首页
移动开发
物联网
服务端
编程语言
企业开发
数据库
业界资讯
其他
搜索
当当网图书
其他
2019-02-19 21:21:20
阅读次数: 0
目标站点需求分析
获取当当网每个图书名字和评论数
涉及的库
scrapy,mysql
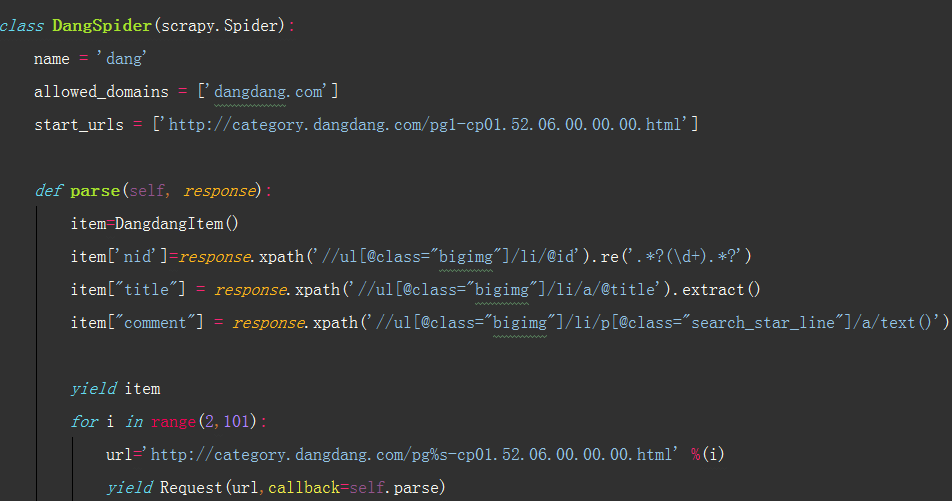
获取解析单页源码
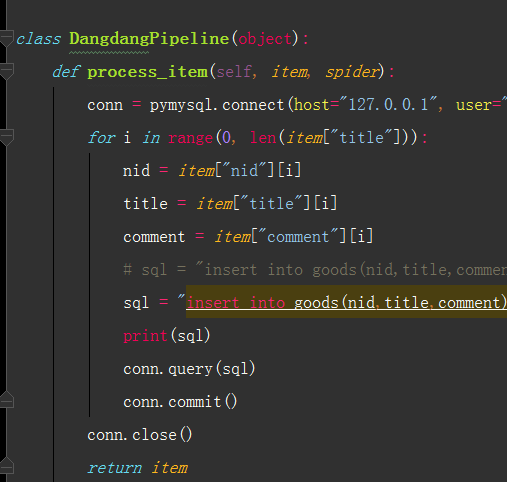
保存到数据库中
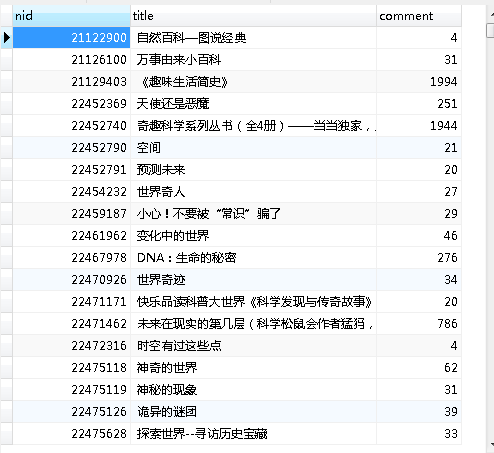
结果
猜你喜欢
转载自
www.cnblogs.com/du-jun/p/10403326.html
当当网图书
当当网
python当当网爬虫
scrapy 当当网 爬虫
Scrapy爬虫(5)爬取当当网图书畅销榜
利用lxml和request完成当当网图书信息提取
分布式爬虫----当当网图书数据爬取
利用python爬虫可视化分析当当网的图书数据!
基于Scrapy框架的当当网编程开发图书定向爬虫
保姆级scrapy框架实践:爬取当当网java图书数据
当当网程序设计类图书信息爬取
Python爬虫实战+Scrapy框架 爬取当当网图书信息
python课程设计——当当网Python图书数据分析
当当网 / sharding-jdbc
爬虫爬当当网书籍信息
当当网的elastic-job
dubbox 当当网编写下载
自写当当网1
纪念逝去的当当网
爬虫实例:当当网书籍介绍
scrapy爬取当当网
(转载)当当网开源的 dubbox 介绍
08年当当网中期项目
windows中搭建当当网
Python 当当网数据分析
爬虫及数据分析--当当网
爬虫基本原理介绍和初步实现(以抓取当当网图书信息为例)
[Python爬虫]爬虫实例:在线爬取当当网畅销书Top500的图书信息
[Python爬虫]爬虫实例:离线爬取当当网畅销书Top500的图书信息
爬取当当网2017畅销书目
今日推荐
周排行
LRU cache算法
windows10, 自带的OpenSSH, key权限问题, 文件权限问题
测试用例书写方法
HIVE-默认分隔符的(linux系统的特殊字符)查看,输入和修改
最贵的AMD 7nm显卡来了!这设计 够狂野
java多线程简单demo
[ 转载 ]在Android系统上使用busybox——最简单的方法
QT connect学习
BFSIFT算法分析
Xcode10:library not found for -lstdc++.6.0.9 临时解决
每日归档
更多
2024-08-06(0)
2024-08-05(0)
2024-08-04(0)
2024-08-03(0)
2024-08-02(0)
2024-08-01(0)
2024-07-31(0)
2024-07-30(0)
2024-07-29(0)
2024-07-28(0)