Mapreduce在YARN上的过程概述
首先我们对整个mpred的过程有个初步的理解。
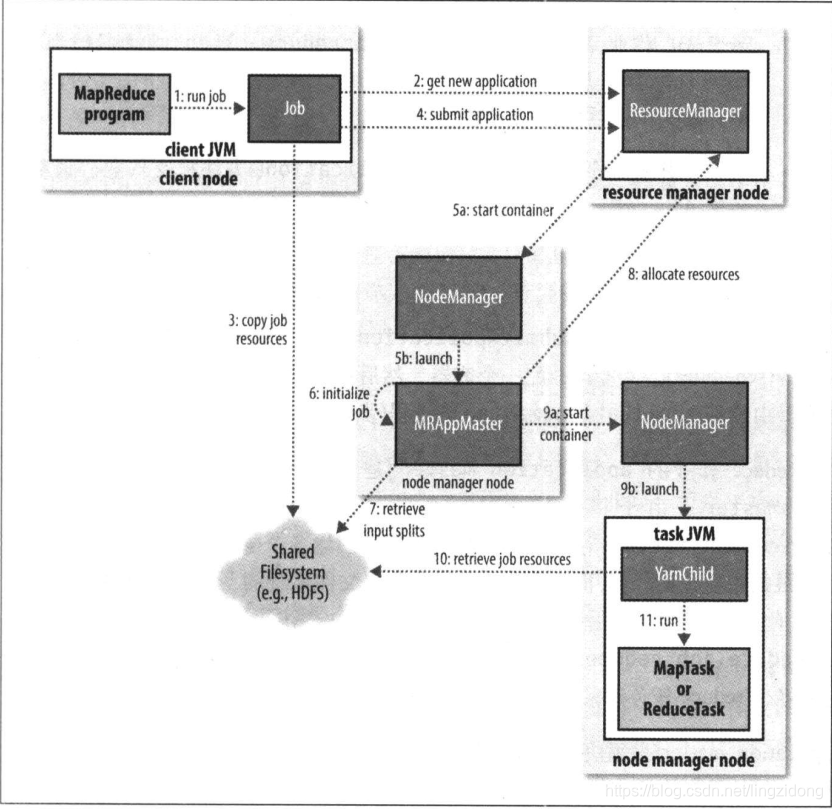
首先,我们在客户节点上提交mapred程序,也就是向资源管理器提交作业。
其次,资源管理器对任务进行初始化和分配。
分配任务之后,任务开始在特定节点上的制定容器执行,并向MRapplicationManager更新进度。
最后,application master收到作业完成的或者是薄的通知,并通知客户端。清理容器和工作状态之后,整个作业完成。
其中提到的一些概念,比如application master,我们会在下面提及。
Hadoop提供一个Job类管理和配置各个过程。
我们按照上面的过程划分,分开来谈。
part0 顶层应用
在整个过程中,有 5 个主要的独立实体
- 客户端:提交mapred作业
- YARN 资源管理器
- YARN 节点管理器
- MapReduce的 application master ,这个实体负责协调各个任务的运行,他在由节点管理器管理的节点中运行。
- 分布式文件系统,也就是HDFS,负责共享文件
part1 初始化阶段
1.提交作业:
我们通过 Job 对象向资源管理器提交申请,提交过程如下
- 向资源管理器申请新的 ID,也就是图上的步骤2
- 检查作业的输出说明,如果没有指定或者该目录已经存在就返回错误。
- 检查输入分片
- 将所需资源( JAR 文件,配置文件,计算过程中的输入分片)复制到以改任务ID的共享文件系统中,也就是 HDFS。
- 将作业提交,也就是步骤4
检查输出的时候为什么存在输出目录也要返回错误呢?由于 Hadoop 设计时,为了防止已经产生的结果覆盖,就添加了这个约束。
步骤1234总结一下就是申请 ID,检查路径,复制资源,提交作业。
2.作业初始化
首先资源管理器要启动 application master 。资源管理器将请求发送至YARN 中的调度器(scheduler)。由调度器分配 master 的运行容器(5a),再由节点管理器启动 application master (5b)
master 开始对任务初始化并保持对任务的追踪(6),接下来接受之前客户端传送到文件共享系统的输入分片等资源(7)。然后开始分配任务。
任务的分配:对于每个分片,都要分配一个 map 任务。同时根据 mapred 的设置确定对应数量的 reduce 任务,任务ID在这个时候确定。此时如果有的任务需要新分配节点,就向资源管理器请求容器(8),首先为 map 任务申请,之后是 reduce 任务。当有5%的任务完成时,才会为 reduce 任务申请。这是因为所有的 map 任务必须在 reduce 的排序过程之前运行完成。
part2 运行阶段
1.执行任务
当任务分配完成之后,application master 就通过与节点管理器通信,启动各个容器并执行任务(9a,9b)。每个对应的容器运行任务之前,首先要把资源本地化(共享文件系统上的资源和配置)(10)。最后开始执行任务(11)
2.进度和状态更新
状态更新也是比较复杂的部分。对于每个作业以及任务来说都有一个状态,包括:作业或者任务运行状态(Running,Finished,Failed),map 和 reduce 的进度,计数器的值,状态消息(这部分可以由用户自定义)。
对进度的追踪是对已经完成的任务百分比追踪的。会对三个部分(map,shuffle,reduce)分别计算。
part3 完成阶段
当 application master 收到最后一个任务完成的通知后,会把作业状态设置成完成,这样在客户端询问的 Job 对象就知道是否成功了。
还有一些细节,以后再更新(咕咕咕