原文地址: https://itweknow.cn/detail?id=52 ,欢迎大家访问。
前置条件
- Java7以上的Java环境,可以查看之前的博文安装,Ubuntu安装JDK1.8。
- ssh,这个ubuntu自带就有,无需单独安装。
- hadoop包,可以到官网下载。
安装Hadoop
-
前置说明
文中的hadoop压缩包存放位置为~/apps/hadoop/hadoop-2.8.5.tar.gz,解压后的hadoop地址为~/apps/hadoop/hadoop-2.8.5。 -
解压hadoop压缩包
root@test:~/apps/hadoop# tar -xzvf hadoop-2.8.5.tar.gz -
配置
hadoop-env.sh,其路径为~/apps/hadoop/hadoop-2.8.5/etc/hadoop/httpfs-env.sh。只需要做一个小小的修改,就是将${JAVA_HOME}修改为我们JDK的目录即可。export JAVA_HOME=/usr/local/Java/jdk1.8.0_181 -
配置
core-size.xml,其路径为~/apps/hadoop/hadoop-2.8.5/etc/hadoop/core-size.xml。主要是添加了两个配置项fs.defaultFS和hadoop.tmp.dir<configuration> <!-- 指定HADOOP所使用的文件系统schema(URI),HDFS的老大(NameNode)的地址 --> <property> <name>fs.defaultFS</name> <value>hdfs://localhost:9000</value> </property> <!-- 指定hadoop运行时产生文件的存储目录 --> <property> <name>hadoop.tmp.dir</name> <value>/root/hadoop/tmp</value> </property> </configuration> -
配置
hdfs-site.xml,这里主要配置了HDFS副本的数量,也就是一个文件存在HDFS中的份数。<configuration> <!-- 指定HDFS副本的数量 --> <property> <name>dfs.replication</name> <value>1</value> </property> </configuration> -
配置
mapred-site.xml,配置这个的时候会比上面多上那么一步,因为hadoop中这个配置文件的模板名称为mapred-site.xml.template,我们需要改个名字。cp mapred-site.xml.template mapred-site.xml配置文件的内容为:
<configuration> <!-- 指定MapReduce程序运行在yarn上 --> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration> -
配置
yarn-site.xml<configuration> <!-- 指定ResourceManager(YARN的老大)的地址,主机名 --> <property> <name>yarn.resourcemanager.hostname</name> <value>test</value> </property> <!-- reducer获取数据的方式 --> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> </configuration> -
将hadoop添加到环境变量中
export HADOOP_HOME=/root/apps/hadoop/hadoop-2.8.5 export PATH=export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin -
使环境变量生效
root@test:~/apps/hadoop/hadoop-2.8.5# source /etc/profile
测试
- 查看hadoop版本
你应该可以看到如下结果root@test:~/apps/hadoop/hadoop-2.8.5# hadoop versionHadoop 2.8.5 Subversion https://git-wip-us.apache.org/repos/asf/hadoop.git -r 0b8464d75227fcee2c6e7f2410377b3d53d3d5f8 Compiled by jdu on 2018-09-10T03:32Z Compiled with protoc 2.5.0 From source with checksum 9942ca5c745417c14e318835f420733 This command was run using /root/apps/hadoop/hadoop-2.8.5/share/hadoop/common/hadoop-common-2.8.5.jar - 启动hdfs,首先切到
/root/apps/hadoop/hadoop-2.8.5/sbin目录下,该目录下有很多hadoop的启动脚本,比如start-all.sh是启动所有服务的,start-dfs.sh是单独启动hdfs的。
(1) 格式化namenode
(2) 启动hadoop的全部服务hdfs namenode -format
(3) jps命令查看启动结果./start-all.sh
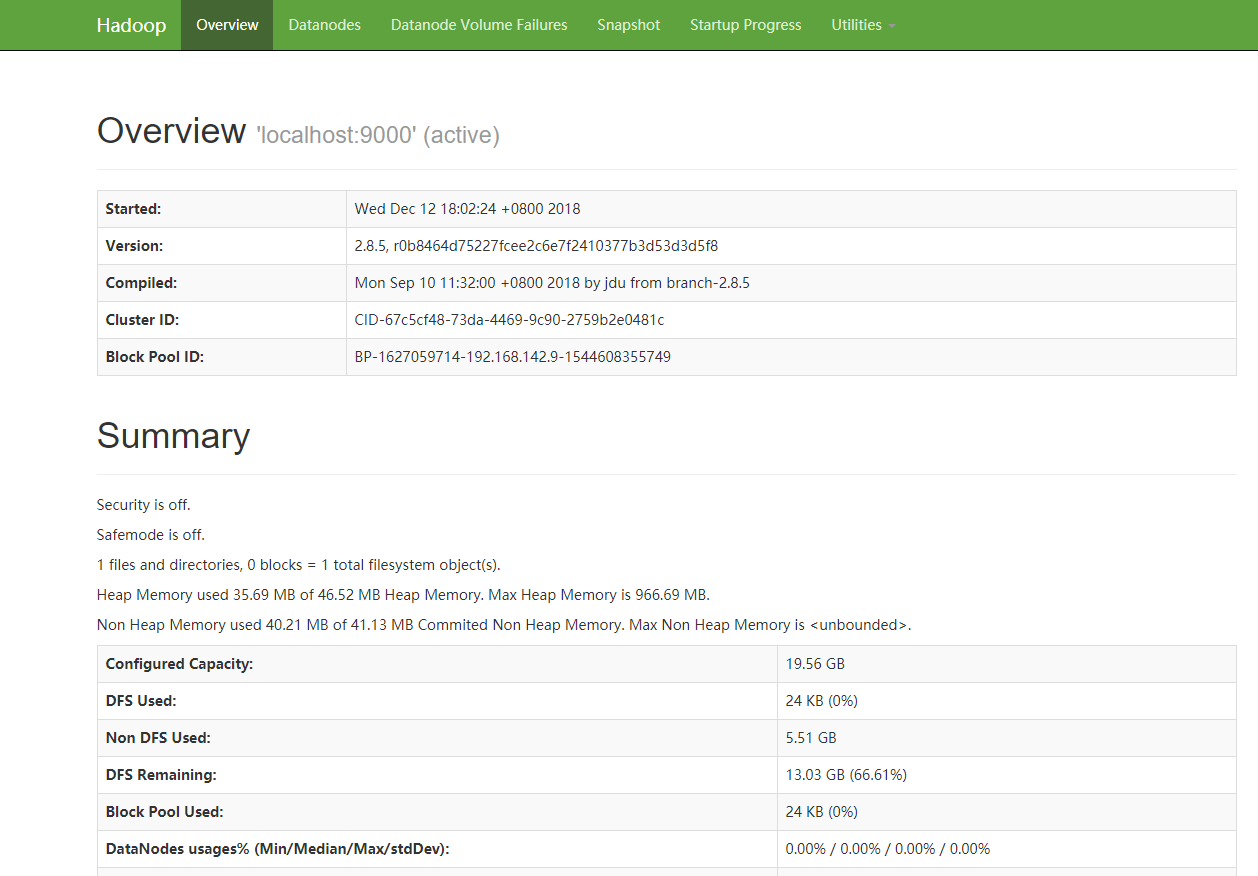
(4) 浏览器查看hdfs的网页端,访问地址root@test:~/apps/hadoop/hadoop-2.8.5/etc/hadoop# jps 15920 Jps 15283 SecondaryNameNode 15430 ResourceManager 15063 DataNode 15599 NodeManager 14879 NameNodehttp://{虚拟机IP}:50070