前言
继上篇博客对RDD介绍了简单的操作示例,本篇博客对RDD的操作进一步了解。
1. 常见的转换操作
1)map() – 计算RDD中各值的平方

squreRDD.collect()为返回RDD中所有数据。
注:返回的数据大小应保证该机器的内存足以存放,所以一般情况下collect仅在测试时使用。
2)flatMap() – 分词

3)map()和flatMap()的区别

上图为使用map()进行分词,可以对比2)中的flatMap()的分词。
对此作出一些总结(个人以及结合书籍,如有错误欢迎指出):
- map()为单输入单输出(分词中返回单个列表);
- flatMap()为单输入多输出(分词中返回解析的所有结果,实际上返回的是值序列的迭代器,该RDD的输出并不是由迭代器组成,而是由迭代器的内容组成,所以输出看到的是一个个元素)。
4)distinct() – 去重

5)sample() – 随机取样

第一个参数False,表示是否替换(是否允许重复取样)。
第二个参数0.5,表示取样的个数为总数的多少。(经实验,取样个数不是恒等于0.5,而是在这个值上下浮动)。
6)伪集合操作
定义两个集合以及其对应RDD:
In [116]: list1 = ["Spark", "Python", "Java", "Hadoop"]
In [117]: list2 = ["MapReduce", "Spark", "Python", "HDFS"]
In [118]: dataRDD1 = sc.parallelize(list1)
In [119]: dataRDD2 = sc.parallelize(list2)
-
union()

返回两个RDD中的所有元素(不去重)。 -
intersection()

返回两个RDD的相同元素。 -
subtract()

移除dataRDD1中与dataRDD2中相同的元素,并返回。 -
cartesian()

返回两个集合的笛卡尔积,即两个RDD中元素的所有组合。
2. 常见的行动操作
1)reduce() – 求和
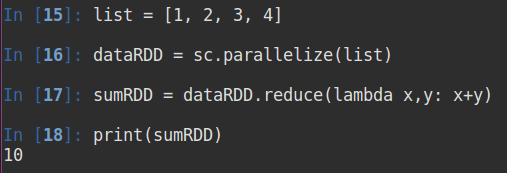
还有其他很多操作,这里仅以求和为例。
2)aggregate() – 求和+计数

aggregate()共有三个参数,(0,0)代表初始值,第二个参数代表求和和计数,第三个参数:由于在集群中是各个节点在其本地进行计算,所以需要对累加器两两合并(虽然我们这里不是集群,但是书籍上是这样讲解的)。
3)countByValue() – 各元素出现的次数

4)top(n) – 返回最前面的n个元素

从结果看,RDD中的元素应该是有序的(个人猜测)。
还有很多,这里就不再列举了。。。
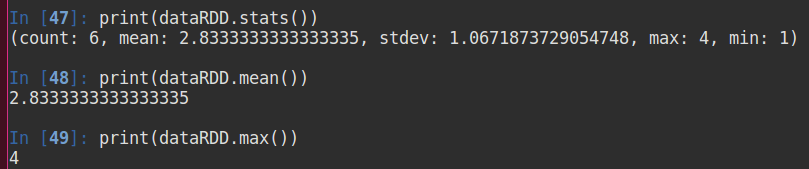
3. 持久化
上篇博客讲解了RDD的持久化,分别为persist()、cache()。当时说的是持久化到内存中,不过,现实情况下很可能出现内存不足的情况。所以,Spark还支持持久化到磁盘。
下表为持久化参数的信息(来自《Spark快速大数据分析》)

pyspark中不需要导入,直接使用,如:

因为内存有限,如果全部把RDD持久化到内存势必会造成内存不足。当然,Spark会自动利用最近最少使用(LRU)机制来把最老的分区从缓存中移除。
但是,如果再次用到被移除的RDD的计算结果,则又将重新计算一次,所花费的时间、资源很大。所以,可以选择将RDD持久化到磁盘中,尽管当从磁盘读取RDD时耗费时间长,但却比重新计算更具优势。