Hbase入门(上)
简介:
HBase–Hadoop Database,是一个高可靠性,高性能,面向列,可伸缩,实时读写的分布式数据库。
在Hadoop生态圈,它是其中一部分且利用Hadoop HDFS作为其文件存储系统,利用Hadoop MapReduce来处理Hbase中的海量数据。利用Zookeeper作为其分布式协同服务,主要用来存储非结构化和半结构化的松散数据(NoSql非关系型数据库 redis, MongoDB等)。


一,对比关系型数据库
关系型数据库的三大优点:
----容易理解: 二维表的结构是非常贴近逻辑世界的一个概念,关系模型相对网状,层次等其他模型老说更容易理解。
----使用方便: 通用的SQL语言使得操作关系型数据库非常方便
----易于维护: 丰富的完整性(实体完整性,参照完整性和用户定义的完整性,大大减低了数据冗余和数据不一致的概率)
关系型数据库的三大瓶颈:
----高并发读写需求: 网站的用户并发性非常高,往往达到每秒上万次读写请求,对于传统关系型数据库来说,磁盘IO是一个很大的瓶颈,并且很难能做到数据的强一致性。
----海量数据的读写性能低:网站每天产生的数据量是巨大的,对于关系型数据库来说,在一张包含海量数据的表中查询,效率是非常低的。
----扩展性和可用性差:在基于web的结构当中,数据库是最难(但是可以)进行横向扩展的,当一个应用系统的用户量和访问量与日俱增的时候,数据库却没有办法像web server和app server那样简单的通过添加更多的硬件和服务节点来扩展性能和负载能力。对于很多需要提供24小时不间断服务的网站来说,对数据库系统进行升级和扩展是非常痛苦的事情,往往需要停机维护和数据迁移。
PS:当然,对网站来说,关系型数据库的很多特性不再需要了,比如:事务一致性、读写实时性 。在关系型数据库中,**导致性能欠佳的最主要原因是多表的关联查询,以及复杂的数据分析类型的复杂SQL报表查询。**为了保证数据库的ACID特性,我们必须尽量按照其要求的范式进行设计,关系型数据库中的表都是存储一个格式化的数据结构。
非关系型数据库特点
一般不支持ACID特性,无需经过SQL解析,读写性能高
存储格式: key value 键值对,文档 ,图片等…
数据没有耦合性,容易扩展
但非关系型数据库由于很少的约束,它也不能够提供像SQL所提供的where这种对于字段属性值情况的查询。并且难以体现设计的完整性。他只适合存储一些较为简单的数据,对于需要进行较复杂查询的数据,SQL数据库显的更为合适
非关系型数据库依据结构化方法以及应用常用的不同,主要分为以下几类:
1.面向高性能并发读写的key-value 数据库,Redis Tokyo GAbinet Flare
2.面向海量数据访问的面向文档数据库,MongoDB以及 CouchDB,可以在海量的数据中快速的查询数据
3.面向可扩展性的分布式数据库:这类数据库解决的问题主要就是传统数据库存在可扩展性上的缺陷,这类数据库可以适应数据量的增加以及数据结构的变化。


二,Hbase数据类型


2.1 ROW KEY
决定一行数据 (保证唯一性)
按照字典顺序排序
Row Key 最大只能存储64kb的字节数据
2.2 Column Family 列族 & qualifier 列
HBase表中的每一个列都归属某个列族,列族必须作为表模式(schema),只能创建表的时候规定。
列名以列族作为前缀,每个“列族”都可以有多个列成员(column),列可以动态添加,权限控制,存储以及调优都是在列族层面进行的
HBase把同一列族里面的数据存储在同一目录下,由几个文件保存。
2.3 Cell单元格
由行和列的坐标交叉决定,单元格是有版本的。
单元格的内容是未解析的字节数组。
由{row key, column( =+), version } 唯一确定的单元格。cell中的数据是没有类型的,全部都是字节码形式存贮。
2.4 Timetamp 时间戳
在HBase每个cell存储单元对同一份数据有多个版本,根据唯一的时间戳来区分每个版本之间的差异,不同版本的数据按照时间倒序排序,最新的数据版本排在最前面。
时间戳的类型是 64位整型。
时间戳可以由HBase(在数据写入时自动)赋值,此时时间戳是精确到毫秒的当前系统时间。 时间戳也可以由客户显式赋值,如果应用程序要避免数据版本冲突,就必须自己生成具有唯一性的时间戳。
2.5 HLog(WAL log)
HLog文件就是一个普通的 Hadoop SequenceFile , SequenceFile的Key是 HLogKey对象HlogKey中记录了写入数据的归属信息,除了table和region名字外,同时还包括 sequence number和 timestamp, timestamp是写入时间,sequence number的起始值为0,或者是最近一次存入文件系统中的 sequence number.
HLog SequenceFile的 Value是HBase的KeyValue对象,即对应HFile中的KeyValue。存储hbase表的操作记录,KV数据信息。
三,Hbase体系架构


3.1 Client
包含访问HBase的接口并维护cache来加快对HBase的访问
3.2 Zookeeper
保证任何时候,集群中只有一个master
存储所有Region的寻址入口
实时监控 Region server的上线和下线信息,并实时通知 master
存储HBase的schema和table元数据
3.3 master
为 Region server分配region
负责Region server的负载均衡
发现失效的Region server并重新分配其上的region
管理用户对table的增删改操作
3.4 RegionServer
RegionServer负责维护region,处理对这些region的IO请求,RegionServer负责切分在运行过程中变得过大的region
3.5 Region
HBase自动把表水平划分成多个区域(region),每个region会保存一个表里面某段连续的数据,每个表一开始只有一个region,随着数据不断的增加,region不断增大,当增大到一个阀值时,region就会等分成两个新的region(分裂)。
当table中的行不断增多,就会有越来越多的region。这样一张完整的表被保存在多个RegionServer上。
3.6 Memstore 和 storefile
一个region由多个store组成,一个store对应一个列族。
store包括位于内存中的memstore和位于磁盘的storefile。写操作写写入memstore中,当memstore中的数据达到某个阀值时,**hregionserver会启动flashcache进程写入storefile,**每次写入形成单独的一个storefile;当storefile文件的数量增长到一定阀值后,系统会进行合并(minor,major,compaction),在合并过程中会进行版本合并和删除工作(majar),形成更大的storefile。
当一个region所有storefile的大小和数量超过一定阀值后,会把当前的region分割成两个,并由hmaster分配到相应的 RegionServer节点上,实现负载均衡
3.7 关于客户端查找数据
客户端检索数据时,会先去memstore中找,找不到再去storefile中找
HRegion是HBase中分布式存储和负载均衡的最小单元。最小单元就表示不同的HRegion可以分布在不同的HRegionServer上。
HRegion由一个或多个store组成,每个store中保存一个columns family
每个Store又由一个memstore和多个0至多个storefile组成,storeFIle以HFIle格式保存在HDFS上。


四,HBase安装部署(分布式)
Hbase集群搭建建立在HDFS集群和zookeeper上,可查看本人博客搭建之前步骤
-
上传tar安装包并解压(不会的小伙伴可查看之前关于linux安装及命令的博客)
-
conf目录下,hbase-env.sh中配置JAVA_HOME,不使用HBase的默认zookeeper配置




-
conf目录下,修改hbase-site.xml


hdfs:// 后面是你hdfs集群的名称,不清楚的话,可以去hadoop安装目录下 hdfs-site.xml中查看
zookeeper 集群选择自己的节点名称
-
conf目录下 配置regionservers添加你的regionserver的主机名


-
conf目录下,新建 backup-masters 添加你配置的master备份的主机名


6. 拷贝Hadoop的下配置文件hdfs-site.xml到当前 conf目录下(hbase存储在hdfs上)
7. 复制hbase整个解压包文件,发送到其他两个节点上,配置环境变量(每台节点)
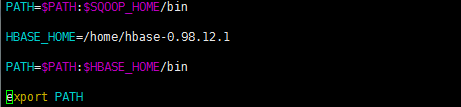

4.1 启动和测试
- 启动zookeeper集群(Hbase强依赖于zookeeper)
- 启动hadoop集群,保证集群状态正常
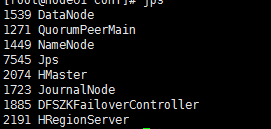
- 启动命令: start-hbase.sh
- jps查看进程

前往浏览器查看web访问页面:端口号—> 60010


到此,搭建完成!!
五,HBase shell 和 APi
5.1 shell 相关指令
进入到Hbase:
hbase shell ##确保自己的环境变量生效,不然只能跑到安装目录bin下启动
创建表
create '表名',‘列族名1’,‘列族名2’,....
添加记录
put '表名','Row Key','列族名:列名','值'
查看记录
get '表名', 'Row Key', '列族名:列名'
查看表中的记录总数
count '表名'
删除记录
delete '表名', 'Row Key', '列族名:列名'
删除一张表
disable '表名' ##先禁用该表
drop '表名' ##删除表
查看所有记录
scan '表名'
5.2 API
package com.shsxt.hbase;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.Cell;
import org.apache.hadoop.hbase.CellUtil;
import org.apache.hadoop.hbase.HColumnDescriptor;
import org.apache.hadoop.hbase.HTableDescriptor;
import org.apache.hadoop.hbase.MasterNotRunningException;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.ZooKeeperConnectionException;
import org.apache.hadoop.hbase.client.Get;
import org.apache.hadoop.hbase.client.HBaseAdmin;
import org.apache.hadoop.hbase.client.HTable;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.client.Result;
import org.apache.hadoop.hbase.client.ResultScanner;
import org.apache.hadoop.hbase.client.Scan;
import org.apache.hadoop.hbase.filter.CompareFilter.CompareOp;
import org.apache.hadoop.hbase.filter.FilterList;
import org.apache.hadoop.hbase.filter.PrefixFilter;
import org.apache.hadoop.hbase.filter.SingleColumnValueFilter;
import org.apache.hadoop.hbase.util.Bytes;
public class Demo {
static Configuration conf = null;
static HBaseAdmin hBaseAdmin = null;
static String TN = null;
public static void main(String[] args) throws Exception {
conf = new Configuration();
//这里配置zookeeper集群信息,可以配置一个节点,也可以配置所有节点(node01,node02,node03)
conf.set("hbase.zookeeper.quorum", "node01");
hBaseAdmin = new HBaseAdmin(conf);
//要创建的表的名称
TN = "wcb";
//createHTable();
//putData();
// getData();
scanData();
}
private static void scanData() throws Exception {
HTable hTable = new HTable(conf, TN);
Scan scan = new Scan();
//设置扫描的Row Key 开始和结束,左闭右开
//scan.setStopRow("p_001".getBytes());
//scan.setStopRow("p_003".getBytes());
//设置扫描的过滤器,MUST_PASS_ONE 表示任意满足一条过滤规则即可
FilterList list = new FilterList(FilterList.Operator.MUST_PASS_ONE);
//前缀过滤器
PrefixFilter prefixFilter = new PrefixFilter("p_".getBytes());
//具体列值 比较过滤器,默认是按照字典顺序排序
SingleColumnValueFilter singleColumnValueFilter = new SingleColumnValueFilter
("cf1".getBytes(), "age".getBytes(), CompareOp.GREATER, "1".getBytes());
list.addFilter(prefixFilter);
list.addFilter(singleColumnValueFilter);
scan.setFilter(list);
//获取到多行数据
ResultScanner scanner = hTable.getScanner(scan);
//遍历每一行数据
for (Result result : scanner) {
System.out.println(Bytes.toString(result.getRow()));
System.out.println("=================");
//遍历每一行中每个cell单元格
for(Cell cell : result.rawCells()){
System.out.println(Bytes.toString(CellUtil.cloneQualifier(cell)));
System.out.println(Bytes.toString(CellUtil.cloneValue(cell)));
System.out.println(Bytes.toString(CellUtil.cloneFamily(cell)));
System.out.println("==================================");
}
}
}
private static void getData() throws Exception {
HTable hTable = new HTable(conf, TN);
Get get = new Get("p_001".getBytes());
//get.addColumn("cf1".getBytes(), "name".getBytes());
//获取到该行记录的所有数据
Result result = hTable.get(get);
System.out.println(Bytes.toString(result.getRow()));
//遍历该行数据的所有 cell单元格
for (Cell cell : result.rawCells()) {
System.out.println(Bytes.toString(CellUtil.cloneQualifier(cell))+"\t"+
Bytes.toString(CellUtil.cloneValue(cell))+"\t"
+cell.getFamilyLength()+"\t"+
cell.getValueLength());
}
}
private static void putData() throws Exception {
//拿到表实例对象
HTable hTable = new HTable(conf, TN);
//Row Key 的设置
Put put = new Put("w_003".getBytes());
//新增每列
put.add("cf1".getBytes(), "name".getBytes(), "p3".getBytes());
put.add("cf1".getBytes(),"age".getBytes(),"20".getBytes());
put.add("cf1".getBytes(),"sex".getBytes(),"男".getBytes());
hTable.put(put);
System.out.println("添加成功........");
}
private static void createHTable() throws Exception {
//判断表是否存在,存在先执行删除操作
if (hBaseAdmin.tableExists(TN)) {
hBaseAdmin.disableTable(TN);
hBaseAdmin.deleteTable(TN);
}
TableName name = TableName.valueOf(TN);
HTableDescriptor desc = new HTableDescriptor(name);
//定义一个列族
HColumnDescriptor family = new HColumnDescriptor("cf1");
//开启缓存,提高读取的效率
family.setBlockCacheEnabled(true);
//设置表的最多版本数
family.setMaxVersions(1);
family.setInMemory(true);
desc.addFamily(family);
//创表方法
hBaseAdmin.createTable(desc);
System.out.println("创建完成.......");
}
}