课程讲解点
神经网络、卷积神经网络和深度学习
Neural networks, convolutional neural networks and deep learning
影响图片分辨的因素:
- 所有的像素随着观测角度而改变
- 光照强度改变像素
- 物体的变形(不同形态)
- 遮挡了观测的物体
- 背景的干扰
- 同物种之间有不同特征
可尝试进行分辨的方法
- 找边,再找角 : 计算出图像的边,之后尝试将不同的角和边界进行分类。然后根据这一规则去辨别物体。
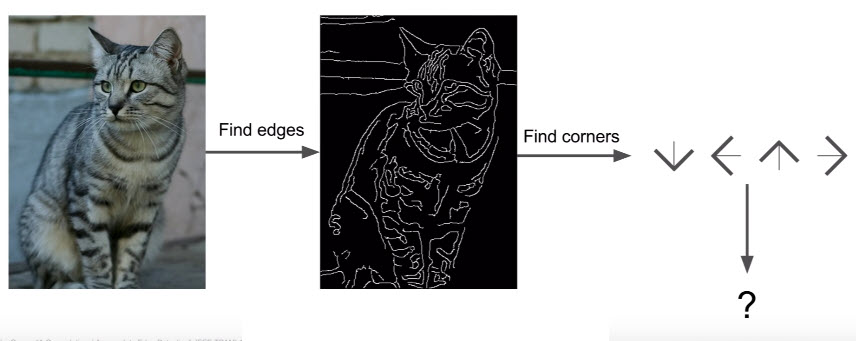
不是一个好方法,对很多相似的图形将无法分类。
- 数据驱动法
-
- 收集图片及其标签中的数据集
-
- 使用机器学习的方法来训练分类器其进行分类
-
- 使用新的照片来对该分类器进行评测
分类器
比较图像的方法
通过距离度量来比较图像
由曼哈顿距离或L1 distance决定~
假设图像很小,仅仅是4×4像素,
距离是测试图像的数组减去训练图像的数组的绝对值得到的数组的所有元素的和
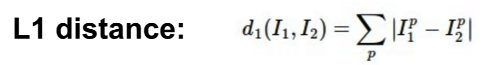
Neareat Neighbor
最简单的方法~
在训练过程(train)中,不用做其他的事,仅仅需要记住所有的训练数据。
在预测过程(predict)中,用一些新图像,运行后在训练的数据中找到最相似的图像,于是预测相似图像的标签(labels)。
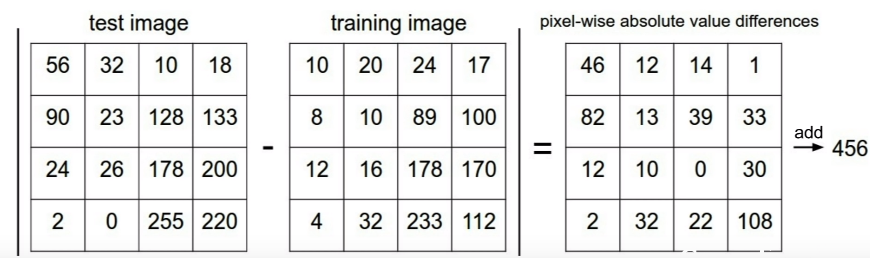

说明这俩图的区别是456
实现代码:
import numpy as np
class NearestNeighbor:
def _init_(self):
pass
def train(self,X,y):
# X是一个有N行,D列的数组
# y是一个大小为N的一维数组
# 因为NearestNeighbor分类器只会记住所有的训练数据
self.Xtr=X
self.ytr=y
def predict(self,X):
num_test=X.shape[0] # num_test是数组X的行数
# 确保输出的类型可以匹配输入类型
Ypred=np.zeros(num_test,dtype=self.ytr.dype)
for i in xrange(num_test):
# 从第i个测试图像找到离训练图像最近的点
# 使用L1距离
distances=np.sum(np.abs(self.Xtr - X[i,:]), axis=1)
min_index=np.argmin(distances)
Ypred[i]=self.ytr[min_index]
return Ypred
发现该算法是低效的。
因为Train是 O(1),而Predict是O(n)。
而我们所希望的是Predict上花费的时间更短,而Train上则可以多花费一些时间也没关系。
K-Neareat Neighbors
从图中找K各最短路径而不是仅仅一个,然后每个neighbors都会投一票,而预测时通过大多数neighbors的投票确定。
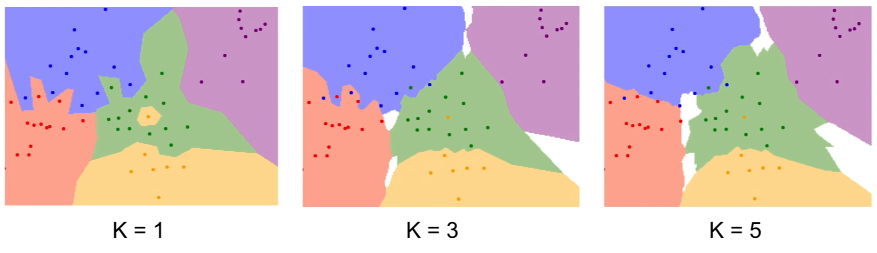
K越大,图片越平滑,噪点越少,分类结果更好。
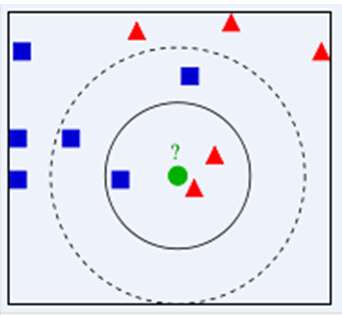
当k取3时,红色占有2/3,关于中间那个绿色点应该类属红色。
当k取54时,蓝色占有3/5,则中间那个绿点应该属于蓝色。
思想总结:
在训练集中数据和标签已知的情况下,输入测试数据,将测试数据的特征与训练集中对应的特征进行相互比较,找到训练集中与之最为相似的前K个数据,则该测试数据对应的类别就是K个数据中出现次数最多的那个分类。
算法描述:
-
计算测试数据与各个训练数据之间的距离;
-
按照距离的递增关系进行排序;
-
选取距离最小的K个点;
-
确定前K个点所在类别的出现频率;
-
返回前K个点中出现频率最高的类别作为测试数据的预测分类。
由欧式距离或L2 distance决定~
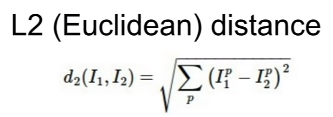
如何选择l1 和 l2 距离呢?⬇
实际上,l1距离取决于选择的坐标系。如果要旋转坐标系,这一操作实际上会改变点与点之间的l1距离
而改变l2坐标系则没关系,距离l2与坐标系无关系。
选择的手段
-
如果在任务中,数组存在些各别项有一些重要的含义则选择l1距离更加合适。
-
如果在你的任务中,只是某个空间的一个一般向量,你不清楚不同的元素实际意味着什么,那么l2距离更加合适。
查看L1和L2选取的区别即K大小影响分类的关系:
Parameters && Hyperparameters
~~参数与超参数
- 参数是模型通过学习得到的变量,比如权重w和偏置b
- 超参数是根据经验进行设定,影响到权重w和偏置b的大小,如,迭代次数、学习速率等。是由人为设定或者算法决定的。
超参数
不能从数据中直接得到,那么如何选择合适的呢?
- 最简单的方法是尝试多个值,选择在给定的数据中表现最好的那个作为超参数。
这种方法很糟糕,因为通常K=1时表现最佳。

- 将数据分成训练数据和测试数据,选择对测试数据最有效的超参数。
这种方法也不太好,该选取的超参数取通常仅仅在测试数据中表项良好,而在待测试的数据中表项就不尽人意了,因为不具有代表性。

- 将数据分为训练集、确认集和测试集;使用不同的超参数对训练集进行训练,然后使用确认集来对之进行评测,选取在这之中表现最好的作为超参数。表现最佳的分类器在测试集运行一次便可。
该方法相较之前更好!
其中,
| Set | 用途 |
|---|---|
| training set | 用来训练模型 |
| validation set | 用来选出超参数–确定模型 |
| test set | 用来评估所选出来的模型的实际性能 |

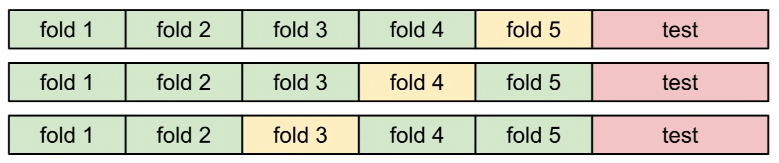
- Cross-Validation(交叉验证):将训练数据分成许多不同的组,然后循环选择哪个组将成为validation set。然后对结果去平均值。
对于小的数据集很有用,但在深度学习中不常使用。
K-Neareat Neighbors
该方法一般不用于做图像分类器。
测试时间非常慢
像素间的距离不能提供有效的信息。⬇
如:

又如:维数之灾~
点密集分布在空间中,意味着我们需要许多指数级的训练例子,是一个随着维数的增长,代价异常昂贵的。且无法得到足够的图像来密集地覆盖这些像素的高维空间。
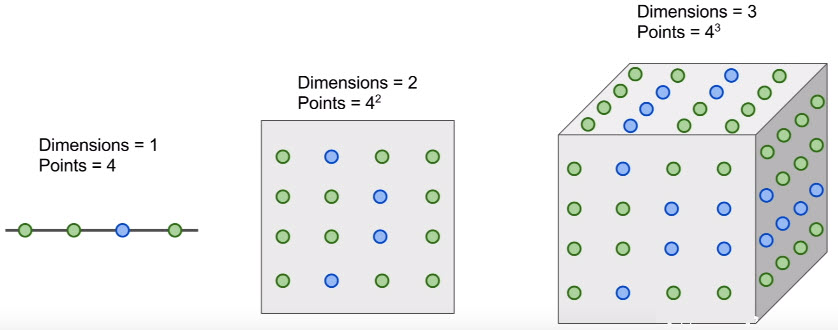
其中,每种颜色的点代表训练样本中的图像种类。
所以在1维中,可能只需要4个训练样本来密集地覆盖空间。
若变成2维的,则可能需要16个训练样本了。
而3、4、5、···样本的增长呈现指数级。
引用~~https://www.cnblogs.com/ybjourney/p/4702562.html