版权声明:转载请注明出处 https://blog.csdn.net/nanhuaibeian/article/details/86635129
- 观察页面

为了获得主题和回帖,因此需要关注主题列表以及页码
2.

3. 根据Preview回显,寻找真正的请求链接

- 将真正的Request URL与版面列表抓取的主题列表结果比对
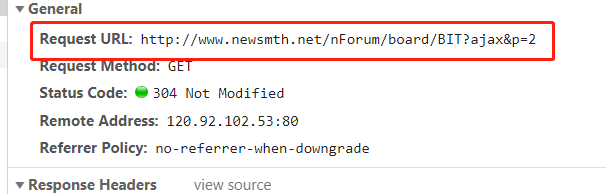

发现请求构成
http://www.newsmth.net/nForum/board/[BoardName]?ajax&p=[page]
Boardname为版面列表中获取的URL
page 为页码
Postman中验证URL,并利用code功能

- 获取列表的整个页面代码
import re
import requests
from lxml import etree
class PostListCrawler:
domain = "https://www.newsmth.net"
#获取整个页面
def get_content(self,board_url,page):
querystring = {"ajax": "", "p": str(page)}
url = self.domain + board_url
r = requests.get(url,params=querystring)
return r.text
if __name__ == "__main__":
plc = PostListCrawler()
print(plc.get_content('/nForum/board/AutoWorld',1))