一、概述
在MyBatis中允许使用缓存,缓存一般都放置在可高速读/写的存储器上,比如服务器的内存,它能够有效提高系统的性能。因为数据库大部分场景下是把存储在磁盘上的数据索引出来。从硬件的角度分析,索引磁盘是一个较为缓慢的过程,读取内存或者高速缓存在处理器上得速度要比读取磁盘快得多。缓存就是将那些常用的数据放在内存中,以便将来使用,以此提高系统性能。
MyBatis系统中默认定义了一级缓存和二级缓存两级缓存。
- 默认情况下,只有一级缓存(SqlSession级别的缓存,也称为本地缓存)开启。
- 二级缓存需要手动开启和配置,他是基于namespace级别的缓存。
- 为了提高扩展性。 MyBatis定义了缓存接口Cache。我们可以通过实现Cache接口来自定义二级缓存
二、一级缓存
一级缓存(local cache), 即本地缓存, 本地缓存不能被关闭,作用域默认为sqlSession。
验证一级缓存的存在
测试代码:
SqlSessionFactory sessionFactory = getSqlSessionFactory();
SqlSession session = sessionFactory.openSession();
try {
EmployeeMapper mapper = session.getMapper(EmployeeMapper.class);
//通过id为1去查询获取员工对象
Employee emp01 = mapper.getEmpById(1);
System.out.println(emp01);
//再次通过id为1去查询获取员工对象
Employee emp02 = mapper.getEmpById(1);
System.out.println(emp02);
System.out.println(emp01 == emp02);
} finally {
session.close();
}
运行结果:

从运行结果可以知道,虽然调用了两次查询,但是只发送了一条SQL语句,且两次获取的员工对象是同一个。显示,MyBatis没有再次查询数据库,而是从一级缓存中获取已有的员工对象。
失效情况
所谓失效情况就是没有使用到当前一级缓存的情况,效果就是还需要再向数据库发出SQL。
1. sqlSession不同
假设我分别用两个不同的sqlSession进行员工的查询,这时会发送两条相同的查询SQL,也就是没有使用到一级缓存的情形。
测试代码:
SqlSessionFactory sessionFactory = getSqlSessionFactory();
//创建两个不同的session
SqlSession session1 = sessionFactory.openSession();
SqlSession session2 = sessionFactory.openSession();
try {
//使用session1去查询id为1的员工对象
EmployeeMapper mapper1 = session1.getMapper(EmployeeMapper.class);
Employee emp01 = mapper1.getEmpById(1);
System.out.println(emp01);
//使用session2去查询id为1的员工对象
EmployeeMapper mapper2 = session2.getMapper(EmployeeMapper.class);
Employee emp02 = mapper2.getEmpById(1);
System.out.println(emp02);
System.out.println(emp01 == emp02);
} finally {
session1.close();
session2.close();
}
运行结果:
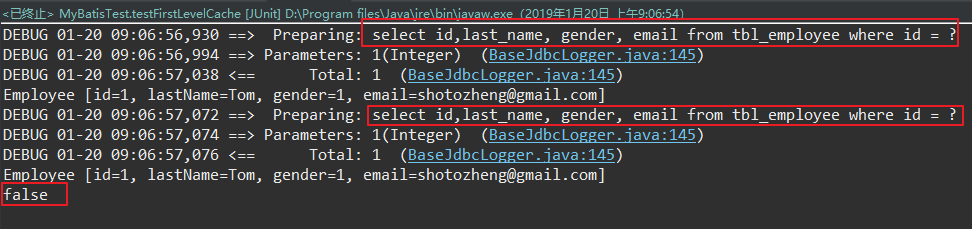
这是很好理解的,因为一级缓存的默认作用域是sqlSession,所以不同的sqlSession有不同的一级缓存。
2. sqlSession相同,查询条件不同
这个也很好理解,既然两次数据库操作是不一样的,显然当前一级缓存是没有保存相同的数据,还是会访问数据库。
3. sqlSession相同,两次查询之间存在增删改操作
在进行了增删改操作之后,数据库中的数据可能会发生改变。为了保持数据的一致性,在第二次查询的时候,必须在此访问数据库获取最新的数据。
测试代码:
SqlSessionFactory sessionFactory = getSqlSessionFactory();
SqlSession session = sessionFactory.openSession();
try {
//去查询id为1的员工对象
EmployeeMapper mapper = session.getMapper(EmployeeMapper.class);
Employee emp01 = mapper.getEmpById(1);
System.out.println(emp01);
//两次查询之间存在增删改操作
Employee emp = new Employee(1,"郑楚","1","[email protected]");
mapper.addEmp(emp);
//查询id为1的员工对象
Employee emp02 = mapper.getEmpById(1);
System.out.println(emp02);
System.out.println(emp01 == emp02);
} finally {
session.close();
}
运行结果:
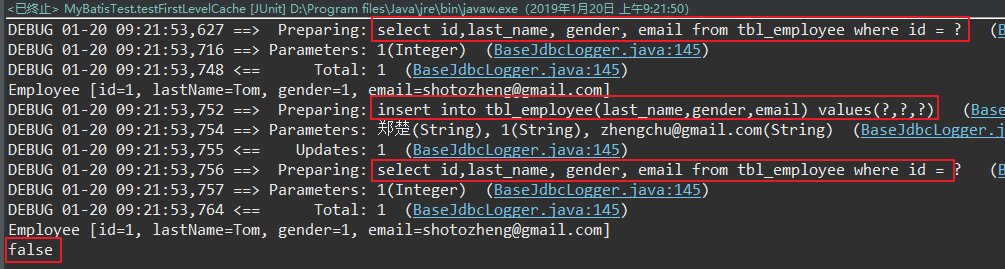
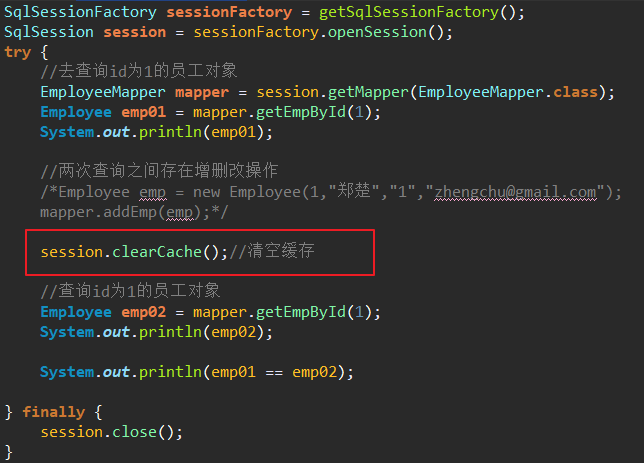
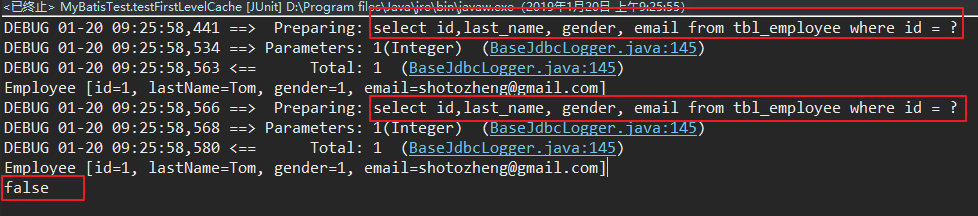
4. sqlSession相同,手动清空一级缓存
测试代码:
运行结果:
三、二级缓存
二级缓存需要手动开启和配置,它是基于namespace级别的缓存,在 SqlSession 关闭或提交之后才会生效
我们知道一级缓存的作用为sqlSession,但是当这个会话关闭的时候,我们又不得不重新访问数据库进行一些查询等操作。但是使用二级缓存,如果当前namespace下的会话关闭,一级缓存中的数据就会被保存到二级缓存中,因此新的会话查询信息,就可以参照二级缓存中的内容。不同的namesapce查出的数据会放在自己对应的缓存中。另外,底层中缓存数据是用Map集合封装的。
二级缓存的使用
- 开启全局二级缓存配置。
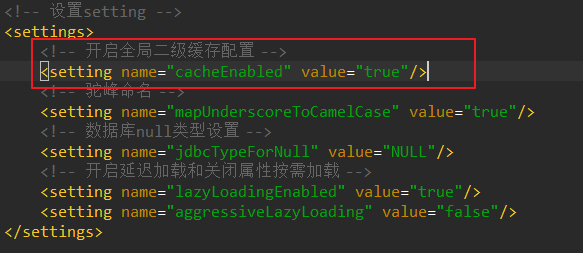
- 在映射器文件EmployeeMapper.xml中配置使用二级缓存。提醒一下:不同的映射器有着不一样的namespace。

cache标签里的属性不进行配置,也就是采用默认也是可以的。
cache标签有许多属性,下面讲一下这些属性的作用:
| 属性 | 说明 | 取值 | 备注 |
|---|---|---|---|
| eviction | 缓存回收策略 1. LRU – 最近最少使用的:移除最长时间不被使用的对象。 2. FIFO – 先进先出:按对象进入缓存的顺序来移除它们 3. SOFT – 软引用:移除基于垃圾回收器状态和软引用规则的对象。 4. WEAK – 弱引用:更积极地移除基于垃圾收集器状态和弱引用规则的对象。 |
默认的是 LRU。 | - |
| flushInterval | 刷新间隔,单位毫秒,默认情况是不设置,也就是没有刷新间隔,缓存仅仅调用语句时刷新 | 正整数 | 超过中整数后缓存失效,不再读取缓存,而是执行SQL取回数据 |
| size | 引用数目,代表缓存最多可以存储多少个对象,太大容易导致内存溢出 | 正整数,默认取值1024 | - |
| readOnly | 缓存内容是否只读 true:只读缓存;会给所有调用者返回缓存对不能被修改。这提供了很重要的性能优势 false:读写缓存;会返回缓存对象的拷贝(通过序列化)。这会慢一些,但是安全,因此默认是 false。 |
true/false,默认为false | - |
| type | 自定义缓存类,要求实现接口org.apache.ibatis.cache.Cache | 用于自定义的缓存类 | - |
| blocking | 是否使用阻塞性缓存,在读/写时它会加入JNI的锁进行操作 | true/false,默认为false | 可保证读/写安全性,但加锁后性能不佳。 |
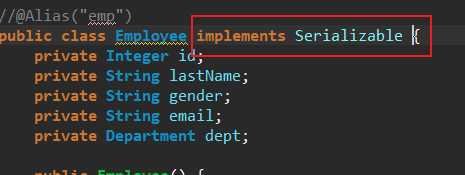
- readOnly默认是false的,因此需要给涉及到的POJO类实现序列化接口。
- 测试代码
SqlSessionFactory sessionFactory = getSqlSessionFactory(); //创建两个不同的session SqlSession session1 = sessionFactory.openSession(); SqlSession session2 = sessionFactory.openSession(); try { //使用session1去查询id为1的员工对象 EmployeeMapper mapper1 = session1.getMapper(EmployeeMapper.class); Employee emp01 = mapper1.getEmpById(1); System.out.println(emp01); //关闭session1 session1.close(); //使用session2去查询id为1的员工对象 //第二次查询是从二级缓存中查询的数据,并没有发送SQL EmployeeMapper mapper2 = session2.getMapper(EmployeeMapper.class); Employee emp02 = mapper2.getEmpById(1); System.out.println(emp02); System.out.println(emp01 == emp02); } finally { //关闭session2 session2.close(); }
运行结果:

从运行结果可以知道,第一次查询时会先查询二级缓存,查询不到数据所以发送SQL语句进行数据库访问。第二次查询还是先查询二级缓存,这次查询到了数据便直接返回输出数据。因为二级缓存会进行对象的克隆(序列化与反序列化),所以两次查询的员工对象是不相等的。
注意:我们上面在进行代码测试测试时,在进行第二次查询之前是先关闭session1会话的,因为二级缓存是在SqlSession 关闭或提交之后才会生效。
缓存有关设置和属性
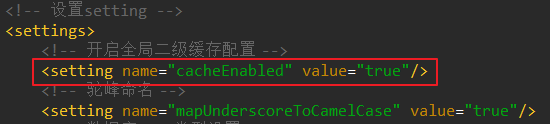
- 全局二级缓存开启和关闭。true为开启,false则为关闭。
- select标签中的useCache属性,默认为true。true则使用二级缓存(全局二级缓存得开),false则不使用二级缓存。

- 增删改标签中的flushCache属性,默认为true。true则每次增删改会清空一级缓存和二级缓存,false则不会清空二级缓存,但是会清空一级缓存。

- select标签中的flushCache标签,默认值为false。true则每次查询都清空一级缓存和二级缓存,false则不会清空一级缓存和二级缓存。

四、EhCache整合
EhCache 第三方缓存框架是一个纯Java的进程内缓存框架,具有快速、精干等特点,是Hibernate中默认的CacheProvider。我们可以使用MyBatis定义得Cache接口来进行自定义扩展。
整合步骤
- 导入ehcache包,以及整合包,日志包
官方文档即相关包下载 - 编写ehcache.xml配置文件,一般情况下直接拿来用即可。
<?xml version="1.0" encoding="UTF-8"?> <ehcache xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:noNamespaceSchemaLocation="../config/ehcache.xsd"> <!-- 磁盘保存路径 --> <diskStore path="D:\44\ehcache" /> <defaultCache maxElementsInMemory="1" maxElementsOnDisk="10000000" eternal="false" overflowToDisk="true" timeToIdleSeconds="120" timeToLiveSeconds="120" diskExpiryThreadIntervalSeconds="120" memoryStoreEvictionPolicy="LRU"> </defaultCache> </ehcache> <!-- 属性说明: l diskStore:指定数据在磁盘中的存储位置。 l defaultCache:当借助CacheManager.add("demoCache")创建Cache时,EhCache便会采用<defalutCache/>指定的的管理策略 以下属性是必须的: l maxElementsInMemory - 在内存中缓存的element的最大数目 l maxElementsOnDisk - 在磁盘上缓存的element的最大数目,若是0表示无穷大 l eternal - 设定缓存的elements是否永远不过期。如果为true,则缓存的数据始终有效,如果为false那么还要根据timeToIdleSeconds,timeToLiveSeconds判断 l overflowToDisk - 设定当内存缓存溢出的时候是否将过期的element缓存到磁盘上 以下属性是可选的: l timeToIdleSeconds - 当缓存在EhCache中的数据前后两次访问的时间超过timeToIdleSeconds的属性取值时,这些数据便会删除,默认值是0,也就是可闲置时间无穷大 l timeToLiveSeconds - 缓存element的有效生命期,默认是0.,也就是element存活时间无穷大 diskSpoolBufferSizeMB 这个参数设置DiskStore(磁盘缓存)的缓存区大小.默认是30MB.每个Cache都应该有自己的一个缓冲区. l diskPersistent - 在VM重启的时候是否启用磁盘保存EhCache中的数据,默认是false。 l diskExpiryThreadIntervalSeconds - 磁盘缓存的清理线程运行间隔,默认是120秒。每个120s,相应的线程会进行一次EhCache中数据的清理工作 l memoryStoreEvictionPolicy - 当内存缓存达到最大,有新的element加入的时候, 移除缓存中element的策略。默认是LRU(最近最少使用),可选的有LFU(最不常使用)和FIFO(先进先出) --> - 配置cache标签,type中的值为类路径。

若想在命名空间中共享相同的缓存配置和实例。可以使用 cache-ref 元素来引用另外一个缓存。
比如我在DepartmentMapper.xml中引用EmployeeMapper.xml相同的第三方缓存,可以进行如下配置。

五、缓存原理
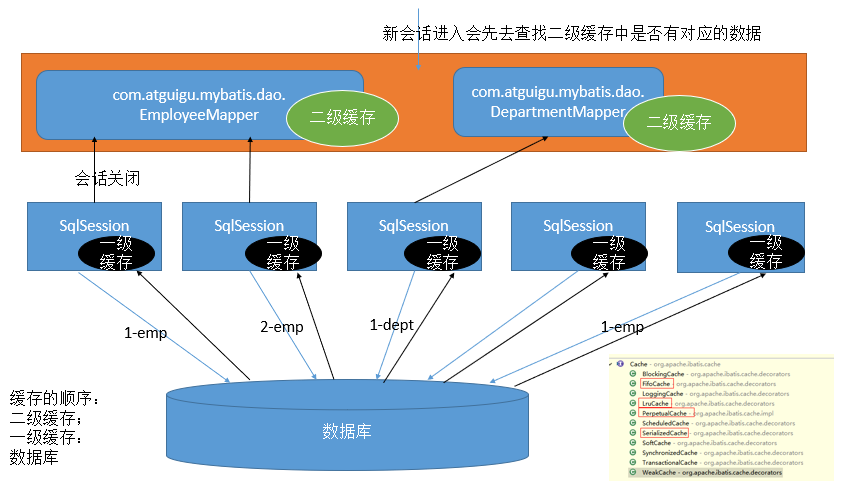
- 在二级缓存关闭的状态下,第一次查询id为1的员工数据时,会先访问数据库,然后将查询到的数据放在一级缓存中。当该会话关闭,那么下次查询又会重新访问数据库。
- 若二级缓存处于开启状态,新会话会先查询对应表空间的二级缓存是否有要查询的数据,否则访问数据库并将查询到的数据放在一级缓存中,当该会话关闭时则再将该数据拷贝到二级缓存中。该表空间的新会话要查询同样的数据时,将会查询二级缓存并获取数据。