哥伦比亚大学 NLP 第三章(第一部分)
其他
2019-02-10 12:00:50
阅读次数: 0
哥伦比亚大学 NLP 第三章(第一部分)
目录
- 摘要
- 简介
- 上下文无关文语
(Context−Free
Grammars)
- 英语句法
- 歧义
(Ambiguity)
摘要
- 本章主要讲述了一个叫做
Parsing的问题,
Parsing的中文翻译叫做解析,是自然语言处理中非常重要的一个问题之一。
简介
什么是解析
Parsing
-
Parsing的目的就是为了分析句法结构,就是确定一个句子中每一个单词充当什么成分,比如:主语、谓语或宾语。句子间词组的结构关系,比如:动宾搭配等等。如下图所示:
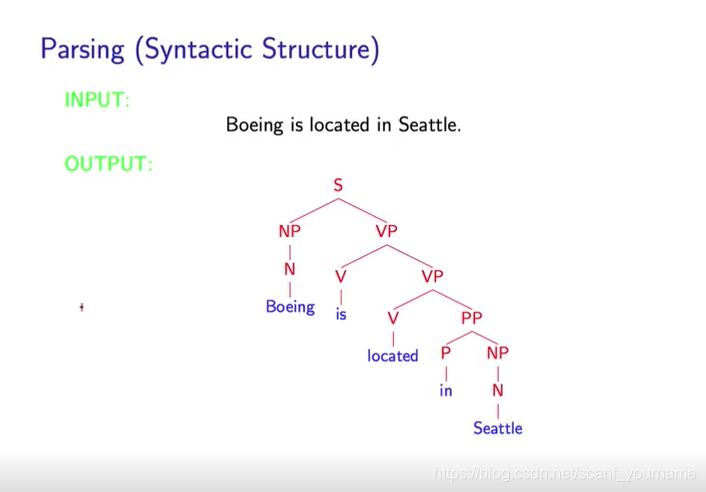
- 如上图所示
Parse的输入是一个句子,输出是一个解析树,这棵解析树不同的层次传递出来不同的信息,在紧挨着单词这一层传递的是词性的信息(
N=noun
V=verb
DT=determiner)。在往上面的一些层次中,体现出词组的一些信息,如上面所示的(
NP=None
Phase,
VP=Verb
Phase,
S=Sentences)。凭借这种解析方式,我们就可以很好的划分清楚句子成分并且便于句子的语意理解。
- 经过划分的句法结构之所以便于语意理解,是因为在语言中的一些结构决定着不同词之间的关系,这是每种语言固有的。比如:作为一个人,要去理解句意,或许你也需要像在脑海里构造解析树那样分析这是主语、这部分是谓语、这部分是宾语。根据语言约定俗成的规则,我们知道动作的发出者是主语,接收者是宾语,发生的那个行为就是谓语动词。既然我们上面的解析树已经分析清楚了句子成分,那么我们也可以让他学习一些固定的结构形式从而使机器理解句子的语意,如下图所示:
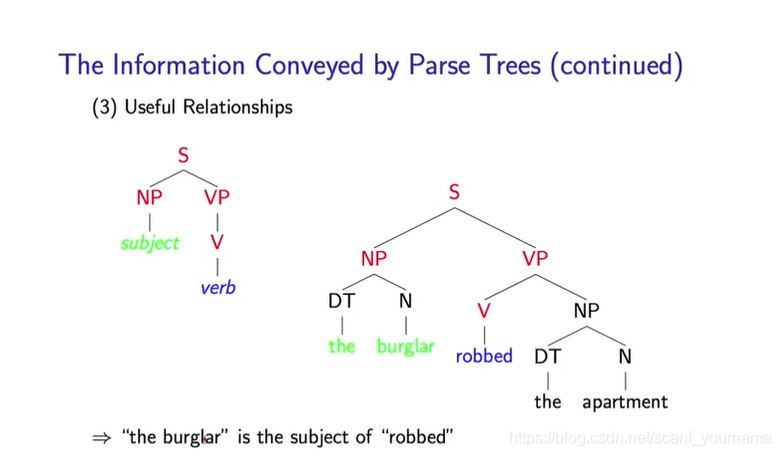
上图左侧为我们展示的就是一个最基础的主谓结构,如果机器可以学习到这样的结构,那么它就可以通过分析解析树找到句子中的主语以及谓语动词。
如何训练一个解析树
- 在这一节中,关于这个问题只给出了笼统的设计思想,所以就简述一下。大致思想是你现在拥有
5000个已经经过标注的解析树(就是数据),课件中说呢这些数据的来源是手工标注的(可以看出这是一个特别苦逼的工作)。
- 首先,选择出一部分数据作为训练集(啥是训练集呢?训练集就是你用来训练模型用到的数据,这一部分数据将占据所有数据的绝大部分,在数据较少的时代,一般训练集也会分到七成左右的数据,在数据规模庞大的项目中训练集数据甚至可以占据
98以上的数据)。课件中说选出
40000数据作为训练集(因为在这个问题中的数据规模不够大)
- 再选取一部分数据作为测试集(测试集是用来考量训练的模型有没有过拟合的,过拟合就是模型迁移能力不行,你告诉了模型1+1=2,模型学会了,转过头你问它2+2得啥它就懵逼了,你想想这能行吗?这简直就是人工傻子啊!赶快回炉再造吧,那么好这个2+2的问题就是测试集要做的),这里给了测试集
2400组数据。
- 可能有人会问剩下的数据哪去了?还有
7600组数据吃了?不好意思课件里还真没说。我斗胆猜测是放到了验证集里面了。验证集是啥我就不说了,想了解更多关于测试集、验证集以及训练集超参数调参的内容,推荐去学习吴恩达老师deeplearning.ai第二门相关课程。
- 下面是一个关于测试集、验证集、训练集的博客:https://blog.csdn.net/Raymond_MY/article/details/85209251
应用:机器翻译
- 举一个机器翻译的例子来解释一下解析的作用,有一个更感性的理解。在英语中我们一个基础的结构是主谓宾结构,在日语中基础的结构却是主宾谓,所以我们要把英语翻译成日语时,就要调整谓语动词和宾语的位置,下图所示的例子中解释了日语和英语结构的不同。

- 在机器翻译领域解决这一问题看似复杂,仔细考虑一下我们现在有解析树,之前讲过解析树的层级间反应的是这种句式关系。在句式结构方面,日语和英语唯一的不同就是谓语和宾语的位置不同需要对调。之前提到过的,在英语中在动宾短语的结构中,根节点表明这是一个动宾结构
VP,左孩子代表动词,右孩子代表一个名词性结构。也就是说,在这种情况下英语和日语句式结构的转换只需要调换左右子树,如下图所示:
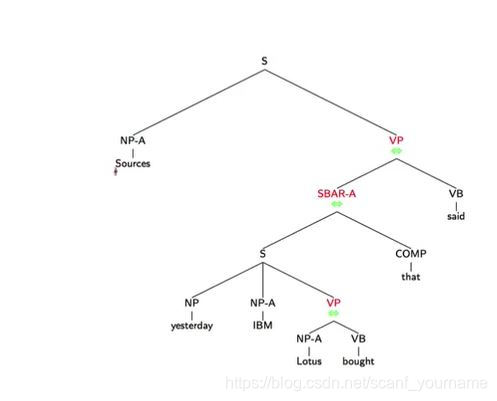
上图所示是一个日语解析树(虽然写的是英语,我们假设单词的翻译已经完成),句式结构是日式结构,图中绿色的节点是一些动宾结构的节点,我们现在要做的就是把这些绿色节点的左右子树对调就可以获得一个英式的解析树啦,相应的机器翻译也就完成了。
上下文无关文语
(Context−Free
Grammars)
定义
- 上下文无关文法是由一个四元组
G=(V,∑,R,S)构成的,下面我们依次定义四者。
-
V是“非终结”符号或变量的有限集合。它们表示在句子中不同类型的短语或子句。
-
∑是“终结符”的有限集合,无交集于
V,它们构成了句子的实际内容。
-
S是开始变量,用来表示整个句子(或程序)。它必须是
V的元素。
-
R是一种映射关系从
V映射到
(V∪∑)∗=∪n=0∞(V∪∑)n。
R是有限集合
,R的成员叫做文法的“规则”或“产生式”。
解释
- 终结符与非终结符
终结符与非终结符是形式语言的基本符号。终结符能在一个形式语法的推导规则的输入或输出字符串存在,而且它们不能被分解成更小的单位。非终结符则不能在最终的输出字符串存在,需要通过文法来替换。
比如:
S−>abc
a−>c
b−>c
上面的符号中
S、a、b都可以被解析成别的符号他们都是非终结符,
c不能被解析了所以是终结符。
- 还是上面的例子我们既然规定了非终结符和终结符那么就明白了:
V={Sab}
∑={c}
S=SϵV
R对应的则是上面三条映射关系的集合,当然在实际应用中可能不是上述三条关系,在这里只是举一个例子罢了。
左侧优先原则
- 在规定了上述基本概念以后,我们要考虑一个问题就是先从哪里开始解析,在这里给出一个规定就是从最左侧先开始解析。
- 根据规定我们知道解析开始的起点是
S,根据
R中的规则,我们找到
S对应的映射关系,将
S转化成解析出来的字符串。下一步依次从最左侧元素判断该元素是否属于
∑如果是则判断下一个元素,如果不是则在
R中找到其对应的解析语句进行解析,重复上述操作直至所有元素都属于集合
∑。这个过程和树的先序遍历十分类似,事实上最终我们也可以把这种解析结果绘制成一个二叉树。
- 在这里我们给出课件里的一个例子稍做分析:

最开始找到开始元素
S,它的解析结果是
NP和
VP,两者都不属于
∑需要进一步解析,按照左侧优先原则,首先解析
NP,解析出来的
D和
N依旧不是
∑的元素,按照左侧优先原则解析
D得到的单词
the属于
∑则停止解析,继续解析右侧元素
......
按照上述方法我们最终可以解析出最后一行的结果,这一过程确实酷似先序遍历,同时也可以用二叉树表示,这也进一步印证了我们前一节的用途。
上图最上方红色部分给出了解析完整的过程。
为什么叫与上下文无关?
英语句法
词性
- 名词
- 单数名词
(NN=singular
noun)
- 复数名词
(NNS=plural
noun)
- 专有名词
(NNP=proper
noun)
- 限定词
- 限定词
(DT=determiner)是用来修饰名词的,在英语里限定词可以被分成4类:冠词、指示词、数量词和物主形容词。
- 形容词
- 形容词
(JJ=adjective)
- 介词
- 介词
(IN=preposition)
- 动词
- 不及物动词
(Vi=Intransitive
verb:)不及物动词不能加宾语
- 及物动词
(Vt=Transitive
verb:)及物动词可以加宾语
- 双及物动词
(Vd=Ditransitive
verb:)双及物动词可以加双宾语
- 引导词
- 引导词
(COMP=complementizer)
eg.that
- 连接词
- 连接词
(CC=Coordinator)
eg.and
,or,but
短语&句子
- 名词性短语
(NP=Noun
Phrase)
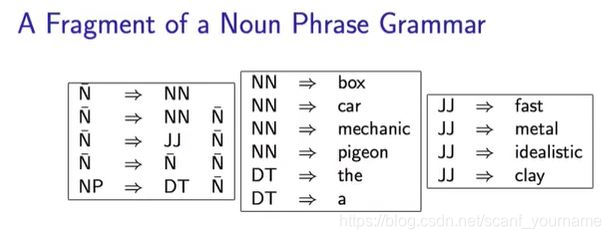
上图的左上角是构造一个名词性短语的方法,我们解释一下:
N叫什么我也不知道,就暂且叫它词组吧,名词性短语是有一个名词词组和限定词构成的
(NP是由限定词和
N构成的
),
N又有上面四种构造方式,意思就是名词、名词词组和形容词可以修饰名词构成一个新的词组。
- 介词短语
(PP=Preparation
Prase)
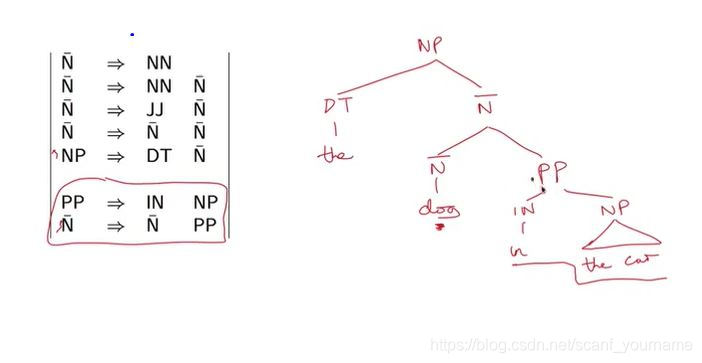
- 如上图所示,介词短语有两条规则,介词+名词短语可构成一个介词短语;介词短语要接在名词后。上图右侧是一个例子,介词
in与名词短语
the
car构成一个介词短语,这个介词短语跟在名词
dog后面,这个例子很好的展示了前面提到的两个规则。
- 动词短语
(VP=Verb
Prase)

- 如上图所示,不及物动词不能加宾语,所以它本身自己构成一个动词短语;对于及物动词需要加一个名词短语构成一个动词短语;双及物动词加双宾语一个形式宾语一个实际宾语,所以需要加上两个名词短语。
- 另一条规则是这样的:
VP⇒VP
PP
介词短语可以放在动词短语后面做状语构成一个更大的动词短语
比如:
sleep
in
a
car
- 句子
(S=Sentence)
S⇒NP
VP
- 从句用法
(SBAR)
SBAR⇒COMP
S

- 如上图所示,从句由引导词和句子构成,从句可以充当句子的成分,所以按照上图所示,给动词短语做扩充,动词短语可以加从句;可以加一个名词短语再加从句;可以加两个名词短语再加从句。
- 连接词用法

- 连接词连接两个并列成分,只要保证连接的两个成分类型一样即可,所以有了上图所示对于各种类型的补充用法。
歧义
(Ambiguity)
歧义来源
- 词性歧义:比如一个单词有不同的词性,因为词性不同造成歧义。
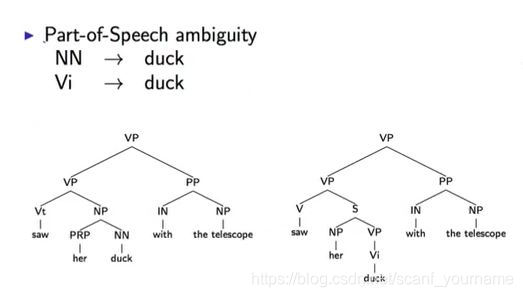
上图中的
duck有名词和动词两个词性,名词语意鸭子,动词语意闪避。上图左下展示的句子语意是用望远镜看她的鸭子,右面的语意是用望远镜看见她在闪躲。
- 结构歧义:不同分析树对应不同的结构,不同的句式结构会产生不同的语意。

上面的句子的歧义点在于
Bill修饰谁,一种理解
Bill修饰
shot在这种情况下句意为
John被认为是被
Bill射杀的;另一种理解
Bill修饰
believed在这种情况下句意则变为
John被射杀这一事实被
Bill相信。但是在英语中更多时候偏向前者,因为英语有就近指代规则,所以正常理解为第一种。
- 名词歧义:根本问题就是名词可以修饰名词,既然都是名词就要争个老大,到底谁是名词短语的中心词(其他词,包括名词修饰中心词)。这种情况要结合具体语境,具体问题具体分析。
转载自blog.csdn.net/scanf_yourname/article/details/86777756