版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/u013421629/article/details/86525298
pyocr 官方网站:
https://gitlab.gnome.org/World/OpenPaperwork/pyocr
安装:
pip install pyocr
上一篇文章也写了:
https://blog.csdn.net/u013421629/article/details/84393691
搞了一张截图命名为1.png,下面来图片文字识别下,借助pyocr

识别情况:
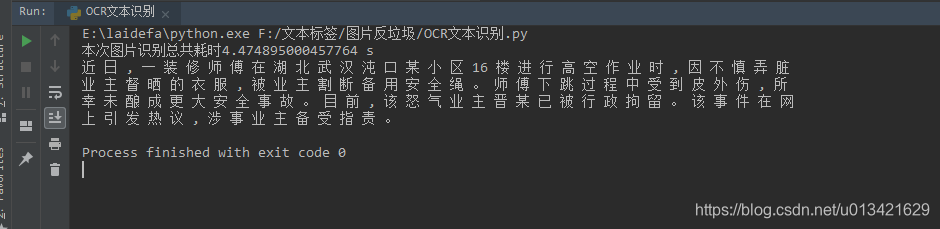
本次图片识别总共耗时4.474895000457764 s
近 日 , 一 装 修 师 傅 在 湖 北 武 汉 沌 口 某 小 区 16 楼 进 行 高 空 作 业 时 , 因 不 慎 弄 脏
业 主 督 晒 的 衣 服 , 被 业 主 割 断 备 用 安 全 绳 。 师 傅 下 跳 过 程 中 受 到 皮 外 伤 , 所
幸 未 酿 成 更 大 安 全 事 故 。 目 前 , 该 怒 气 业 主 晋 某 已 被 行 政 拘 留 。 该 事 件 在 网
上 引 发 热 议 , 涉 事 业 主 备 受 指 责 。
Process finished with exit code 0
# -*- encoding=utf-8 -*-
import pyocr.builders
import time
from PIL import Image,ImageEnhance
import pyocr.builders
# 初始化配置文件
tool = pyocr.get_available_tools()[0]
builder = pyocr.builders.TextBuilder()
langs = tool.get_available_languages()
lang = langs[0]
# 定义OCR图片文字识别函数
def pic_orc(filepath,filename,resize_num,b):
"""
:param filepath: 文件路径
:param filename:文件名称
:return:文字识别
"""
time1 = time.time()
im = Image.open(str(filepath) + str(filename))
# 图像放大
im = im.resize((im.width * int(resize_num), im.height * int(resize_num)))
# 图像二值化
imgry = im.convert('L')
# 对比度增强
sharpness = ImageEnhance.Contrast(imgry)
sharp_img = sharpness.enhance(b)
txt =tool.image_to_string(sharp_img, lang=lang,builder=builder)
time2 = time.time()
print('本次图片识别总共耗时%s s' % (time2 - time1))
return txt
if __name__ == '__main__':
filepath='F:/img_spam/test/'
filename='1.png'
resize_num = 2
b = 2.0
txt=pic_orc(filepath,filename,resize_num,b)
print(txt)