1.0什么是HADOOP
1.HADOOP是apache旗下的一套开源软件平台
2.HADOOP提供的功能:利用服务器集群,根据用户的自定义业务逻辑,对海量数据进行分布式处理
3.HADOOP的核心组件有
A.HDFS(分布式文件系统)
B.YARN(运算资源调度系统)
C.MAPREDUCE(分布式运算编程框架)
4.广义上来说,HADOOP通常是指一个更广泛的概念——HADOOP生态圈
1.1 HADOOP产生背景
1.HADOOP最早起源于Nutch。Nutch的设计目标是构建一个大型的全网搜索引擎,包括网页抓取、索引、查询等功能,但随着抓取网页数量的增加,遇到了严重的可扩展性问题——如何解决数十亿网页的存储和索引问题。
2.2003年、2004年谷歌发表的两篇论文为该问题提供了可行的解决方案。
——分布式文件系统(GFS),可用于处理海量网页的存储
——分布式计算框架MAPREDUCE,可用于处理海量网页的索引计算问题。
3.Nutch的开发人员完成了相应的开源实现HDFS和MAPREDUCE,并从Nutch中剥离成为独立项目HADOOP,到2008年1月,HADOOP成为Apache顶级项目,迎来了它的快速发展期。
1.2 HADOOP在大数据、云计算中的位置和关系
1.云计算是分布式计算、并行计算、网格计算、多核计算、网络存储、虚拟化、负载均衡等传统计算机技术和互联网技术融合发展的产物。借助IaaS(基础设施即服务)、PaaS(平台即服务)、SaaS(软件即服务)等业务模式,把强大的计算能力提供给终端用户。
2.现阶段,云计算的两大底层支撑技术为“虚拟化”和“大数据技术”
3.而HADOOP则是云计算的PaaS层的解决方案之一,并不等同于PaaS,更不等同于云计算本身。
1.3 HADOOP生态圈以及各组成部分的简介
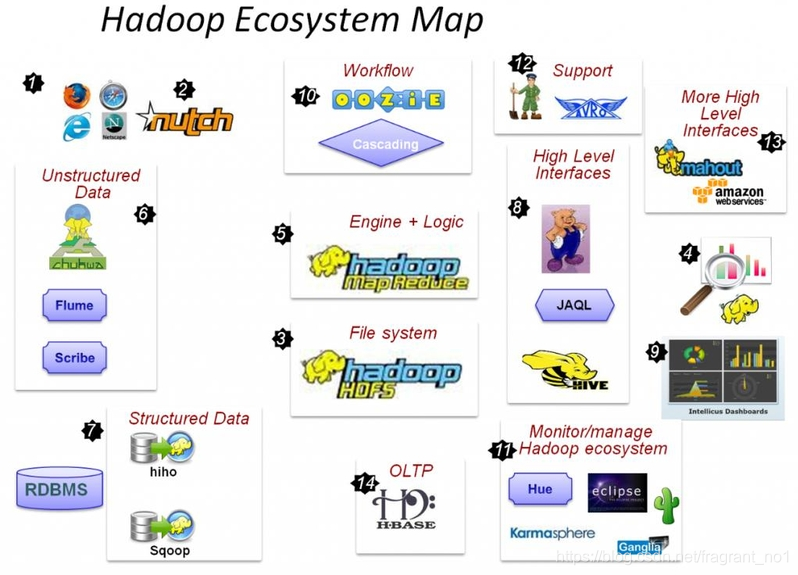
说明:
HADOOP(hdfs、MAPREDUCE、yarn) 元老级大数据处理技术框架,擅长离线数据分析。
重点组件:
HDFS:分布式文件系统
MAPREDUCE:分布式运算程序开发框架
HIVE:基于大数据技术(文件系统+运算框架)的SQL数据仓库工具
HBASE:基于HADOOP的分布式海量数据库
ZOOKEEPER:分布式协调服务基础组件
Mahout:基于mapreduce/spark/flink等分布式运算框架的机器学习算法库
Oozie:工作流调度框架
Sqoop:数据导入导出工具
Flume:日志数据采集框架
2.0 hadoop大致的一个工作流程图解析
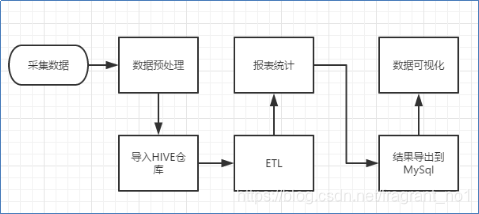
具体实例如:日志数据挖掘,大致流程就是参照上图

说明:
一般中型的网站(10W的PV以上),每天会产生1G以上Web日志文件。大型或超大型的网站,可能每小时就会产生10G的数据量。
具体来说,比如某电子商务网站,在线团购业务。每日PV数100w,独立IP数5w。用户通常在工作日上午10:00-12:00和下午15:00-18:00访问量最大。日间主要是通过PC端浏览器访问,休息日及夜间通过移动设备访问较多。网站搜索浏量占整个网站的80%,PC用户不足1%的用户会消费,移动用户有5%会消费。
对于日志的这种规模的数据,用HADOOP进行日志分析,是最适合不过的了。
2.1 HDFS
前言介绍:首先,它是一个文件系统,用于存储文件,通过统一的命名空间——目录树来定位文件
其次,它是分布式的,由很多服务器联合起来实现其功能,集群中的服务器有各自的角色;
重要特性如下:
(1)HDFS中的文件在物理上是分块存储(block),块的大小可以通过配置参数( dfs.blocksize)来规定,默认大小在hadoop2.x版本中是128M,老版本中是64M
(2)HDFS文件系统会给客户端提供一个统一的抽象目录树,客户端通过路径来访问文件,形如:hdfs://namenode:port/dir-a/dir-b/dir-c/file.data
(3)目录结构及文件分块信息(元数据)的管理由namenode节点承担
——namenode是HDFS集群主节点,负责维护整个hdfs文件系统的目录树,以及每一个路径(文件)所对应的block块信息(block的id,及所在的datanode服务器)
(4)文件的各个block的存储管理由datanode节点承担
---- datanode是HDFS集群从节点,每一个block都可以在多个datanode上存储多个副本(副本数量也可以通过参数设置dfs.replication)
(5)HDFS是设计成适应一次写入,多次读出的场景.
(6) 一般跟yarn绑定存在,比如datanode namemanager同在一台机器上.
概述:
1.HDFS集群分为两大角色:NameNode、DataNode
2.NameNode负责管理整个文件系统的元数据
3.DataNode 负责管理用户的文件数据块
4.文件会按照固定的大小(blocksize)切成若干块后分布式存储在若干台datanode上
5.每一个文件块可以有多个副本,并存放在不同的datanode上
6.Datanode会定期向Namenode汇报自身所保存的文件block信息,而namenode则会负责保持文件的副本数量
7.HDFS的内部工作机制对客户端保持透明,客户端请求访问HDFS都是通过向namenode申请来进行
2.2 HDFS常用命令参数介绍
-help
功能:输出这个命令参数手册
-ls
功能:显示目录信息
示例: hadoop fs -ls hdfs://hadoop-server01:9000/
备注:这些参数中,所有的hdfs路径都可以简写
–>hadoop fs -ls / 等同于上一条命令的效果
-mkdir
功能:在hdfs上创建目录
示例:hadoop fs -mkdir -p /aaa/bbb/cc/dd
-moveFromLocal
功能:从本地剪切粘贴到hdfs
示例:hadoop fs - moveFromLocal /home/hadoop/a.txt /aaa/bbb/cc/dd
-moveToLocal
功能:从hdfs剪切粘贴到本地
示例:hadoop fs - moveToLocal /aaa/bbb/cc/dd /home/hadoop/a.txt
–appendToFile
功能:追加一个文件到已经存在的文件末尾
示例:hadoop fs -appendToFile ./hello.txt hdfs://hadoop-server01:9000/hello.txt
可以简写为:
Hadoop fs -appendToFile ./hello.txt /hello.txt
-cat
功能:显示文件内容
示例:hadoop fs -cat /hello.txt
-tail
功能:显示一个文件的末尾
示例:hadoop fs -tail /weblog/access_log.1
-text
功能:以字符形式打印一个文件的内容
示例:hadoop fs -text /weblog/access_log.1
-chgrp
-chmod
-chown
功能:linux文件系统中的用法一样,对文件所属权限
示例:
hadoop fs -chmod 666 /hello.txt
hadoop fs -chown someuser:somegrp /hello.txt
-copyFromLocal
功能:从本地文件系统中拷贝文件到hdfs路径去
示例:hadoop fs -copyFromLocal ./jdk.tar.gz /aaa/
-copyToLocal
功能:从hdfs拷贝到本地
示例:hadoop fs -copyToLocal /aaa/jdk.tar.gz
-cp
功能:从hdfs的一个路径拷贝hdfs的另一个路径
示例: hadoop fs -cp /aaa/jdk.tar.gz /bbb/jdk.tar.gz.2
-mv
功能:在hdfs目录中移动文件
示例: hadoop fs -mv /aaa/jdk.tar.gz /
-get
功能:等同于copyToLocal,就是从hdfs下载文件到本地
示例:hadoop fs -get /aaa/jdk.tar.gz
-getmerge
功能:合并下载多个文件
示例:比如hdfs的目录 /aaa/下有多个文件:log.1, log.2,log.3,…
hadoop fs -getmerge /aaa/log.* ./log.sum
-put
功能:等同于copyFromLocal
示例:hadoop fs -put /aaa/jdk.tar.gz /bbb/jdk.tar.gz.2
-rm
功能:删除文件或文件夹
示例:hadoop fs -rm -r /aaa/bbb/
-rmdir
功能:删除空目录
示例:hadoop fs -rmdir /aaa/bbb/ccc
-df
功能:统计文件系统的可用空间信息
示例:hadoop fs -df -h /
-du
功能:统计文件夹的大小信息
示例:
hadoop fs -du -s -h /aaa/*
-count
功能:统计一个指定目录下的文件节点数量
示例:hadoop fs -count /aaa/
-setrep
功能:设置hdfs中文件的副本数量
示例:hadoop fs -setrep 3 /aaa/jdk.tar.gz
<这里设置的副本数只是记录在namenode的元数据中,是否真的会有这么多副本,还得看datanode的数量>
说明: /data /data/ 这样写表示的是一样的,操作的都是目录对象, /data/. 这样写就不包括目录本身,只会操作目录里面的内容。
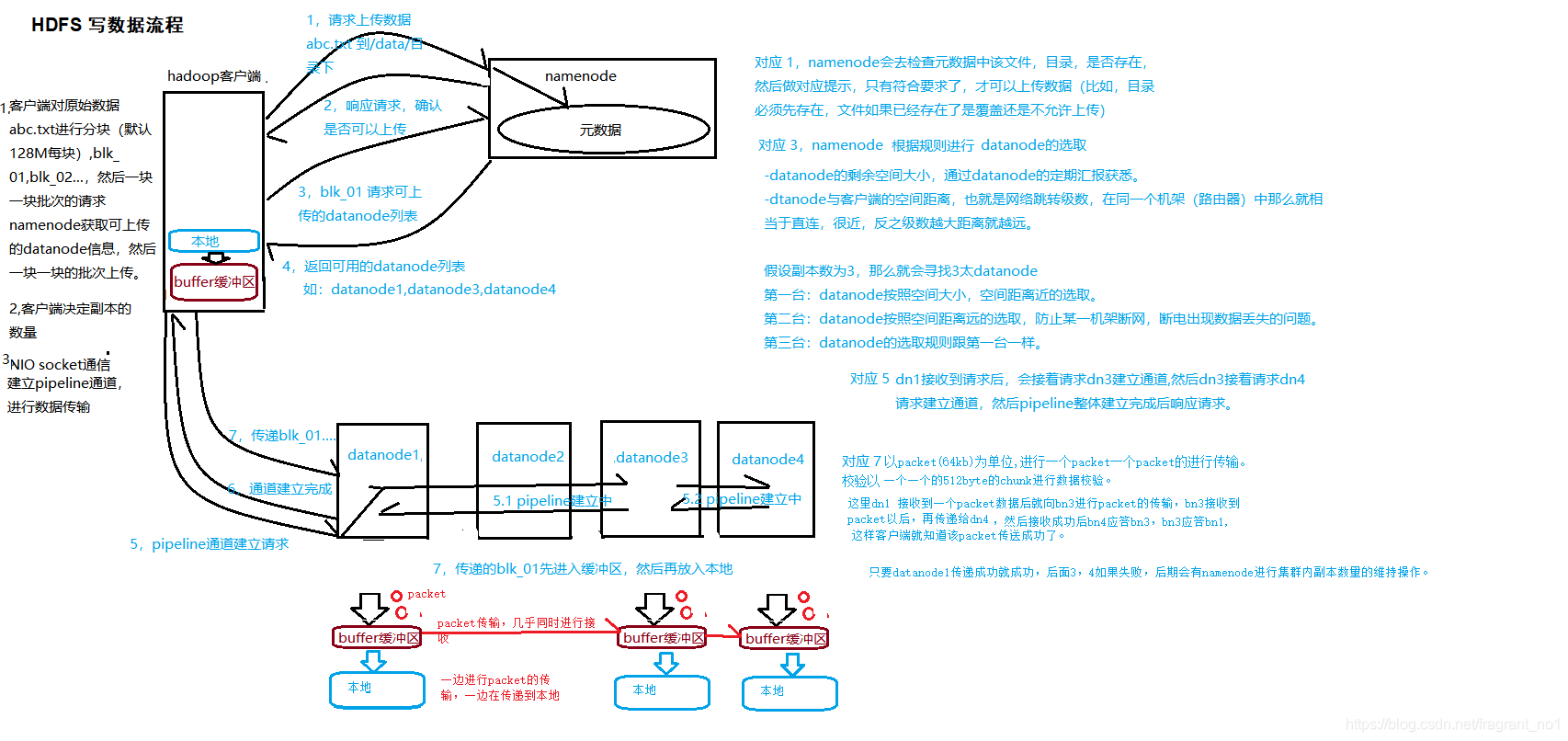
2.3 HDFS写数据流程
概述
客户端要向HDFS写数据,首先要跟namenode通信以确认可以写文件并获得接收文件block的datanode,然后,客户端按顺序将文件逐个block传递给相应datanode,并由接收到block的datanode负责向其他datanode复制block的副本
2.4 HDFS读数据流程
概述
客户端将要读取的文件路径发送给namenode,namenode获取文件的元信息(主要是block的存放位置信息)返回给客户端,客户端根据返回的信息找到相应datanode逐个获取文件的block并在客户端本地进行数据追加合并从而获得整个文件.

2.5 NAMENODE
NAMENODE职责:
负责客户端请求的响应
元数据的管理(查询,修改)
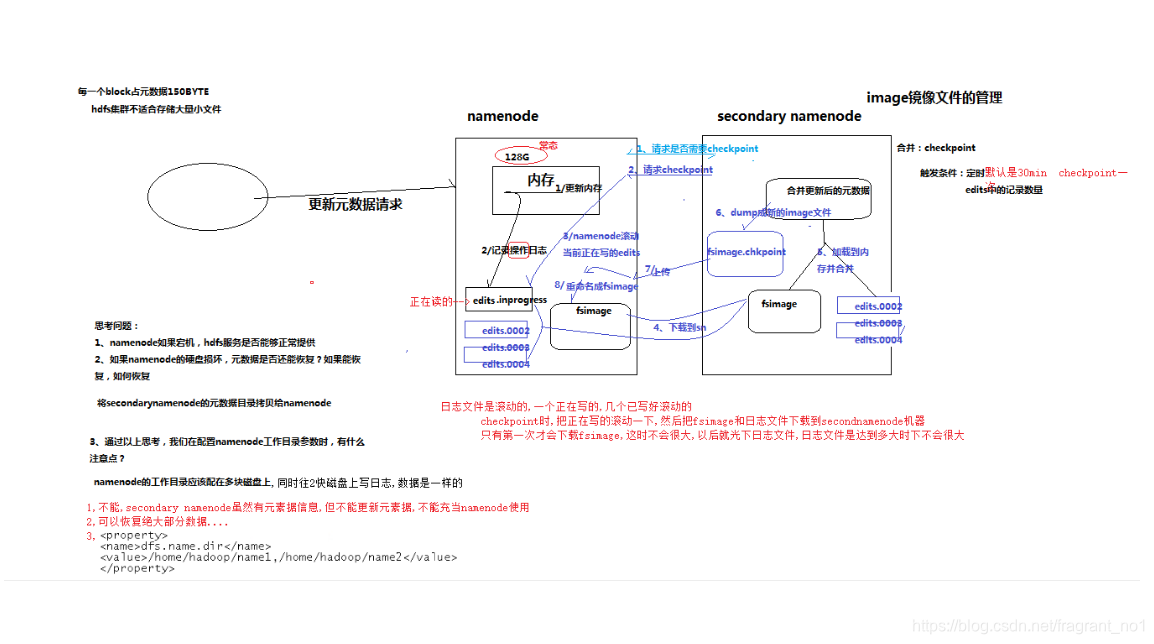
元数据管理
namenode对数据的管理采用了三种存储形式:
内存元数据(NameSystem)
磁盘元数据镜像文件
数据操作日志文件(可通过日志运算出元数据)
元数据存储机制
A、内存中有一份完整的元数据(内存meta data)
B、磁盘有一个“准完整”的元数据镜像(fsimage)文件(在namenode的工作目录中)
C、用于衔接内存metadata和持久化元数据镜像fsimage之间的操作日志(edits文件)
元数据手动查看
可以通过hdfs的一个工具来查看edits中的信息
bin/hdfs oev -i edits -o edits.xml
bin/hdfs oiv -i fsimage_0000000000000000087 -p XML -o fsimage.xml
元数据的checkpoint
每隔一段时间,会由secondary namenode将namenode上积累的所有edits和一个最新的fsimage下载到本地,并加载到内存进行merge(这个过程称为checkpoint)
checkpoint操作的触发条件配置参数
dfs.namenode.checkpoint.check.period=60 #检查触发条件是否满足的频率,60秒
dfs.namenode.checkpoint.dir=file://${hadoop.tmp.dir}/dfs/namesecondary
#以上两个参数做checkpoint操作时,secondary namenode的本地工作目录
dfs.namenode.checkpoint.edits.dir=${dfs.namenode.checkpoint.dir}
dfs.namenode.checkpoint.max-retries=3 #最大重试次数
dfs.namenode.checkpoint.period=3600 #两次checkpoint之间的时间间隔3600秒
dfs.namenode.checkpoint.txns=1000000 #两次checkpoint之间最大的操作记录
checkpoint的附带作用
namenode和secondary namenode的工作目录存储结构完全相同,所以,当namenode故障退出需要重新恢复时,可以从secondary namenode的工作目录中将fsimage拷贝到namenode的工作目录,以恢复namenode的元数据.
说明:
1,hdfs允许更新元数据(文件名,路径,数据追加等)操作,但是不支持修改已经写入的数据内容,比如abc.txt里面已经写入了hello world! 然后想要修改为hello china! 是不允许的。
2,数据操作成功了,才会记录到元数据中,失败了就重试。
2.6 DATANODE
Datanode工作职责:
存储管理用户的文件块数据
定期向namenode汇报自身所持有的block信息(通过心跳信息上报)
(这点很重要,因为,当集群中发生某些block副本失效时,集群如何恢复block初始副本数量的问题)
配置信息:
<property>
<name>dfs.blockreport.intervalMsec</name>
<value>3600000</value>
<description>Determines block reporting interval in milliseconds.</description>
</property>
Datanode掉线判断时限参数
datanode进程死亡或者网络故障造成datanode无法与namenode通信,namenode不会立即把该节点判定为死亡,要经过一段时间,这段时间暂称作超时时长。HDFS默认的超时时长为10分钟+30秒。如果定义超时时间为timeout,则超时时长的计算公式为:
timeout = 2 * heartbeat.recheck.interval + 10 * dfs.heartbeat.interval。
而默认的heartbeat.recheck.interval 大小为5分钟,dfs.heartbeat.interval默认为3秒。
需要注意的是hdfs-site.xml 配置文件中的heartbeat.recheck.interval的单位为毫秒,dfs.heartbeat.interval的单位为秒。所以,举个例子,如果heartbeat.recheck.interval设置为5000(毫秒),dfs.heartbeat.interval设置为3(秒,默认),则总的超时时间为40秒。
<property>
<name>heartbeat.recheck.interval</name>
<value>2000</value>
</property>
<property>
<name>dfs.heartbeat.interval</name>
<value>1</value>
</property>