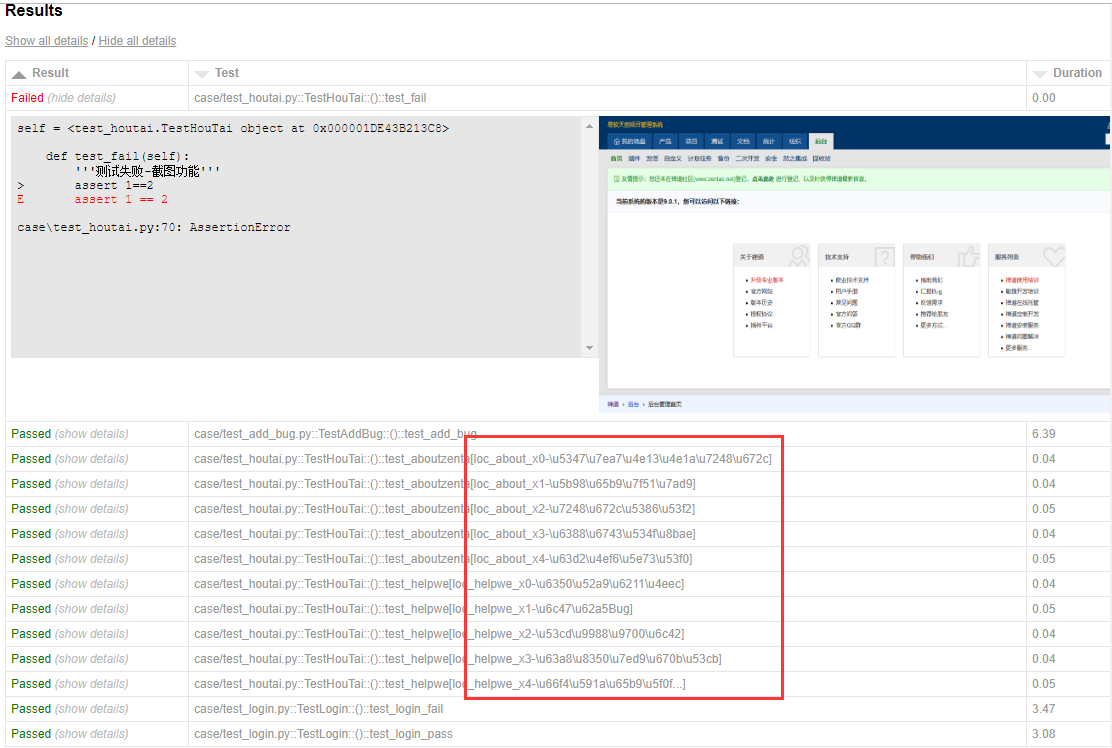
官网文档https://github.com/pytest-dev/pytest-html上说明如下:
注意ANSI代码支持取决于ansi2html包,此包不作为依赖项包含在内。如果你安装了这个软件包,那么ANSI代码会在你的报告中被转换成HTML。
试过了,安装ansi2html包也无法解决问题,于是只有自己解码,重新优化报告内容了
编码转化
相关转化参考这篇【python笔记6-%u60A0和\u60a0类似unicode解码】
# coding:utf-8
# a是str类型
a = r"case/test_houtai.py::TestHouTai::()::test_aboutzenta[\u6350\u52a9\u6211\u4eec]"
print(type(a))
# 转码
print(a.encode("utf-8").decode("unicode_escape"))运行结果
<class 'str'>
case/test_houtai.py::TestHouTai::()::test_aboutzenta[捐助我们]
pytest-html报告优化
源码地址【https://github.com/pytest-dev/pytest-html/blob/master/pytest_html/plugin.py】
Test这一列显示的内容是用例的nodeid,nodeid获取方法从源码可以看出是通过report.nodeid获取到的

于是我们可以在conftest.py里面新增一列,重新命名Test_nodeid,然后删除原有的Test列,具体参考前面一篇内容【pytest文档20-pytest-html报告优化(添加Description)】
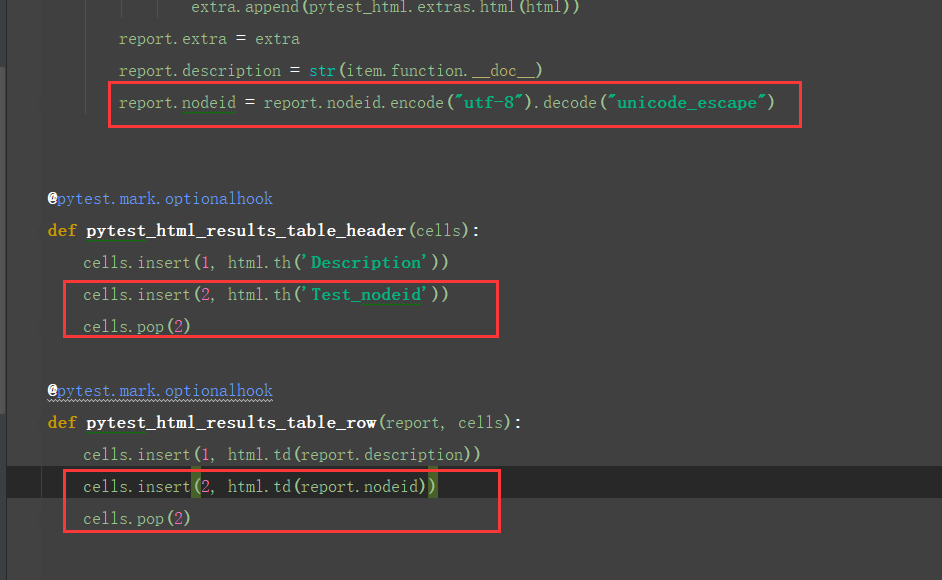
from datetime import datetime
from py.xml import html
import pytest @pytest.mark.hookwrapper def pytest_runtest_makereport(item): """ 当测试失败的时候,自动截图,展示到html报告中 :param item: """ pytest_html = item.config.pluginmanager.getplugin('html') outcome = yield report = outcome.get_result() extra = getattr(report, 'extra', []) if report.when == 'call' or report.when == "setup": xfail = hasattr(report, 'wasxfail') if (report.skipped and xfail) or (report.failed and not xfail): file_name = report.nodeid.replace("::", "_")+".png" screen_img = _capture_screenshot() if file_name: html = '<div><img src="data:image/png;base64,%s" alt="screenshot" style="width:600px;height:300px;" ' \ 'onclick="window.open(this.src)" align="right"/></div>' % screen_img extra.append(pytest_html.extras.html(html)) report.extra = extra report.description = str(item.function.__doc__) report.nodeid = report.nodeid.encode("utf-8").decode("unicode_escape") @pytest.mark.optionalhook def pytest_html_results_table_header(cells): cells.insert(1, html.th('Description')) cells.insert(2, html.th('Test_nodeid')) # cells.insert(1, html.th('Time', class_='sortable time', col='time')) cells.pop(2) @pytest.mark.optionalhook def pytest_html_results_table_row(report, cells): cells.insert(1, html.td(report.description)) cells.insert(2, html.td(report.nodeid)) # cells.insert(1, html.td(datetime.utcnow(), class_='col-time')) cells.pop(2)结果展示
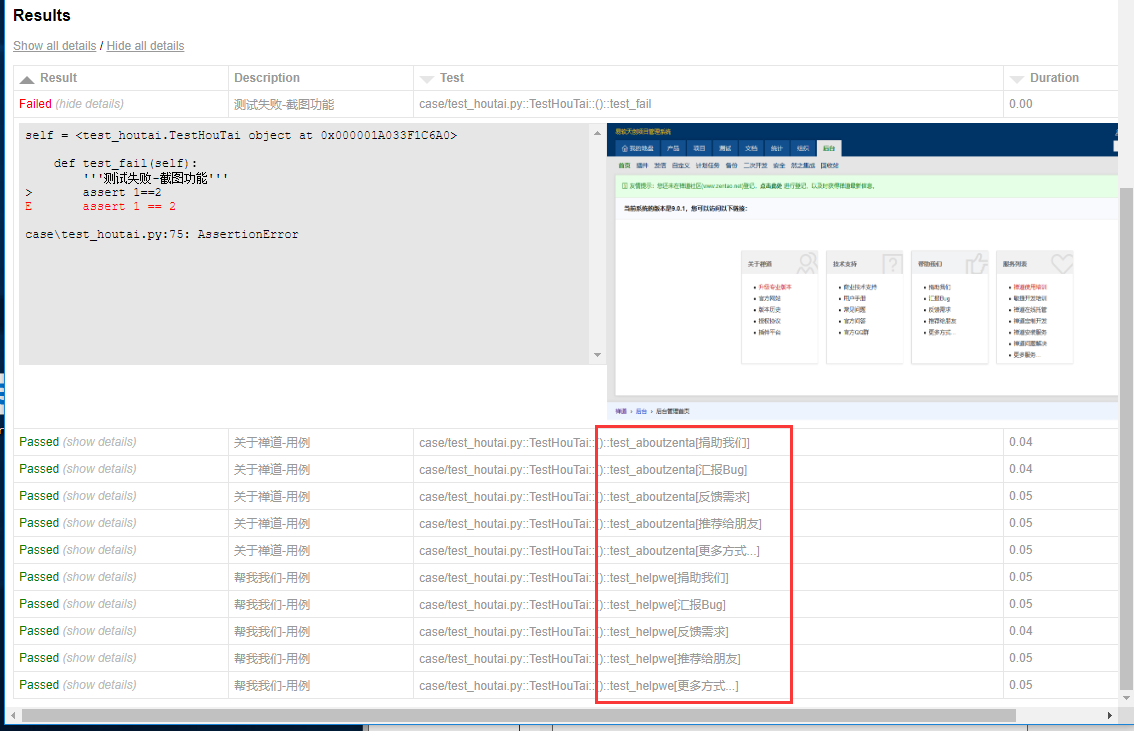
修改之后结果展示如下
pytest-html报告中当用到参数化时候,获取用例的nodeid里面有中文时候,会显示[\u6350\u52a9\u6211\u4eec]这种编码(再次声明,这个不叫乱码,这是unicode编码)
关于python2和python3里面Unicode编码转化可以参考之前写的一篇【python笔记6-%u60A0和\u60a0类似unicode解码】
本篇以python3.6版本为例
遇到问题
官网文档https://github.com/pytest-dev/pytest-html上说明如下:
注意ANSI代码支持取决于ansi2html包,此包不作为依赖项包含在内。如果你安装了这个软件包,那么ANSI代码会在你的报告中被转换成HTML。
试过了,安装ansi2html包也无法解决问题,于是只有自己解码,重新优化报告内容了
编码转化
相关转化参考这篇【python笔记6-%u60A0和\u60a0类似unicode解码】
# coding:utf-8
# a是str类型
a = r"case/test_houtai.py::TestHouTai::()::test_aboutzenta[\u6350\u52a9\u6211\u4eec]"
print(type(a))
# 转码
print(a.encode("utf-8").decode("unicode_escape"))运行结果
<class 'str'>
case/test_houtai.py::TestHouTai::()::test_aboutzenta[捐助我们]
pytest-html报告优化
源码地址【https://github.com/pytest-dev/pytest-html/blob/master/pytest_html/plugin.py】
Test这一列显示的内容是用例的nodeid,nodeid获取方法从源码可以看出是通过report.nodeid获取到的
于是我们可以在conftest.py里面新增一列,重新命名Test_nodeid,然后删除原有的Test列,具体参考前面一篇内容【pytest文档20-pytest-html报告优化(添加Description)】
from datetime import datetime
from py.xml import html
import pytest @pytest.mark.hookwrapper def pytest_runtest_makereport(item): """ 当测试失败的时候,自动截图,展示到html报告中 :param item: """ pytest_html = item.config.pluginmanager.getplugin('html') outcome = yield report = outcome.get_result() extra = getattr(report, 'extra', []) if report.when == 'call' or report.when == "setup": xfail = hasattr(report, 'wasxfail') if (report.skipped and xfail) or (report.failed and not xfail): file_name = report.nodeid.replace("::", "_")+".png" screen_img = _capture_screenshot() if file_name: html = '<div><img src="data:image/png;base64,%s" alt="screenshot" style="width:600px;height:300px;" ' \ 'onclick="window.open(this.src)" align="right"/></div>' % screen_img extra.append(pytest_html.extras.html(html)) report.extra = extra report.description = str(item.function.__doc__) report.nodeid = report.nodeid.encode("utf-8").decode("unicode_escape") @pytest.mark.optionalhook def pytest_html_results_table_header(cells): cells.insert(1, html.th('Description')) cells.insert(2, html.th('Test_nodeid')) # cells.insert(1, html.th('Time', class_='sortable time', col='time')) cells.pop(2) @pytest.mark.optionalhook def pytest_html_results_table_row(report, cells): cells.insert(1, html.td(report.description)) cells.insert(2, html.td(report.nodeid)) # cells.insert(1, html.td(datetime.utcnow(), class_='col-time')) cells.pop(2)结果展示
修改之后结果展示如下