版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/qq_39622065/article/details/86658838
本套代码实现了对流量的统计
源数据:第2列为手机号,倒数2、3列为上行流量和下行流量,则我们要按照手机号为主键,统计出这个手机号一共的上行和下行流量。(数据是自己造的)
1363154400022 13926251106 5C-0E-8B-B1-50:CMCC 120.17.81.234 twat.com 4 0 240 10 200
1363154400023 13856251106 5C-0E-8B-B1-50:CMCC 120.17.81.234 twat.com 4 0 240 44 200
1363154400024 17856251106 5C-0E-8B-B1-50:CMCC 120.17.81.234 twat.com 4 0 274401 1034 200
1363154400025 13156251106 5C-0E-8B-B1-50:CMCC 120.17.81.234 twat.com 4 0 2404 450 200
1363154400026 13426251106 5C-0E-8B-B1-50:CMCC 120.17.81.234 twat.com 4 0 2406 460 200
1363154400027 13726251106 5C-0E-8B-B1-50:CMCC 120.17.81.234 twat.com 4 0 24046 6450 200
1363154400028 13926251106 5C-0E-8B-B1-50:CMCC 120.17.81.234 twat.com 4 0 24064 6450 200
1363154400029 13926251106 5C-0E-8B-B1-50:CMCC 120.17.81.234 twat.com 4 0 240 0 200
1363154400030 13926251106 5C-0E-8B-B1-50:CMCC 120.17.81.234 twat.com 4 0 240 0 200
1363154400031 13926251106 5C-0E-8B-B1-50:CMCC 120.17.81.234 twat.com 4 0 240 0 200代码的主要问题是Map和Reduce的键值传递问题,需要同时传递上行和下行的数值。
解决思路是:以手机号为K,V传递一个自定义的类通过这个类的属性来同时传递上行和下行数据,键值对为:<手机号,类>
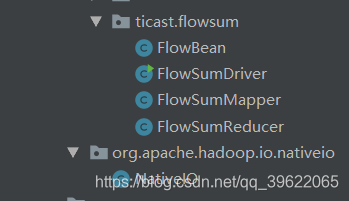
代码结构树:
1、自定义一个Bean类,需要实现序列化和反序列化,本代码继承的是Writable
package cn.ticast.flowsum;
import org.apache.hadoop.io.Writable;
import org.apache.hadoop.io.WritableComparable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
public class FlowBean implements Writable {
private long upFlow;
private long downFlow;
private long sumFlow;
public FlowBean() {
}
public FlowBean(long upFlow, long downFlow, long sumFlow) {
this.upFlow = upFlow;
this.downFlow = downFlow;
this.sumFlow = sumFlow;
}
public FlowBean(long upFlow, long downFlow) {
this.upFlow = upFlow;
this.downFlow = downFlow;
this.sumFlow = upFlow+downFlow;
}
public void set(long upFlow, long downFlow) {
this.upFlow = upFlow;
this.downFlow = downFlow;
this.sumFlow = upFlow+downFlow;
}
//这就序列化方法
@Override
public void write(DataOutput out) throws IOException {
out.writeLong(upFlow);
out.writeLong(downFlow);
out.writeLong(sumFlow);
}
@Override
public String toString() {
return upFlow+"\t"+downFlow+"\t"+sumFlow;
}
//这是反序列化方法
//反序列时候 注意序列化的顺序
//先序列化的先出来
@Override
public void readFields(DataInput in) throws IOException {
this.upFlow = in.readLong();
this.downFlow=in.readLong();
this.sumFlow=in.readLong();
}
public long getUpFlow() {
return upFlow;
}
public void setUpFlow(long upFlow) {
this.upFlow = upFlow;
}
public long getDownFlow() {
return downFlow;
}
public void setDownFlow(long downFlow) {
this.downFlow = downFlow;
}
public long getSumFlow() {
return sumFlow;
}
public void setSumFlow(long sumFlow) {
this.sumFlow = sumFlow;
}
//这里就是Bean比较大小的方法
// @Override
// public int compareTo(FlowBean o) {
// //实现按照总流量的倒序排序
// return this.sumFlow >o.getSumFlow()?-1:1;
// //正常逻辑 this.sumFlow >o.getSumFlow()?1:-1
// }
}
2、编写Map阶段
package cn.ticast.flowsum;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
/**
* 在mr程序中,也可以使用我们自定义的类型作为mr的数据类型,前提是需要实现hadoop的序列化机制 writeable
*/
public class FlowSumMapper extends Mapper<LongWritable, Text, Text, FlowBean> {
Text k = new Text();
FlowBean v = new FlowBean();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
String[] fields = line.split("\t");
String phoneNum = fields[1];
long upFlow =Long.parseLong(fields[fields.length-3]);
long downFlow =Long.parseLong(fields[fields.length-2]);
k.set(phoneNum);
v.set(upFlow,downFlow);
context.write(k,v);
}
}
3、编写Reduce阶段
package cn.ticast.flowsum;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
/**
* <手机号1,bean><手机号2,bean><手机号1,bean><手机号2,bean><手机号,bean>
*
* <手机号1,bean><手机号1,bean>
* <手机号2,bean><手机号2,bean>
*/
public class FlowSumReducer extends Reducer<Text,FlowBean,Text,FlowBean>{
FlowBean v = new FlowBean();
@Override
protected void reduce(Text key, Iterable<FlowBean> values, Context context) throws IOException, InterruptedException {
long upFlowCount = 0 ;
long downFlowCount =0;
for(FlowBean bean :values){
upFlowCount += bean.getUpFlow();
downFlowCount += bean.getDownFlow();
}
v.set(upFlowCount,downFlowCount);
context.write(key,v);
}
}
4、指定Job
package cn.ticast.flowsum;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class FlowSumDriver {
public static void main(String[] args) throws Exception{
//通过Job来封装本次mr的相关信息
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
//指定本次mr job jar包运行主类
job.setJarByClass(FlowSumDriver.class);
//指定本次mr 所用的mapper reducer类分别是什么
job.setMapperClass(FlowSumMapper.class);
job.setReducerClass(FlowSumReducer.class);
//指定本次mr mapper阶段的输出 k v类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(FlowBean.class);
//指定本次mr 最终输出的 k v类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(FlowBean.class);
// job.setNumReduceTasks(3);
//指定本次mr 输入的数据路径 和最终输出结果存放在什么位置
FileInputFormat.setInputPaths(job,"D:\\Download\\input");
FileOutputFormat.setOutputPath(job,new Path("D:\\Download\\outputsum"));
// job.submit();
//提交程序 并且监控打印程序执行情况
boolean b = job.waitForCompletion(true);
System.exit(b?0:1);
}
}
使用本地模式运行,将数据放在了D:\\Download\\input下
扫描二维码关注公众号,回复:
5089826 查看本文章

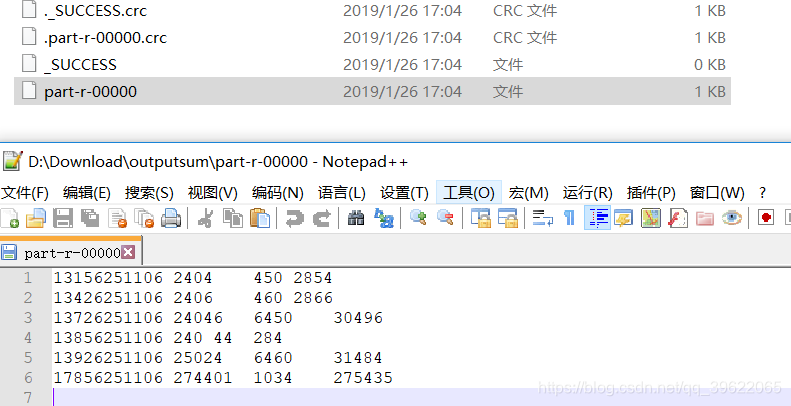
运行结果: