大数据004——Hadoop
1. 前言
Hadoop是一个开源框架,它允许在整个集群使用简单编程模型计算机的分布式环境存储并处理大数据。它的目的是从单一的服务器到上千台机器的扩展,每一个台机都可以提供本地计算和存储。
1.1 什么是大数据?
大数据是不能用传统的计算技术处理的大型数据集的集合。它不是一个单一的技术或工具,而是涉及的业务和技术的许多领域。大数据包含通过不同设备和应用程序所产生的数据。如这些领域:黑匣子数据、社会化媒体数据、证券交易所数据、电网数据、交通运输数据、搜索引擎数据等。
大数据技术:大数据技术旨在提供更准确的分析,这可以影响更多的具体决策导致更大的效率、降低成本、并减少了对业务的风险。为了充分利用大数据的力量,需要管理和处理实时结构化和非结构化的海量数据,可以保护数据隐私和安全的基础设施。
操作大数据:包括像MongoDB系统,提供业务实时的能力,主要工作是数据捕获和存储互动。NoSQL大数据体系的设计充分利用已经在过去的十年,而让大量的计算,以廉价,高效地运行新的云计算架构的优势。这使得运营大数据工作负载更容易管理,更便宜,更快的实现。一些NoSQL系统可以提供深入了解基于使用最少的编码无需数据科学家和额外的基础架构的实时数据模式。
分析大数据:这些包括,如大规模并行处理(MPP)数据库系统和MapReduce提供用于回顾性和复杂的分析,可能触及大部分或全部数据的分析能力的系统。MapReduce提供分析数据的基础上,MapReduce可以按比例增加从单个服务器向成千上万的高端和低端机的互补SQL提供的功能,这是系统的一种新方法。
1.2 大数据解决方案
-
传统的企业方法
在这种方法中,一个企业将有一个计算机存储和处理大数据。对于存储而言,程序员会自己选择的数据库厂商,如Oracle,IBM等的帮助下完成,用户交互使用应用程序进而获取并处理数据存储和分析。
这种做法存在局限性:这种方式能完美地处理那些可以由标准的数据库服务器来存储,或直至处理数据的处理器的限制少的大量数据应用程序。但是,当涉及到处理大量的可伸缩数据,这是一个繁忙的任务,只能通过单一的数据库瓶颈来处理这些数据。
-
谷歌的解决方案
使用一种称为MapReduce的算法谷歌解决了这个问题。这个算法将任务分成小份,并将它们分配到多台计算机,并且从这些机器收集结果并综合,形成了结果数据集。
扫描二维码关注公众号,回复: 5098067 查看本文章
-
Hadoop
使用谷歌提供的解决方案,Doug Cutting和他的团队开发了一个开源项目叫做HADOOP。Hadoop使用的MapReduce算法运行,其中数据在使用其他并行处理的应用程序。总之,Hadoop用于开发可以执行完整的统计分析大数据的应用程序。
1.3 什么是Hadoop?
Hadoop是使用Java编写,允许分布在集群,使用简单的编程模型的计算机大型数据处理的Apache的开源框架。Hadoop框架应用工程提供跨计算机集群的分布式存储和计算的环境。 Hadoop是专为从单一服务器到上千台机器扩展,每个机器都可以提供本地计算和存储。
在其核心,Hadoop主要有两个层次,即:
- 加工/计算层(MapReduce),以及
- 存储层(Hadoop分布式文件系统)

Hadoop的优势
- Hadoop框架允许用户快速地编写和测试的分布式系统。有效并在整个机器和反过来自动分配数据和工作,利用CPU内核的基本平行度。
- Hadoop不依赖于硬件,以提供容错和高可用性(FTHA),而Hadoop库本身已被设计在应用层可以检测和处理故障。
- 服务器可以添加或从集群动态删除,Hadoop可继续不中断地运行。
- Hadoop的的另一大优势在于,除了是开源的,因为它是基于Java并兼容所有的平台。
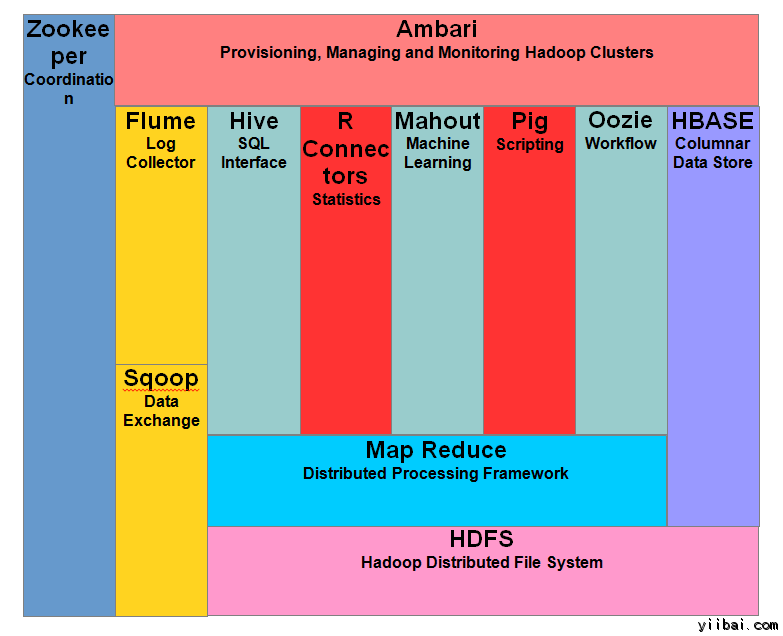
Hadoop 生态系统
2. Hadoop HDFS——分布式文件存储系统
Hadoop文件系统使用分布式文件系统设计开发。它是运行在普通硬件。不像其他的分布式系统,HDFS是高度容错以及使用低成本的硬件设计。HDFS拥有超大型的数据量,并提供更轻松地访问。为了存储这些庞大的数据,这些文件都存储在多台机器。这些文件都存储以冗余的方式来拯救系统免受可能的数据损失,在发生故障时。 HDFS也使得可用于并行处理的应用程序。
2.1 HDFS架构
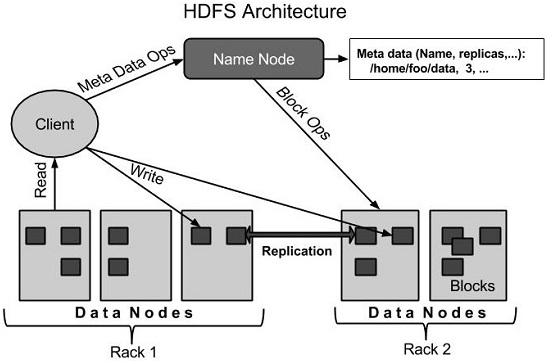
2.2 HDFS 数据存储单元(block)
- 文件被切分成固定大小的数据块block
-
默认数据块大小为128MB (hadoop2.x),可自定义配置;
-
若文件大小不到128MB ,则单独存成一个block;
- 一个文件存储方式
-
按大小被切分成若干个block ,存储到不同节点上;
-
默认情况下每个block都有3个副本;
-
Block大小和副本数通过Client端上传文件时设置,文件上传成功后副本数可以变更,Block Size不可变更
-
hdfs存储模型:字节
文件线性切割成块(Block):偏移量 offset (byte);Block分散存储在集群节点中;单一文件Block大小一致,文件与文件可以不一致;Block可以设置副本数,副本分散在不同节点中;
-
副本数不要超过节点数量
文件上传可以设置Block大小和副本数;已上传的文件Block副本数可以调整,大小不变;只支持一次写入多次读取,同一时刻只有一个写入者;可以append追加数据。
2.3 NameNode
-
NameNode主要功能:
• 接受客户端的读/写服务
• 收集DataNode汇报的Block列表信息
-
基于内存存储 :不会和磁盘发生交换
• 只存在内存中
• 持久化
-
NameNode保存metadata元数据信息
• 文件owership(归属)和permissions(权限)
• 文件大小,时间
• (Block列表B1+B2+…:Block偏移量)
• Block保存在哪个DataNode位置信息(由DataNode启动时上报,不保存)
-
NameNode持久化
• NameNode的metadate信息在启动后会加载到内存
• metadata存储到磁盘文件名为”fsimage”
• Block的位置信息不会保存到fsimage
• edits记录对metadata的操作日志
-
fsimage保存了最新的元数据检查点,类似快照;
-
editslog 保存自最新检查点后的元信息变化,从最新检查点后,hadoop将对每个文件的操作都保存在edits中。客户端修改文件时候,先写到editlog,成功后才更新内存中的metadata信息。
2.4 DataNode
- 本地磁盘目录存储数据(Block),文件形式;
- 同时存储Block的元数据信息文件;
- 启动DN进程的时候会向NameNode汇报block信息;
- 通过向NN发送心跳保持与其联系(3秒一次),如果NN 10分钟没有收到DN的心跳,则认为其已经lost,并copy其上的block到其它DN。
2.5 SecondaryNameNode
它的主要工作是帮助NN合并edits log文件,减少NN启动时间,它不是NN的备份(但可以做备份)。
SNN执行合并时间和机制:
- 根据配置文件设置的时间间隔fs.checkpoint.period 默认3600秒。
- 根据配置文件设置edits log大小 fs.checkpoint.size 规定edits文件的最大值默认是64MB
2.6 SecondaryNameNode SNN合并流程
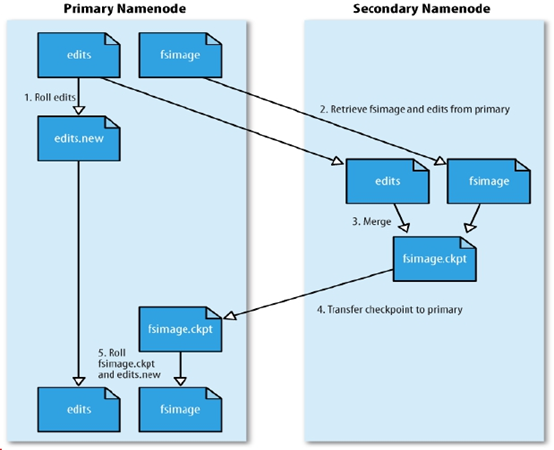
首先是NN中的Fsimage和edits文件通过网络拷贝,到达SNN服务器中,拷贝的同时,用户的实时在操作数据,那么NN中就会从新生成一个edits来记录用户的操作,而另一边的SNN将拷贝过来的edits和fsimage进行合并,合并之后就替换NN中的fsimage。之后NN根据fsimage进行操作(当然每隔一段时间就进行替换合并,循环)。当然新的edits与合并之后传输过来的fsimage会在下一次时间内又进行合并。
2.7 Block的副本放置策略
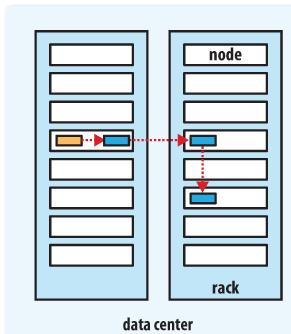
- 第一个副本:放置在上传文件的DN;如果是集群外提交,则随机挑选一台磁盘不太满,CPU不太忙的节点。
- 第二个副本:放置在于第一个副本不同的机架的节点上。
- 第三个副本:与第二个副本相同机架的不同节点。
- 更多副本:随机节点
2.8 HDFS读写流程
2.8.1 在HDFS读操作
数据读取请求将由 HDFS,NameNode和DataNode来服务。让我们把读取器叫 “客户”。下图描绘了文件的读取操作在 Hadoop 中:
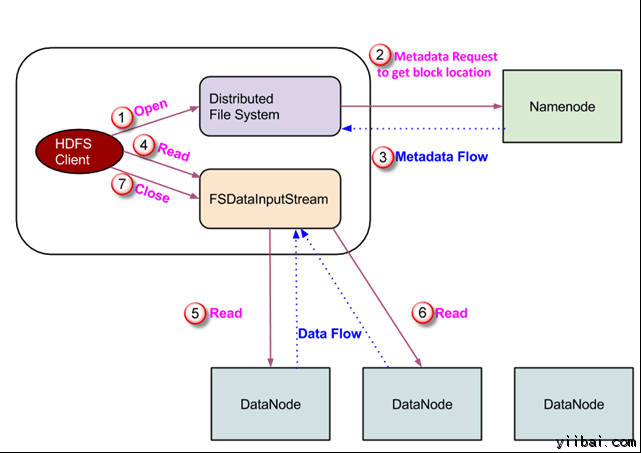
- 客户端启动通过调用文件系统对象的 open() 方法读取请求; 它是 DistributedFileSystem 类型的对象。
- 此对象使用 RPC 连接到 namenode 并获取的元数据信息,如该文件的块的位置。 请注意,这些地址是文件的前几个块。
- 响应该元数据请求,具有该块副本的 DataNodes 地址被返回。
- 一旦接收到 DataNodes 的地址,FSDataInputStream 类型的一个对象被返回到客户端。 FSDataInputStream 包含 DFSInputStream 这需要处理交互 DataNode 和 NameNode。在上图所示的步骤4,客户端调用 read() 方法,这将导致 DFSInputStream 建立与第一个 DataNode 文件的第一个块连接。
- 以数据流的形式读取数据,其中客户端多次调用 “read() ” 方法。 read() 操作这个过程一直持续,直到它到达块结束位置。
- 一旦到模块的结尾,DFSInputStream 关闭连接,移动定位到下一个 DataNode 的下一个块
- 一旦客户端已读取完成后,它会调用 close()方法。
2.8.2 在HDFS写操作
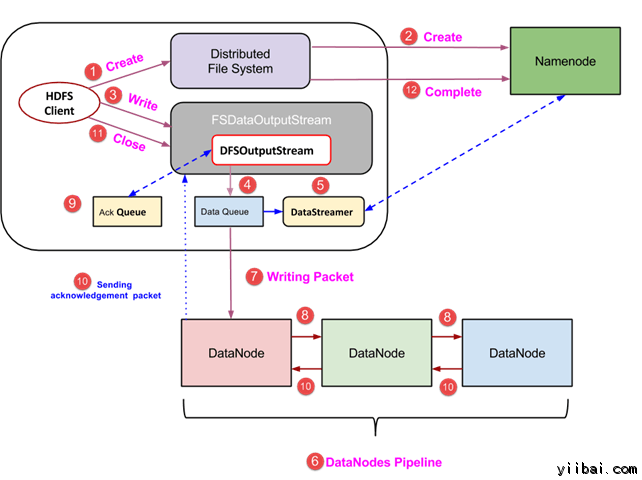
- 客户端通过调用 DistributedFileSystem对象的 create() 方法创建一个新的文件,并开始写操作 - 在上面的图中的步骤1
- DistributedFileSystem对象使用 RPC 调用连接到 NameNode,并启动新的文件创建。但是,此文件创建操作不与文件任何块相关联。NameNode 的责任是验证文件(其正被创建的)不存在,并且客户端具有正确权限来创建新文件。如果文件已经存在,或者客户端不具有足够的权限来创建一个新的文件,则抛出 IOException 到客户端。否则操作成功,并且该文件新的记录是由 NameNode 创建。
- 一旦 NameNode 创建一条新的记录,返回FSDataOutputStream 类型的一个对象到客户端。客户端使用它来写入数据到 HDFS。数据写入方法被调用(图中的步骤3)。
- FSDataOutputStream包含DFSOutputStream对象,它使用 DataNodes 和 NameNode 通信后查找。当客户机继续写入数据,DFSOutputStream 继续创建这个数据包。这些数据包连接排队到一个队列被称为 DataQueue
- 还有一个名为 DataStreamer 组件,用于消耗DataQueue。DataStreamer 也要求 NameNode 分配新的块,拣选 DataNodes 用于复制。
- 现在,复制过程始于使用 DataNodes 创建一个管道。 在我们的例子中,选择了复制水平3,因此有 3 个 DataNodes 管道。
- 所述 DataStreamer 注入包分成到第一个 DataNode 的管道中。
- 在每个 DataNode 的管道中存储数据包接收并同样转发在第二个 DataNode 的管道中。
- 另一个队列,“Ack Queue”是由 DFSOutputStream 保持存储,它们是 DataNodes 等待确认的数据包。
- 一旦确认在队列中的分组从所有 DataNodes 已接收在管道,它从 ‘Ack Queue’ 删除。在任何 DataNode 发生故障时,从队列中的包重新用于操作。
- 在客户端的数据写入完成后,它会调用close()方法(第9步图中),调用close()结果进入到清理缓存剩余数据包到管道之后等待确认。
- 一旦收到最终确认,NameNode 连接告诉它该文件的写操作完成。
3. Hadoop安装(伪分布式搭建)
3.1 jdk安装,配置环境变量
jdk安装略过,配置环境变量(局部变量版):
[root@node01 html]# vim ~/.bash_profile
插入:
JAVA_HOME=/usr/java/jdk1.8.0_191-amd64
PATH=$PATH:$JAVA_HOME/bin
3.2 ssh免密钥(本机)
SSH设置需要在集群上做不同的操作,如启动,停止,分布式守护shell操作。认证不同的Hadoop用户,需要一种用于Hadoop用户提供的公钥/私钥对,并用不同的用户共享。
下面的命令用于生成使用SSH键值对。复制公钥形成 id_rsa.pub 到authorized_keys 文件中,并提供拥有者具有authorized_keys文件的读写权限。
ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
3.3 上传hadoop.tar.gz到服务器
-
解压部署包到指定安装目录下;
-
在~/.bashrc 文件中设置 Hadoop 环境变量:
export HADOOP_PREFIX=/usr/hadoop-2.6.5
PATH=$PATH:$JAVA_HOME/bin:$HADOOP_PREFIX/bin:$HADOOP_PREFIX/sbin
- 确保Hadoop安装正常:
[root@node01 www.shsxt.com]# hadoop version
会出现:
Hadoop 2.6.5
Subversion Unknown -r Unknown
Compiled by root on 2017-05-24T14:32Z
Compiled with protoc 2.5.0
From source with checksum f05c9fa095a395faa9db9f7ba5d754
This command was run using /usr/hadoop-2.6.5/share/hadoop/common/hadoop-common-2.6.5.jar
-
Hadoop配置
找到位置“$HADOOP_HOME/etc/hadoop”下找到所有Hadoop配置文件,这是需要根据Hadoop基础架构进行更改这些配置文件:
-
配置hadoop-env.sh:为了使用Java开发Hadoop程序,必须用java在系统中的位置替换JAVA_HOME值并重新设置hadoop-env.sh文件的java环境变量:
JAVA_HOME=/usr/java/jdk1.8.0_191-amd64 -
配置core-site.xml:core-site.xml文件中包含如读/写缓冲器用于Hadoop的实例的端口号的信息,分配给文件系统存储,用于存储所述数据存储器的限制和大小:
<property> <name>fs.defaultFS</name> <!-- hadoop所在系统IP,或localhost,或host主机名 --> <value>hdfs://node01:9000</value> </property> <property> <name>hadoop.tmp.dir</name> <!-- 指定中转文件夹 --> <value>/opt/hadooplocal</value> </property> -
配置hdfs-site.xml:hdfs-site.xml 文件中包含如复制数据的值,NameNode路径的信息,本地文件系统的数据节点的路径,这意味着是存储Hadoop基础工具的地方:
<property> <name>dfs.replication</name> <!-- 副本个数,默认3个 --> <value>1</value> </property> <property> <name>dfs.namenode.secondary.http-address</name> <value>node01:50090</value> </property> -
配置slaves(datanode节点):
node01
-
-
格式化 hdfs :
hdfs namenode -format -
启动
start-dfs.sh -
查看服务进程启动了么? jps
a) SecondaryNameNode
b) NameNode
c) DataNode
d) Jps
-
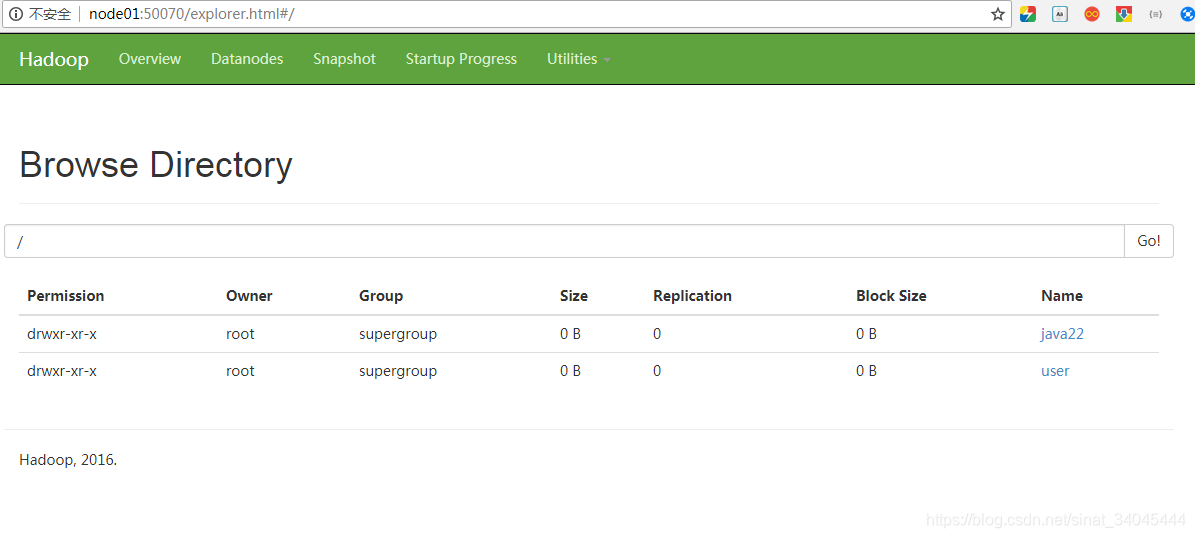
访问 node01:50070 (windows指定了host主机明和IP),确保防火墙关闭(service iptables stop);

显示如下数据:
3.4 hdfs dfs指令
- hdfs dfs -mkdir /user:创建文件夹user;
- hdfs dfs -ls /user:遍历列举文件夹user;
- hdfs dfs -put fileName[本地文件名] PATH[hdfs的文件路径]:上传文件;
- hdfs dfs -du [-s][-h]URI[URI …] 显示文件(夹)大小;
- hdfs dfs -rm -r /user :删除文件夹user;
- hdfs dfs -get fileName[hdf的文件名] PATH[指定本地路径及文件名]:下载文件;
3.5 hdfs dfs测试
-
准备本地待存储的文件:
产生100000条数据:for i in
seq 100000;do echo “hello hadoop $i” >> test.txt;done-rw-r--r--. 1 root root 1888895 Dec 23 03:36 test.txt容量为1.8MB;
-
上传至hdfs:
[root@node01 ~]# hdfs dfs -put test.txt /user/text01.txt -
显示:
[root@node01 ~]# hdfs dfs -ls /user Found 1 items -rw-r--r-- 3 root supergroup 1888895 2018-12-23 03:38 /user/text01.txt
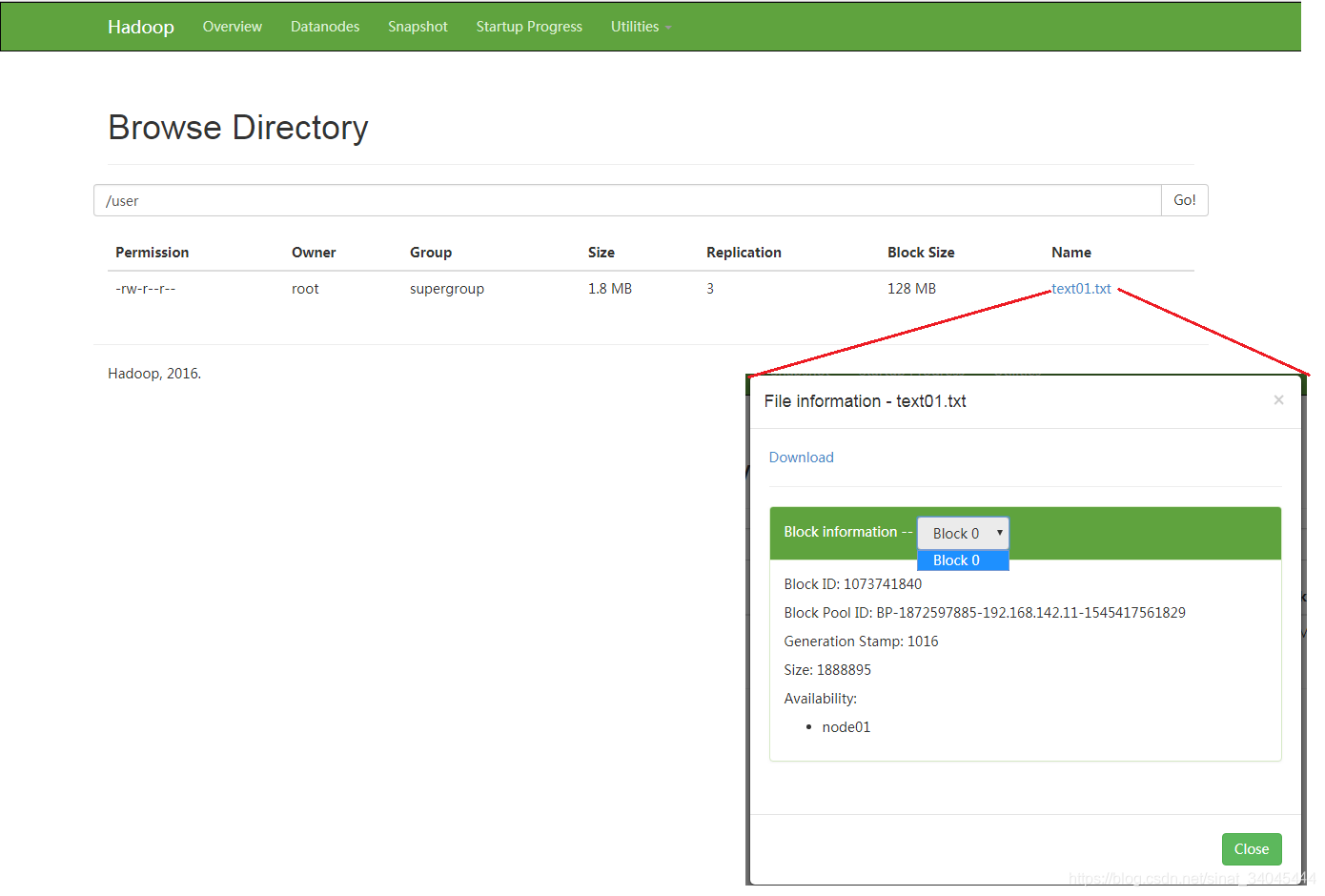
默认数据块大小为128MB,所以只分配一个block块;
-
指定block大小为1MB上传文件:
[root@node01 ~]# hdfs dfs -D dfs.blocksize=1048576 -put test.txt /user/test02.txt -
显示:
[root@node01 ~]# hdfs dfs -ls /user Found 2 items -rw-r--r-- 3 root supergroup 1888895 2018-12-23 03:48 /user/test02.txt -rw-r--r-- 3 root supergroup 1888895 2018-12-23 03:38 /user/text01.txt
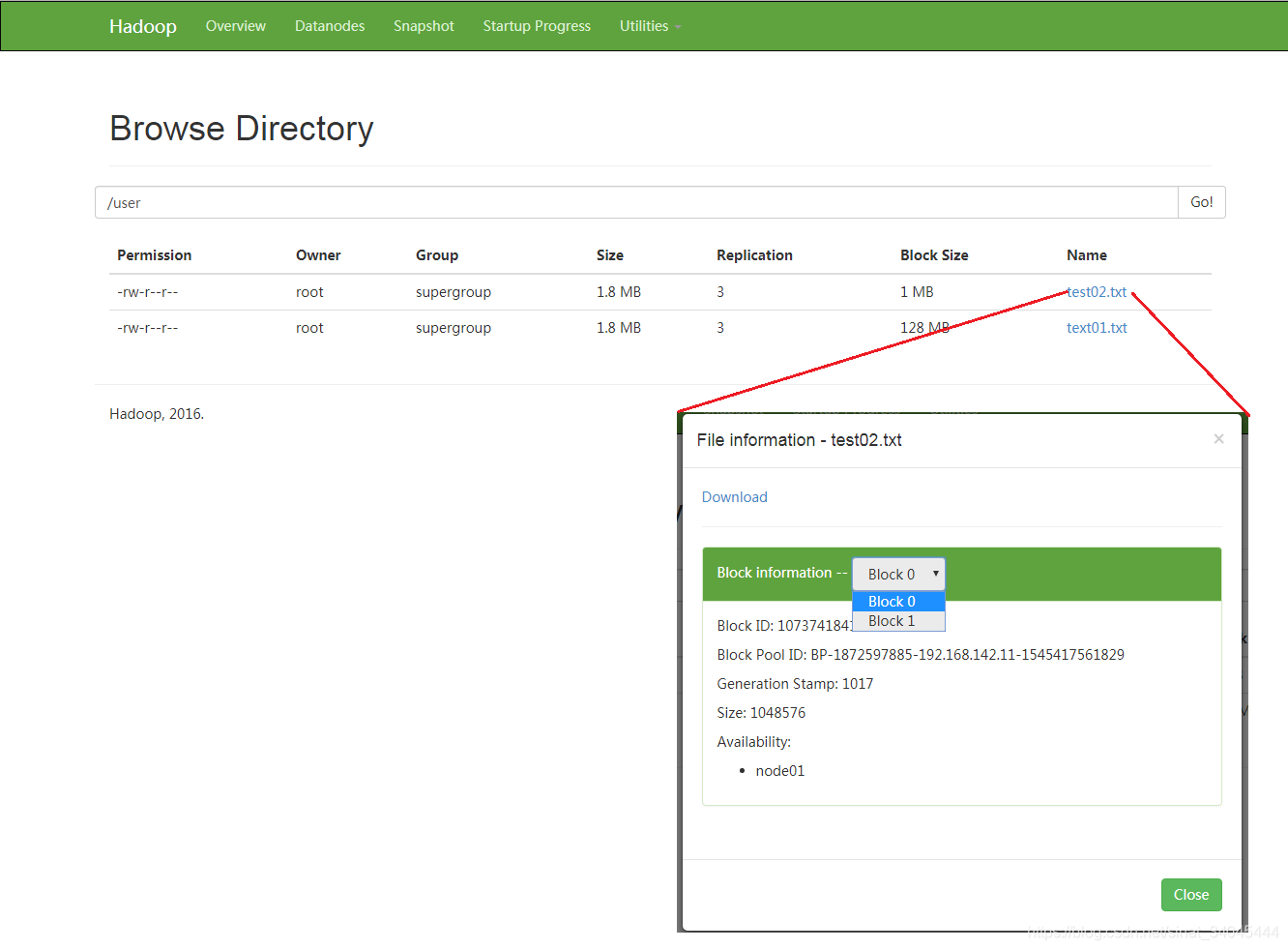
因为指定了block块大小为1MB,所以分配了两个block块。
4. Windows下Java开发环境整合hdfs
4.1 windows上部署hadoop包
-
解压部署hadoop包;
-
bin目录下需具备如下文件:

-
将bin目录下的hadoop.dll 放到 c:/windows/system32下;
-
windows环境变量配置:
HADOOP_HOME = F:\hadoop-2.6.5
HADOOP_USER_NAME = root
-
eclipse插件:将以hadoop-eclipse-plugin-2.6.0.jar包放入eclipse的plugins文件夹中;
启动eclipse:出现界面如下:
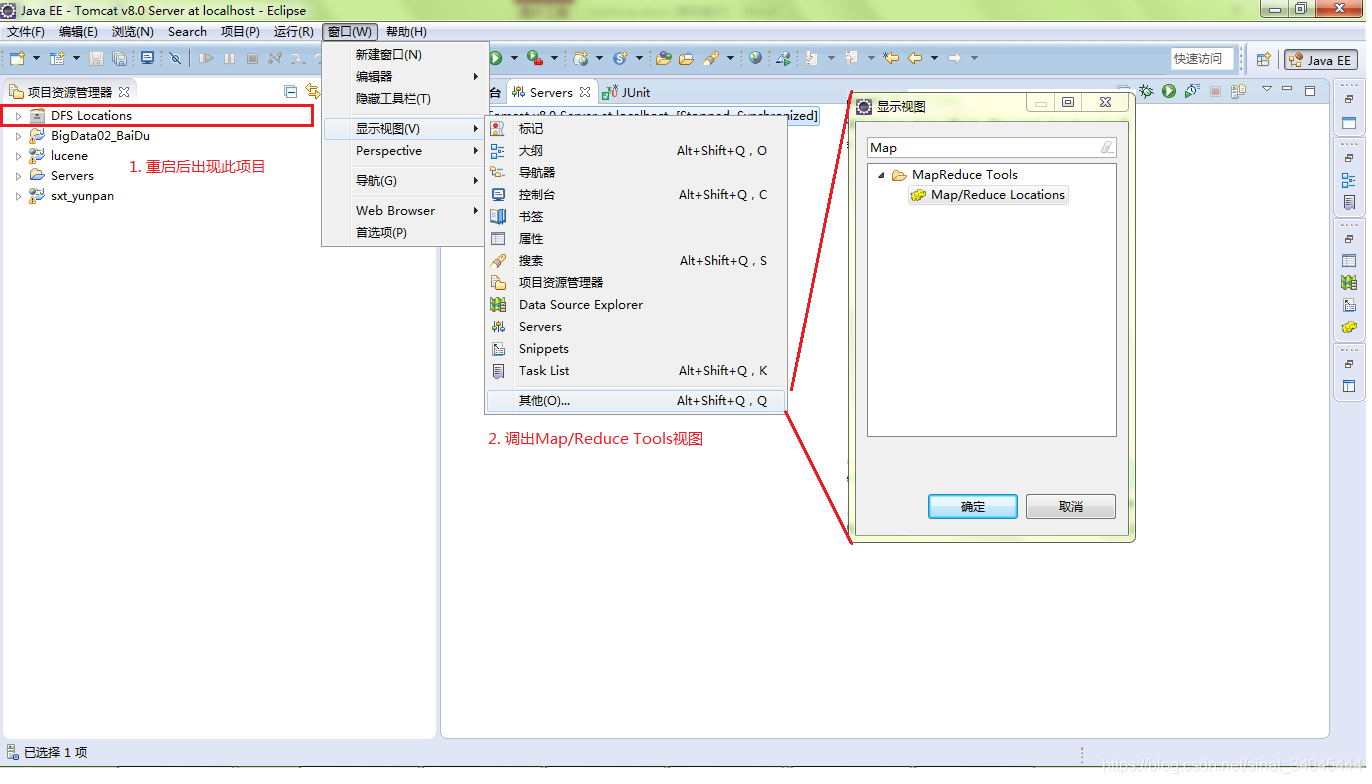
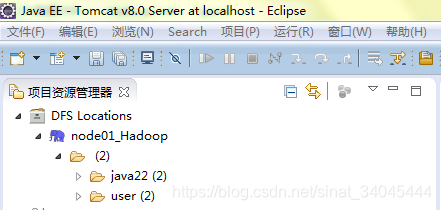
新建Location:

建立连接成功:
4.2 HDFS API测试:
请将linux下hadoop中:core-site.xml与hdfs-site.xml文件导入到java项目src目录下;
创建测试类:
public class HdfsTest {
private static Configuration config;
private static FileSystem fs;
public static void main(String[] args) throws IOException {
// 实例化配置
config = new Configuration();
fs = FileSystem.get(config);
// 创建删除文件夹目录
// mk_deldir();
// 上传文件
// uploadfiles();
// 下载文件
// downloadfiles();
// 查看文件详细信息
ListFilestatus();
// 合并小文件到hdfs
// seqfile();
// block();
}
private static void seqfile() throws IOException {
File dir = new File("D:/123");
Path path = new Path("/jjcc/seq123");
SequenceFile.Writer writer = SequenceFile.createWriter(fs, config, path, Text.class, Text.class, CompressionType.NONE);
for (File ff : dir.listFiles()) {
writer.append(new Text(ff.getName()), new Text(FileUtils.readFileToString(ff, "utf-8")));
}
System.out.println("success !");
}
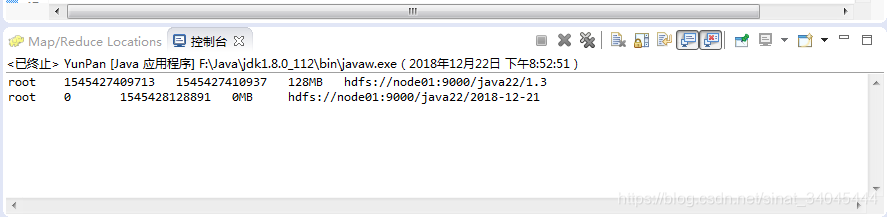
private static void ListFilestatus() throws FileNotFoundException, IOException {
Path path = new Path("/java22");
FileStatus[] fileStatus = fs.listStatus(path);
for (int i = 0; i < fileStatus.length; i++) {
FileStatus status = fileStatus[i];
System.out.println(
status.getOwner()+"\t"+
status.getAccessTime()+"\t"+
status.getModificationTime()+"\t"+
status.getBlockSize()/1024/1024+"MB \t"+
status.getPath()
);
}
}
private static void downloadfiles() throws IOException {
// 要下载的源数据文件放在哪
File files = new File("D:/hadoopDownload/11.pdf");
// 要下载的数据到hdfs的哪个地方
Path path = new Path("/java22/1.3");
// 流 下载==读流程 FSDataInt..
FSDataInputStream in = fs.open(path);
FileOutputStream out = new FileOutputStream(files);
IOUtils.copyBytes(in, out, config);
System.out.println("下载成功");
}
private static void uploadfiles() throws IOException {
// 要上传的源数据文件在哪
File files = new File("D:/大数据001——Linux.pdf");
// 要上传到hdfs的哪个地方
Path path = new Path("/java22/1.3");
// 流 上传==写流程 FSDataOut..
FSDataOutputStream out = fs.create(path);
IOUtils.copyBytes(new FileInputStream(files), out, config);
System.out.println("上传成功");
}
private static void mk_deldir() throws IOException {
// 指定要创建的目录路径
Path path = new Path("/java22");
if(fs.exists(path)){
fs.delete(path,true);
System.out.println("文件目录存在 已删除");
}
fs.mkdirs(path);
System.out.println("创建文件夹目录操作成功~");
}
private static void block() throws IOException {
Path ifile = new Path("/jjcc/test.txt");
FileStatus file = fs.getFileStatus(ifile );
// 获取block的location信息 HDFS分布式文件存储系统根据其偏移量的位置信息来读取其内容
BlockLocation[] blk = fs.getFileBlockLocations(file , 0, file.getLen());
// for (BlockLocation bb : blk) {
// System.out.println(bb);
// }
FSDataInputStream input = fs.open(ifile);
// System.out.println((char)input.readByte());
// System.out.println((char)input.readByte());
// System.out.println((char)input.readByte());
// System.out.println((char)input.readByte());
// System.out.println((char)input.readByte());
// System.out.println((char)input.readByte());
// System.out.println((char)input.readByte());
// System.out.println((char)input.readByte());
// System.out.println((char)input.readByte());
// System.out.println((char)input.readByte());
// System.out.println((char)input.readByte());
// System.out.println((char)input.readByte());
// System.out.println((char)input.readByte());
// System.out.println((char)input.readByte());
//// 指定从哪个offset的位置偏移量来读
input.seek(1048576);
System.out.println((char)input.readByte());
System.out.println((char)input.readByte());
System.out.println((char)input.readByte());
input.seek(1048576);
System.out.println((char)input.readByte());
System.out.println((char)input.readByte());
}
}
结果: