MapTask并行度
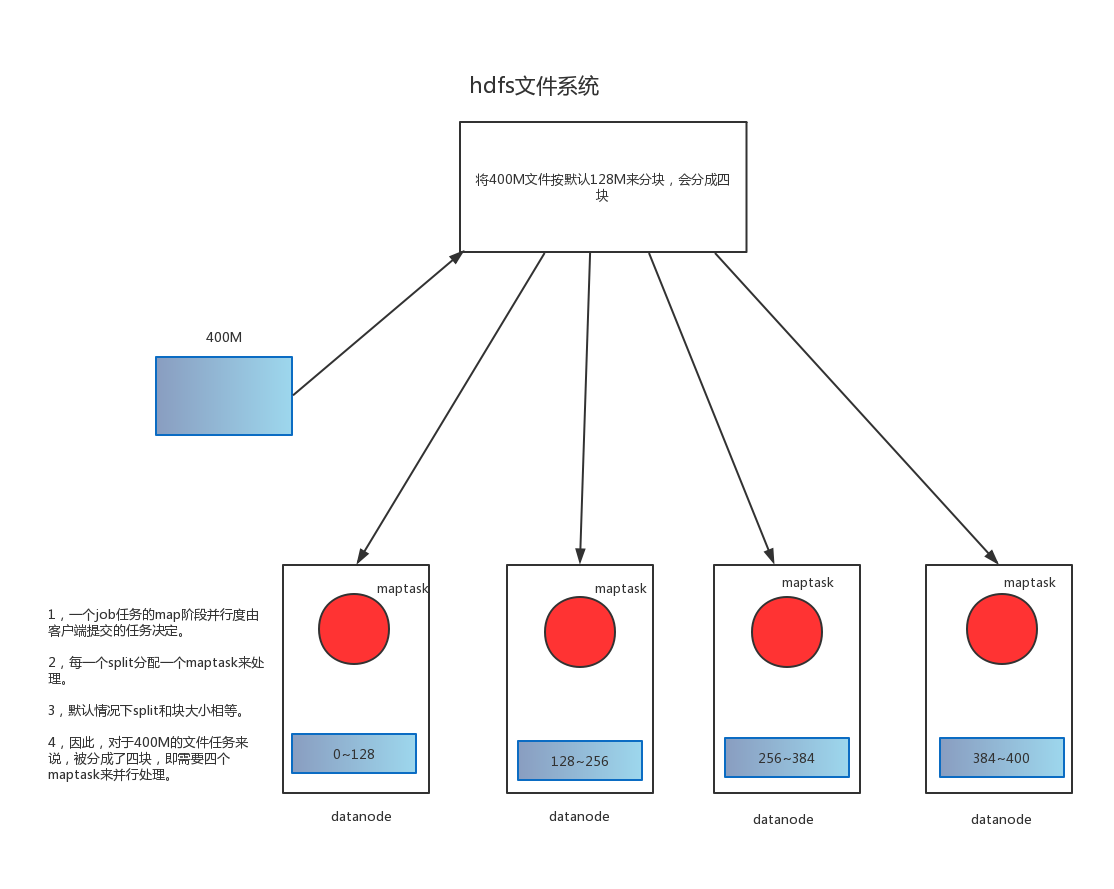
前文提到MapReduce程序包含两个阶段——Map阶段和Reduce。在提交一个Job任务时,在Map阶段会根据提交的任务,来决定需要开启多少个MapTask来执行。
split表示针对每一个文件的单独切片,即,每一个split,会分配到一个maptask进行处理,而默认情况下,split的大小和block的大小一致,即128M,有多少个block,就需要开启多少个MapTask。如上图中,一个400M的文件,在HDFS文件系统默认情况下会被分成四块,那么,在提交Job处理此文件时,Map阶段需要开启四个MapTask。
block是hdfs分布式文件系统的基本单位,默认为128M。因为是基本单位,所以,当处理的文件是小文件,如几M或几百K时,也需要分出一个block来存储文件。实际应用中,如果HDFS文件系统已经存在大量的小文件,即处理大量的block,那么,在执行MapReduce时,一个block开启一个maptask,而处理的文件实际只有几M或几百K,就会造成很大的资源浪费。
下面通过分析MapTask运行机制来优化处理小文件的MapReduce程序。
MapTask运行机制
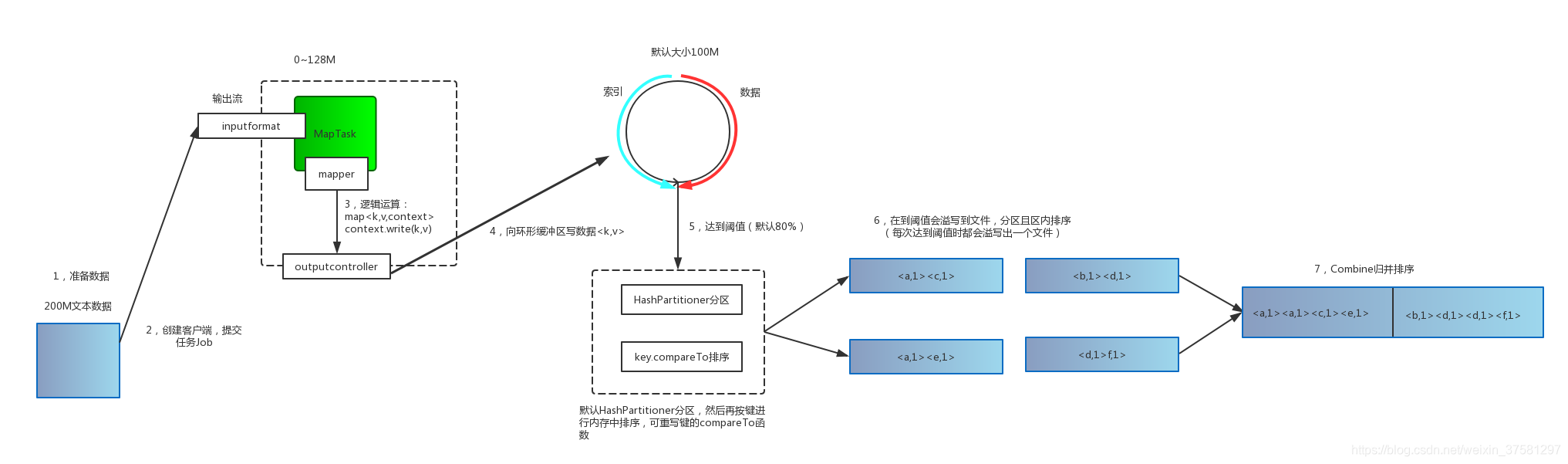
上图属于MapTask的运行机制。
需求:现在需要处理一个200M的文本文件,按照默认设置,需要开启两个MapTask来处理,其中一个MapTask处理数据是128M。
- 创建客户端,提交任务Job,通过InputFormat把数据传输给MapTask。
- MapTask经过mapper函数,对数据进行切分,并把结果交给outputcontroller。
- outputcontroller把数据写入到一个环形缓冲区,环形缓冲区一边是索引,一边是数据,默认大小为100M。
- 当写入缓冲区的数据达到一个阈值时(默认80%即80M),会溢写到一个文件,此时会经过HashPartitioner分区(默认分区)和按键进行内存中排序。
- 如果定义了一个Combine函数,在排序输出后,会把数据进行归并成一个已分区且已排序的输出文件。相当于在传输给Reduce阶段前先进行一次归并,以使map输出结果更紧凑。
指定InputFormat方式
InputFormat是提交任务时,数据传输的方式,默认实现是org.apache.hadoop.mapreduce.lib.input.TextInputFormat,会根据block来启动MapTask。
若要针对小文件处理,则需要重新指定InputFormat方式为org.apache.hadoop.mapred.lib.input.CombineTextInputFormat。
以WordCountDriver为例,需要指定InputFormat方式:
package com.even.mr;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.CombineTextInputFormat;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
/**
* Project Name: Web_App
* Des:
* Created by Even on 2018/12/13
*/
public class WordCountDriver {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
/*1,获取Job信息*/
Configuration configuration = new Configuration();
Job job = Job.getInstance(configuration);
/*2,获取driver包,此处即WorkCountDriver类*/
job.setJarByClass(WordCountDriver.class);
/*3,设置mapper和reduce*/
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReduce.class);
/*4,设置Mapper阶段数据输出类型*/
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
/*5,设置reduce阶段数据输出类型*/
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
/*指定InputFormat的方式*/
job.setInputFormatClass(CombineTextInputFormat.class);
/*指定最大值*/
CombineTextInputFormat.setMaxInputSplitSize(job, 4194304);
/*指定最小值*/
CombineTextInputFormat.setMinInputSplitSize(job, 3145728);
/*6,设置输入存在的路径与处理后的结果路径*/
FileInputFormat.setInputPaths(job, new Path("/in"));
FileOutputFormat.setOutputPath(job, new Path("/out"));
/*7,提交任务*/
boolean b = job.waitForCompletion(true);
System.out.println(b ? 1 : 0);
}
}
指定分区
环形缓冲区的数据如果达到阈值,会溢写到文件,溢写时,会先进行分区,再进行键内排序。默认分区是HashPartitioner,分区数为1。
若要重写,需要继承org.apache.hadoop.mapreduce.Partitioner:
package com.even.flow;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Partitioner;
/**
* des:
* author: Even
* create date:2018/12/27
*/
public class FlowPartitioner extends Partitioner<Text, FlowBean> {
@Override
public int getPartition(Text text, FlowBean flowBean, int i) {
String phoneHead = text.toString().substring(0, 3);
int partitioner = 4;
switch (phoneHead) {
case "135":
return 0;
case "137":
return 1;
case "138":
return 2;
case "139":
return 3;
default:
return partitioner;
}
}
}
修改Driver驱动类:
/*设置分区*/
job.setPartitionerClass(FlowPartitioner.class);
/*指定ReduceTask数,需要大于等于分区数*/
job.setNumReduceTasks(5);
键内排序
分区之后会执行键内排序key.compareTo。自定义compareTo函数,需要重写key类型的compareTo函数。
举例说明:
FlowBean是自定义的Map输出键类型,需要实现org.apache.hadoop.io.WritableComparable:
package com.even.flow;
import org.apache.hadoop.io.WritableComparable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
/**
* des:
* author: Even
* create date:2018/12/27
*/
public class FlowBean implements WritableComparable<FlowBean> {
private long upFLow;
private long downFlow;
private long flowSum;
public FlowBean() {
}
public FlowBean(long upFLow, long downFlow) {
this.upFLow = upFLow;
this.downFlow = downFlow;
this.flowSum = upFLow + downFlow;
}
@Override
public void write(DataOutput dataOutput) throws IOException {
dataOutput.writeLong(upFLow);
dataOutput.writeLong(downFlow);
dataOutput.writeLong(flowSum);
}
@Override
public void readFields(DataInput dataInput) throws IOException {
upFLow = dataInput.readLong();
downFlow = dataInput.readLong();
flowSum = dataInput.readLong();
}
long getUpFLow() {
return upFLow;
}
public void setUpFLow(long upFLow) {
this.upFLow = upFLow;
}
long getDownFlow() {
return downFlow;
}
public void setDownFlow(long downFlow) {
this.downFlow = downFlow;
}
public long getFlowSum() {
return flowSum;
}
public void setFlowSum(long flowSum) {
this.flowSum = flowSum;
}
@Override
public String toString() {
return upFLow + "\t" + downFlow + "\t" + flowSum;
}
/*分区后进行键内排序,因此,需要把FlowBean设置为Map阶段输出Key类型才可以执行排序*/
@Override
public int compareTo(FlowBean o) {
return this.flowSum > o.getFlowSum() ? -1 : 1;
}
}
Combiner归并
combiner归并是在把Map阶段输出的数据传输到Reducer端前进行一次归并的意思,因此,跟Reducer类似,需要继承Reducer方法。Combiner归并属于局部汇总,作用是减少网络传输量,使数据更紧凑,进而优化程序,只有在不影响最终业务逻辑的情况下才可以使用。
举例说明:
package com.even.flow;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
/**
* des: 输入键类型和值类型是Map输出的键和值类型。输出键类型和值类型是Reducer类输入键类型和值类型。
* author: Even
* create date:2018/12/27
*/
public class FlowCountCombiner extends Reducer<Text, FlowBean, Text, FlowBean> {
@Override
protected void reduce(Text key, Iterable<FlowBean> values, Context context) throws IOException, InterruptedException {
long upFlow_sum = 0;
long downFlow_sum = 0;
for (FlowBean flowBean : values) {
upFlow_sum += flowBean.getUpFLow();
downFlow_sum += flowBean.getDownFlow();
}
context.write(key, new FlowBean(upFlow_sum, downFlow_sum));
}
}
修改Driver驱动:
//指定Combiner类,
job.setCombinerClass(FlowCountCombiner.class);