上一篇我们分析到了
Banner printedBanner = this.printBanner(environment);这一行主要就是打印图案

代码执行完这部,你就能看到这个了
接着分析下一步
这一步主要是创建上下文
context = this.createApplicationContext();----->
这个上下文就是AnnotationConfigEmbeddedWebApplicationContext
contextClass = Class.forName(this.webEnvironment ? "org.springframework.boot.context.embedded.AnnotationConfigEmbeddedWebApplicationContext" : "org.springframework.context.annotation.AnnotationConfigApplicationContext");然后会用反射区创建这个实例
return (ConfigurableApplicationContext)BeanUtils.instantiate(contextClass);下面我们进入AnnotationConfigEmbeddedWebApplicationContext
这个类有一个默认的构造函数,
public AnnotationConfigEmbeddedWebApplicationContext() { this.reader = new AnnotatedBeanDefinitionReader(this); this.scanner = new ClassPathBeanDefinitionScanner(this); }
这个构造函数主要做了两件事
实例化AnnotatedBeanDefinitionReader以及ClassPathBeanDefinitionScanner
先看第一句话
this.reader = new AnnotatedBeanDefinitionReader(this);
实例化AnnotatedBeanDefinitionReader
public AnnotatedBeanDefinitionReader(BeanDefinitionRegistry registry) {
this(registry, getOrCreateEnvironment(registry));
}
调用
public AnnotatedBeanDefinitionReader(BeanDefinitionRegistry registry, Environment environment) {
Assert.notNull(registry, "BeanDefinitionRegistry must not be null");
Assert.notNull(environment, "Environment must not be null");
this.registry = registry;
this.conditionEvaluator = new ConditionEvaluator(registry, environment, null);
AnnotationConfigUtils.registerAnnotationConfigProcessors(this.registry);
这里主要关注最后一句话
先看下AnnotationConfigEmbeddedWebApplicationContext的继承体系

这里我们关注GenericApplicationContex他的构造函数和AnnotationConfigEmbeddedWebApplicationContext的构造函数
GenericApplicationContex的构造函数中会赋值一个DefaultListableBeanFactory如下:
public GenericApplicationContext() {
this.beanFactory = new DefaultListableBeanFactory();
}这里就规定了上下的工厂是一个DefaultListableBeanFactory
接下去的代码都是这样的格式
if (!registry.containsBeanDefinition(CONFIGURATION_ANNOTATION_PROCESSOR_BEAN_NAME)) {
RootBeanDefinition def = new RootBeanDefinition(ConfigurationClassPostProcessor.class);
def.setSource(source);
beanDefs.add(registerPostProcessor(registry, def, CONFIGURATION_ANNOTATION_PROCESSOR_BEAN_NAME));
}这个里就是在容器中注入一个bean,利用RootBeanDefinition注入,接着看registerPostProcessor方法
private static BeanDefinitionHolder registerPostProcessor(
BeanDefinitionRegistry registry, RootBeanDefinition definition, String beanName) {
definition.setRole(BeanDefinition.ROLE_INFRASTRUCTURE);
registry.registerBeanDefinition(beanName, definition);
return new BeanDefinitionHolder(definition, beanName);
}这里会返回一个BeanDefinitionHolder。
总结一下就是在DefaultListableBeanFactory的BeanDefinitionMap中注入一些bean信息。关于BeanDefinitionMap的详解会在后续的refresh方法中说明。最后在BeanDefinitionMap中会有以下的元素

回到AnnotationConfigEmbeddedWebApplicationContext构造器
接下去执行这句话
this.scanner = new ClassPathBeanDefinitionScanner(this);
从名字也能看出这是一个起扫描组件功能的组件,跟踪进去最重要的一句话是
if (useDefaultFilters) {
registerDefaultFilters();
}这里面主要是加入一些过滤规则,执行完这句话之后我们发现ClassPathBeanDefinitionScanner的includeFilters的长度变成了2,里面增加了componet和 ManagedBean两种过滤规则,后面一种不太懂,想了解可以自行百度
自此,AnnotationConfigEmbeddedWebApplicationContext初始化完毕,回到run方法本身,
contex就是AnnotationConfigEmbeddedWebApplicationContext
------------------------->
我们接着分析analyzers = new FailureAnalyzers(context);
从名字我们可以看出,这肯定和错误分析相关
进入初始化方法
FailureAnalyzers(ConfigurableApplicationContext context, ClassLoader classLoader) {
Assert.notNull(context, "Context must not be null");
this.classLoader = (classLoader == null ? context.getClassLoader() : classLoader);
this.analyzers = loadFailureAnalyzers(this.classLoader);
prepareFailureAnalyzers(this.analyzers, context);
}关注第三句话,进入候还是老面孔,SpringFactoriesLoader .loadFactoryNames,这里不细说了,最终返回的一个FailureAnalyzer集合石这样的
private List<FailureAnalyzer> loadFailureAnalyzers(ClassLoader classLoader) {
List<String> analyzerNames = SpringFactoriesLoader
.loadFactoryNames(FailureAnalyzer.class, classLoader);
List<FailureAnalyzer> analyzers = new ArrayList<FailureAnalyzer>();
for (String analyzerName : analyzerNames) {
try {
Constructor<?> constructor = ClassUtils.forName(analyzerName, classLoader)
.getDeclaredConstructor();
ReflectionUtils.makeAccessible(constructor);
analyzers.add((FailureAnalyzer) constructor.newInstance());
}
catch (Throwable ex) {
log.trace("Failed to load " + analyzerName, ex);
}
}
AnnotationAwareOrderComparator.sort(analyzers);
return analyzers;
}
分析之前我们先看一下FailureAnalyzers 的继承体系
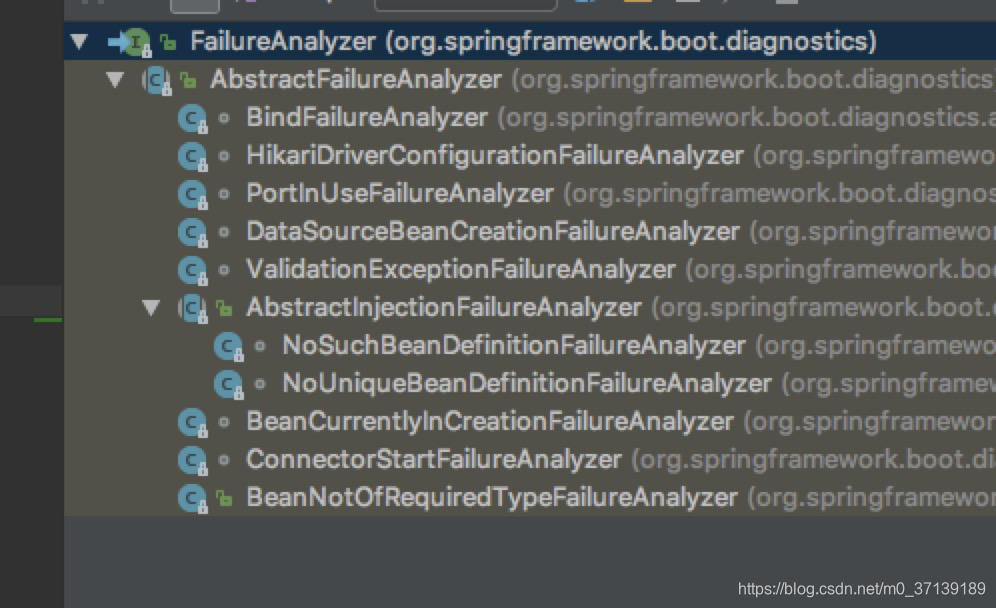
接口只有一个方法 FailureAnalysis analyze
我们看抽象类AbstractFailureAnalysis的analyze
public FailureAnalysis analyze(Throwable failure) {
// 1. 获得failure中的异常堆栈中是type类型的异常
T cause = findCause(failure, getCauseType());
if (cause != null) {
// 2. 如果不等于null,则进行分析
return analyze(failure, cause);
}
// 3. 返回null
return null;
}
AbstractInjectionFailureAnalyzer
是一个和bean注入相关的基类,我们直接看他两个实现类
NoUniqueBeanDefinitionFailureAnalyzer
从名字也能看出这个类的名字我们知道这是一个分析spring容器中有两个相同id的bean的错误的类,我们举一个NoUniqueBeanDefinitionException的例子
比如我们定义了一个接口,但是有两个实现类,同时在xml中声明了两个实现类,而且在依赖注入的时候使用AutoWired,这时候就会报这种异常。
BeanCurrentlyInCreationFailureAnalyzer–>继承自AbstractFailureAnalyzer,泛型参数为BeanCurrentlyInCreationException.对BeanCurrentlyInCreationException(循环依赖)进行分析
我们知道单例模式下通过set方法注入的bean不会出现循环依赖问题,但是如果这个bean是原型模式,或者这个bean是通过构造器注入的,那就会出现循环依赖问题。至于原因我们在解析refresh方法中详解
其他的Exception我这边就不分析,有兴趣的读者可以自行百度
本节完。。