版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/liweijie231/article/details/81939730
数据格式
假设hive上存储的数据有一列类型是string,内容为如下
[
{
"code": "000001",
"market": "1",
"label": "1",
"addtime": "2015"
},
{
"code": "0000002",
"market": "1",
"label": "1",
"addtime": "2016"
}
...
]
行列转换
-
hive
相关说明
因为原数据是string(并不是真正的数组类型)类型的,所以无法直接使用explode函数 1. regexp_extract('xxx','^\[(.+)\]$',1) 这里是把需要解析的json数组去除左右中括号,需要注意的是这里的中括号需要两个转义字符\[。 2. regexp_replace('xxx','\}\,\{', '\}\|\|\{') 把json数组的逗号分隔符变成两根竖线||,可以自定义分隔符只要不在json数组项出现就可以。 3. 使用split函数返回的数组,分隔符为上面定义好的。 4. lateral view explode处理3中返回的数组。 -
presto

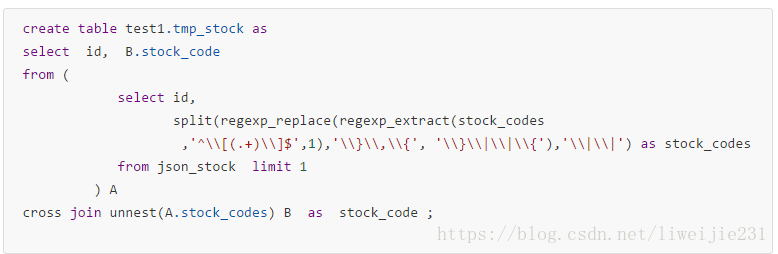
json解析
-
hive
select json_tuple(a.stock, 'code','market', 'label','addtime') from test1.tmp_stock a limit 1; select sid, b.code ,b.market,b.label,b.addtime from test1.stock2 a lateral view json_tuple(a.stock_codes, 'code','market', 'label','addtime') b as code, market, label,addtime ; -
presto
select json_extract_scalar(a.stock, '$.code') from test1.tmp_stock a limit 1