还是因为迁移到Deepin上开发的缘故,原来在win10上搭建的hadoop集群用不上了,所以这次重新搭一下。我之前写过一篇hadoop伪分布式搭建的文章,完全分布式集群的搭建和这差不多,不同点在于如何构建集群,以及配置文件上有些许不同。另外,我前几天写了Deepin下java、大数据开发环境配置【一】是这次博客的前提,讲了如何在Deepin Linux下安装java、VMware以及VMware上安装Centos等等
准备
下载:Hadoop CDH发行版本(http://archive-primary.cloudera.com/cdh5/cdh/5/ ),为了后续和Hive、HBase、flume等版本对应,这里限定使用cdh5.12.1结尾的hadoop-2.6.0-cdh5.12.1.tar.gz(也是我之前下好的)
集群节点
三台虚拟机,分别为Master(192.168.17.10)、Slave1(192.168.17.10)、Slave2(192.168.17.10)
修改VMware的网络配置
这一步主要是为了给虚拟机分配一个固定IP地址,便于集群间通讯
启动器或者打开VMWare找到VMware Network Editor,IP地址限定在192.168.17.1网段,网关是192.168.17.2,掩码255.255.255.0,如下图配置

配置虚拟机网络环境
启动之前安装好的Centos7,不知道怎么安装我文章开头提到了
- 设置静态IP
同样是在/etc下(这是配置文件所在地)
ls sysconfig/network-scripts/ifcfg-ens*
# 输出结果就是要配置的文件
vi sysconfig/network-scripts/ifcfg-en*
# 进入编辑
改动以下设置
BOOTPROTO=static //改成static
ONBOOT=yes //改成yes
IPADDR=192.168.17.10 //随便设,不过要在子网192.168.17.0下
NETMASK=255.255.255.0 //掩码
GATEWAY=192.168.17.2 //第一步配置时设好的
DNS1=192.168.17.2 //随便写
- 设置主机名
命令行下输入hostname可查看主机名,一般是localhost,但为了方便重新设置主机名
vi /etc/hostname
删掉原先的,配置主机名为master
- 绑定IP地址和主机名
vi /etc/hosts
# 追加如下内容
127.168.17.10 master //就是你配置的固定IP和主机名
- 关闭防火墙
我这里是centos,防火墙是firewall,而不是iptables【其他系统有其他关闭方法】。防火墙务必要关闭,否则完全分布式搭建的话无法和其他主机相连
systemctl stop firewalld //停止firewall服务
systemctl disable firewalld //禁止firewall开机启动
然后可以通过systemctl status firewalld查看防火墙状态
Active: inactive (dead) //这就是关闭了
- 重启网络服务
systemctl restart network,然后你可以ping以下主机名ping master,看可以ping通吗,可以的话就OK
配置Hadoop的环境
本地上传文件到centos服务器
我这里是下的hadoop-2.6.0-cdh5.12.1,一样是上传放在了/home/hadoop用户目录下。关于上传的问题,Windows下可以借助WinSCP软件,因为我是Deepin Linux系统可以直接使用scp命令,也可以借助rz、sz命令(这个需要在centos下安装lrzsz工具)
scp hadoop-2.6.0-cdh5.12.1.tar.gz [email protected]:/home/hadoop
Deepin命令行下自带了一个快速连接Linux服务器的工具(Ctrl+/打开),类似下图。然后可以直接鼠标右键选择上传或是下载文件,其本质是sz(上传)、rz(下载)命令使用

解压安装
tar -zxvf hadoop-2.6.0-cdh5.12.1.tar.gz -C /home/hadoop //把hadoop-2.6.0-cdh5.12.1解压到/home/hadoop目录下
cd /home/hadoop/hadoop-2.6.0-cdh5.12.1 //切换到该目录下
hdfs在运行时需要name,data,logs,tmp文件夹用来存放原数据,实际数据,日志,临时文件
mkdir -p hdfs hdfs/name hdfs/data logs tmp //在hadoop目录中创建
配置Hadoop环境变量
vi /home/hadoop/.bash_profile
# 修改添加下列内容
export HADOOP_HOME=/home/hadoop/hadoop-2.6.0-cdh5.12.1 //hadoop主目录
export HADOOP_LOG_DIR=$HADOOP_HOME/logs //hadoop日志目录
export YARN_LOG_DIR=$HADOOP_LOG_DIR //YARN日志目录
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH //添加hadoop命令路径
中文去掉
修改hadoop配置文件
我在文末会放一个链接,你可以直接下载,修改其中的主机名上传到/home/hadoop/hadoop-2.6.0-cdh5.12.1/etc/hadoop目录下,覆盖原文件即可
cd /home/hadoop/hadoop-2.6.0-cdh5.12.1/etc/hadoop
所以需要配置的如图中命令所示:

基本配置如伪分布式配置一样,见 修改hadoop配置文件,不同点见下文
- slave文件不同

- hdfs-site.xml中设置data备份数为2
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/hadoop/hadoop-2.6.0-cdh5.12.1/hdfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/home/hadoop/hadoop-2.6.0-cdh5.12.1/hdfs/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value> //这里指备份两份
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
</configuration>
- yarn-site.xml不同
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:8031</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>master:8032</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>master:8033</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master:8034</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master:8088</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.log.server.url</name>
<value>http://master:19888/jobhistory/logs/</value>
</property>
复制生成另外两台虚拟机
配置好后关闭虚拟机,进入文件系统将该虚拟机复制两份(当然虚拟机放在哪是你安装是定义的)。上面配置的虚拟机是Master-centos7,复制两份Slave1-centos7、Slave2-centos7
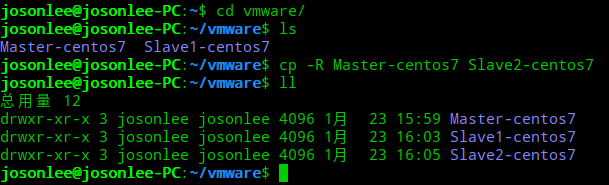
然后在虚拟机中导入并重命名

启动虚拟机,分别修改slave1、slave2的IP地址和主机名,并重启服务(参见前文)
修改之后,重启三台虚拟机。我建议你用命令行工具来链接虚拟机,因为我是Deepin上借助vm实现centos最小化安装,不知道怎么搞定vm tools一直安装不成功。搞的虚拟机中命令界面很难看、别扭。我这里借助Deepin的命令行自带的连接服务器功能,如图
设置集群间ssh免密登录
这一步很关键,保证hadoop的某些服务可以运行在三台机子上
- 分别在三台虚拟机上设置秘钥,
ssh-keygen -t rsa,然后三下回车,如图
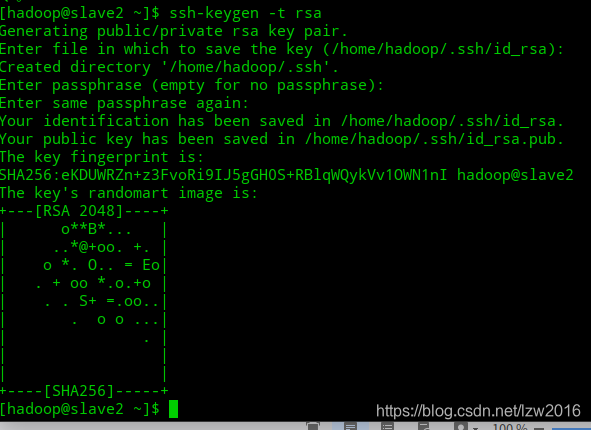
默认在 /home/hadoop/.ssh 目录(用户目录下的.ssh)下生成公钥id_rsa.pub和私钥文件id_rsa
- 将slave1、slave2节点的公钥汇总到mster的
.ssh/authorized_keys文件中
ssh-copy-id -i ~/.ssh/id_rsa.pub master
然后如图操作
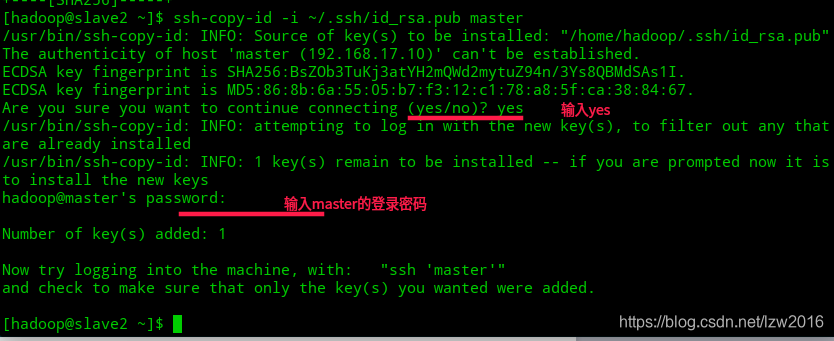
- 把master的公钥也汇总到authorized_keys文件
# master节点上执行
cd .ssh/
cat id_rsa.pub >> authorized_keys
chmod 600 cat authorized_keys //有必要赋予访问权限
- 把汇总后的authorized_keys文件分别发送到slave1、slave2的.ssh目录下
# master节点上执行
scp authorized_keys slave1:.ssh //执行两次
scp authorized_keys slave2:.ssh
如图,输入yes后,分别输入slave1、slave2的登录密码

- 测试ssh免密登录
ssh 主机名 //第一次连接时如有提示,输入yes,以后则没有提示也不需要密码即可连接
如图是slave2免密登录master、slave1,不成功的话删掉.ssh下面的文件重复上面步骤
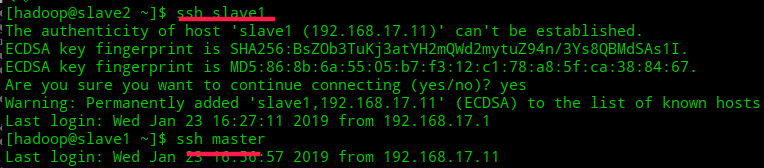
启动hadoop
以下操作全在master上进行
格式化hdfs文件系统
hdfs namenode -format
启动hdfs和yarn
start-dfs.sh //启动hdfs
start-yarn.sh //启动yarn
jps //查看启动进程
浏览器查看hdfs:http://192.168.17.10:50070,yarn:http://192.168.17.10:8088
注意:master下只能看到NameNode、SecondaryNameNode(未配置但依然会启动,配置的话还需要一台虚拟机)、ResourceManager;slave下有Datanode、NodeManager
# master上执行
[hadoop@master hadoop-2.6.0-cdh5.12.1]$ jps
3809 ResourceManager
3491 NameNode
3668 SecondaryNameNode
4072 Jps
# slave上
[hadoop@slave2 ~]$ jps
2102 NodeManager
2232 Jps
1998 DataNode
以上表明hadoop完全分布式集群搭建成功了
hadoop搭建也没什么难的,多试几次就熟悉了。配置文件放这里了: https://pan.baidu.com/s/1FA5FticQ6CVVM45cNn3JaA 提取码: ixfq 。我还上传了一份到csdn,如果你想让我赚几个积分也可以到这里下载:https://download.csdn.net/download/lzw2016/10935055
其次,推荐下我整理的一个项目吧,这一系列文章也可以在这里找到
学习记录的一些笔记,以及所看得一些电子书eBooks、视频资源和平常收纳的一些自己认为比较好的博客、网站、工具,https://github.com/josonle/Coding-Now