一,创建series
import pandas as pd
countries = ['中国', '美国', '澳大利亚']
countries_s = pd.Series(countries)
print(type(countries_s))
print(countries_s)
print(countries_s.values)
二,添加索引名
import pandas as pd
country_dicts = {'CH': '中国',
'US': '美国',
'AU': '澳大利亚'}
country_dict_s = pd.Series(country_dicts)
# 给索引命名
country_dict_s.index.name = 'index'
# 给数据命名
country_dict_s.name = 'Country'
print(country_dict_s)
print(country_dict_s.values)
print(country_dict_s.index)
三,pd.DataFrame
import pandas as pd
country1 = pd.Series({'Name': '中国',
'Language': 'Chinese',
'Area': '9.597M km2',
'Happiness Rank': 79})
country2 = pd.Series({'Name': '美国',
'Language': 'English (US)',
'Area': '9.834M km2',
'Happiness Rank': 14})
country3 = pd.Series({'Name': '澳大利亚',
'Language': 'English (AU)',
'Area': '7.692M km2',
'Happiness Rank': 9})
df = pd.DataFrame([country1, country2, country3])
print(df)
print('df.values=',df.values)
print(type(df['Area']))
print('area values=',df['Area'].values)
print(df[['Name','Area']])
print(df[['Name','Area']].values)
#操作原数据,要用copy,否则会改变原数据
rank=df['Happiness Rank'].values.copy()
rank+=2
print(df['Happiness Rank'].values)

四,增加一列:
country_1 = pd.Series({'Name': '中国',
'Language': '汉语',
'Area': '11111'})
country_2 = pd.Series({'Name': '美国',
'Language': '英语',
'Area': '222'})
country_3 = pd.Series({'Name': '澳大利亚',
'Language': '英语',
'Area': '333'})
# print(country_1)
df=pd.DataFrame([country_1,country_2,country_3],index=['CH','US','AU'])
print(df)
#
#增加一列 按列索引
df['location']='地球'
print(df)
df['region']=['亚洲','北美洲','大洋洲']
print(df)
五,转置,删除
country_1 = pd.Series({'Name': '中国',
'Language': '汉语',
'Area': '11111'})
country_2 = pd.Series({'Name': '美国',
'Language': '英语',
'Area': '222'})
country_3 = pd.Series({'Name': '澳大利亚',
'Language': '英语',
'Area': '333'})
# print(country_1)
df=pd.DataFrame([country_1,country_2,country_3],index=['CH','US','AU'])
print(df)
#转换行和列
print('====================================')
print(df.T)
#删除数据
print('====================================')
print(df.drop(['CH']))
print('====================================')
print(df)
#注意 drop操作不会改变原有数据的
六,读csv,index_col
import pandas as pd
# 使用index_col指定索引列
# 使用usecols指定需要读取的列
reprot_2016_df = pd.read_csv('./2016.csv',
index_col='Country',
usecols=['Country', 'Happiness Rank', 'Happiness Score', 'Region'])
# 数据预览
print(reprot_2016_df.head())
print(reprot_2016_df.values[:2,:])
reprot_2016_df = pd.read_csv('./2016.csv',
usecols=['Country', 'Happiness Rank', 'Happiness Score', 'Region'])
# 数据预览
print('==============================================')
print(reprot_2016_df.head())
print(reprot_2016_df.values[:2,:])
print('==============================================')
print(reprot_2016_df[['Region','Happiness Rank']].values[:2,:])

七,pd.query
from numpy.random import randn
from pandas import DataFrame
df = pd.DataFrame(randn(5, 2), columns=list('ab'))
print(df)
print(df.query('a > b'))
print(df.query('a > 0.2'))
八,列名重命名
import pandas as pd
reprot_2016_df = pd.read_csv('./2016.csv',
usecols=['Country', 'Happiness Rank', 'Happiness Score', 'Region'])
# 数据预览
print('==============================================')
print(reprot_2016_df.head())
reprot_2016_df.rename(columns={'Country': '国家','Region': '地区', 'Happiness Rank': '排名', 'Happiness Score': '幸福指数'},
inplace=True)
print('==============================================')
print(reprot_2016_df.head())

九,过滤
import pandas as pd
reprot_2016_df = pd.read_csv('./2016.csv',
usecols=['Country', 'Happiness Rank', 'Happiness Score', 'Region'])
# 数据预览
print('==============================================')
print(reprot_2016_df.head())
print('==============================================')
df=reprot_2016_df[reprot_2016_df['Country'] == 'Denmark']
print(df.head())
print('==============================================')
only_western_europe_10 = reprot_2016_df[(reprot_2016_df['Region'] == 'Western Europe') & (reprot_2016_df['Happiness Rank'] > 10)]
print(only_western_europe_10.head())

十,处理Nan值
import pandas as pd
log_df = pd.read_csv('./data/log.csv')
print(log_df.head())
print('===============查看head是否有空值=========================')
#查看head是否有空值
print(log_df.head().isnull())
print('===============取出volume不为空的数据=========================')
# 取出volume不为空的数据
print(log_df[log_df['volume'].notnull()])
#将index改为time和user
log_df.set_index(['time', 'user'], inplace=True)
print(log_df)
#按照index排序
print('===============按照index排序=========================')
log_df.sort_index(inplace=True)
print(log_df)
print('================将nan替换为0========================')
#将nan替换为0
print(log_df.fillna(0))
print('================丢掉nan值========================')
#丢掉nan值
print(log_df.dropna())






十一,处理重复值
import pandas as pd
data = pd.DataFrame({'k1': ['one', 'two'] * 2+ ['two'],
'k2': [1, 3, 3, 4, 4]})
print(data)
print('===============判断是否重复=========================')
print(data.duplicated())
print('===============去除重复数据=========================')
print(data.drop_duplicates())
print('===============去除指定列的重复数据=========================')
print(data.drop_duplicates(['k2']))

十二,数据合并
import pandas as pd
staff_df = pd.DataFrame([{'姓名': '张三', '部门': '研发部'},
{'姓名': '李四', '部门': '财务部'},
{'姓名': '赵六', '部门': '市场部'}])
student_df = pd.DataFrame([{'姓名': '张三', '专业': '计算机'},
{'姓名': '李四', '专业': '会计'},
{'姓名': '王五', '专业': '市场营销'}])
print(staff_df)
print()
print(student_df)
print('===============数据合并有NAN==================')
print(pd.merge(staff_df, student_df, how='outer', on='姓名'))
print('===============数据合并无NAN==================')
print(pd.merge(staff_df, student_df, how='inner', on='姓名'))
十三,分箱操作
import pandas as pd
# 年龄数据
ages = [20, 22, 25, 27, 21, 23, 37, 31, 61, 45, 41, 32]
# 分箱的边界
bins = [18, 25, 35, 60, 100]
cats = pd.cut(ages, bins)
print(cats)
print('================获取分箱编码================')
print(cats.codes)
print('===========统计箱中元素的个数=============')
print(pd.value_counts(cats))
print('===========带标签的分箱=============')
group_names = ['Youth', 'YoungAdult', 'MiddleAged', 'Senior']
cats = pd.cut(ages, bins, labels=group_names)
print(cats)
十四,画图
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
np.random.seed(100)
df = pd.DataFrame({'A': np.random.randn(365).cumsum(0),
'B': np.random.randn(365).cumsum(0) + 20,
'C': np.random.randn(365).cumsum(0) - 20},
index=pd.date_range('2017/1/1', periods=365))
print(df.head())
df.plot()
plt.show()
df.plot('A', 'B', kind='scatter')
plt.show()
# 颜色(c)和大小(s)由'B'列的数据决定
ax = df.plot('A', 'B', kind='scatter',
c='B', s=df['B'], colormap='viridis')
# 设置坐标为相同比例
ax.set_aspect('equal')
plt.show()
df.plot(kind='box')
plt.show()
df.plot(kind='hist', alpha=0.7)
df.plot(kind='kde')
plt.show()






十五,groupby

import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
countries = ['Germany', 'UK', 'CH', 'JP', 'Switzerland']
data = pd.DataFrame({'InvoiceNo':['c12','24','34','3','4','5','6'],
'price': [2,1,1,2,3,4,3],'quantity':[3,2,2,1,4,5,4],
'country': ['UK','UK','UK', 'UK', 'CH', 'JP', 'CH']})
print(data)
#只要我关心的国家
data=data[data['country'].isin(countries)].copy()
#c开头意味取消交易
cond1 = ~data['InvoiceNo'].str.startswith('c')
cond2=data['country']!='UK'
data2=data[cond1&cond2].copy()
print('===============================================')
print(data2)
data2['total_cost']=data2['price']*data2['quantity']
print(data2)
print('===============================================')
cost_per_country=data2.groupby('country')['total_cost'].sum()
print(cost_per_country)
print('===============================================')
print(cost_per_country.to_frame())
# 可视化结果
sns.barplot(data=cost_per_country.to_frame().T)
# cost_per_country.sort_values(ascending=False).plot(kind='bar')
plt.xticks(rotation=90)
plt.xlabel('Country')
plt.ylabel('costs')
plt.tight_layout()
plt.show()


十六,apply用于每一列最小最大归一化
import pandas as pd
a=pd.Series({'v1':2,
'v2':3})
b=pd.Series({'v1':5,
'v2':10})
c=pd.Series({'v1':4,
'v2':6})
all=pd.DataFrame([a,b,c])
def scale_minmax(col):
return (col-col.min())/(col.max()-col.min())
print('================')
print(all)
all=all.apply(scale_minmax,axis=0)
print('================')
print(all)
十七,map,可用来制作类别型特征
import pandas as pd
x = pd.Series(['A', 'B', 'C'], index=['one', 'two', 'three'])
y = {'A': 1, 'B': 2, 'C': 3}
z=x.map(y)
print(x)
print(z)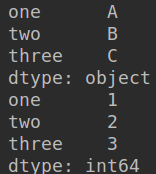
十八,生成csv
import pandas as pd
c={}
a=np.array([1])
b=np.array(['1 2 3 4'])
c['ID']=a
c['Detection']=b
a_df=pd.DataFrame(c)
a_df.to_csv('test16.csv',index=False,columns=['ID','Detection'])十九,给csv空的header增加header,注意在读的时候没有header要将其为None
csv_path = './train_only.csv'
df = pd.read_csv(csv_path,header=None)######注意
print(df.shape)
df_value=df.values
# print(df_value[:-1,1])
# print(len(df_value[:,1]))
df=pd.DataFrame(df_value,columns=['name','xmin','ymin','xmax','ymax','class'])
df.to_csv('train_xml.csv',index=False)二十,loc,iloc,ix,loc——通过行标签索引行数据,iloc——通过行号索引行数据,ix——通过行标签或者行号索引行数据(基于loc和iloc 的混合)
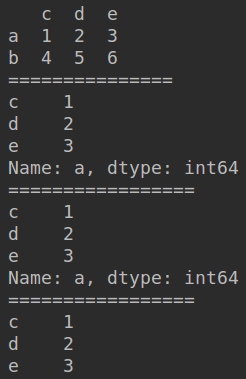
import pandas as pd
data = [[1, 2, 3], [4, 5, 6]]
index = ['a', 'b'] # 行号
columns = ['c', 'd', 'e'] # 列号
df = pd.DataFrame(data, index=index, columns=columns) # 生成一个数据框
print(df)
print('===============')
#loc——通过行标签索引行数据
print(df.loc['a'])
#iloc——通过行号索引行数据
print('=================')
print(df.iloc[0])
#ix——通过行标签或者行号索引行数据(基于loc和iloc 的混合)
print('=================')
print(df.ix[0])
print(df.ix['a'])
print('=================')
print(df.loc[:, ['c']])
print(df.iloc[:, [0]])