页面分析及数据抓取
anaconda + scrapy 安装:https://blog.csdn.net/dream_dt/article/details/80187916
用 scrapy 初始化一个爬虫:https://blog.csdn.net/dream_dt/article/details/80188592
要爬的网页:

复制网址后,在 Anaconda Prompt 中,cd 到项目所在目录,输入:
scrapy genspider skirt https://item.taobao.com/item.htm?id=537194970660&ali_refid=a3_430673_1006:1105679232:N:%E5%A5%B3%E8%A3%85:30942d37a432dd6b95fad6c34caf5bd5&ali_trackid=1_30942d37a432dd6b95fad6c34caf5bd5&spm=a2e15.8261149.07626516002.3
会生成一个新的文件:
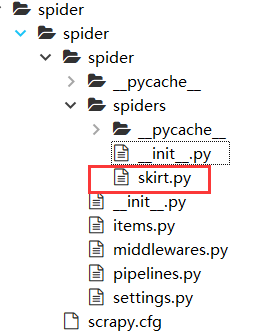
# -*- coding: utf-8 -*-
import scrapy
class SkirtSpider(scrapy.Spider):
name = 'skirt'
allowed_domains = ['https://item.taobao.com'] # 只保留域名
start_urls = ['http://https://item.taobao.com/item.htm?id=537194970660/'] # 主页面
def parse(self, response):
pass
创建一个 main 函数:
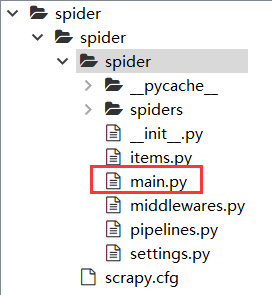
# -*- coding: utf-8 -*-
from scrapy.cmdline import execute
import sys
import os
sys.path.append(os.path.dirname(os.path.abspath(__file__))) # 导入执行路径
execute(["scrapy", "crawl", "skirt"]) # 在 shell 中执行命令
修改 settings.py,否则会把所有不符合规则的页面过滤掉
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
获取单价
在 Anaconda Prompt 中输入
scrapy shell https://item.taobao.com/item.htm?id=537194970660&ali_refid=a3_430673_1006:1105679232:N:%E5%A5%B3%E8%A3%85:30942d37a432dd6b95fad6c34caf5bd5&ali_trackid=1_30942d37a432dd6b95fad6c34caf5bd5&spm=a2e15.8261149.07626516002.3

因为 tb-rmb-num 只有一个,可以用 class 选择器定位,在 Anaconda Prompt 中输入
response.css('.tb-rmb-num')

为了拿到 128 那个值,输入
response.css('.tb-rmb-num::text')

response.css('.tb-rmb-num::text').extract()

response.css('.tb-rmb-num::text').extract()[0]

修改 skirt.py
def parse(self, response):
# 获取单价
price = response.css('.tb-rmb-num::text').extract()[0]
获取评论数

在 Anaconda Prompt 中输入
response.css('#J_RateCounter::text').extract()

没有拿到数据,说明该数据可能是通过 js 动态渲染的,需要分析源代码。

将 rateCountterApi 对应的 url 复制到浏览器中,得到如下结果

可见该评论数位于第一条 script 中的 rateCounterApi 字段。
在 Anaconda Prompt 中输入
response.css('script::text')[0].extract()

修改 skirt.py
def parse(self, response):
# 获取单价
price = response.css('.tb-rmb-num::text').extract()
# 获取页面渲染脚本的第一个结构
first_js_script = response.css('script::text')[0].extract()
筛选数据,获取评论数
第一条 js 数据中第一个字段的开头
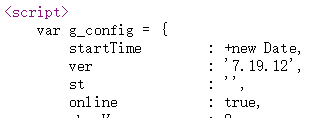
第一条 js 数据中第一个字段的结尾

用正则表达式匹配出第一条 js 数据中第一个字段。
\s:空白符
\S:非空白符
*:重复任意多次
匹配出的结果是一个 list,skirt.py 中添加
import re
g_config = re.findall('var g_config = ([\s\S]*)g_config.tadInfo', first_js_script)[0]
需要匹配出 rateCounterApi 对应的 url

skirt.py 中添加
rate_counter_api = re.findall("rateCounterApi : '//(.*)',", g_config)[0]
访问获取评论的 url,skirt.py 中添加,
import requests
rate_count_response = resquests.get("http://" + rate_counter_api) # null({"count":627})
得到评论数量,skirt.py 中添加,
rate_count = re.findall('"count":(.*)}', rate_count_response)[0]
现在,skirt.py 成为:
# -*- coding: utf-8 -*-
import scrapy
import re
import requests
class SkirtSpider(scrapy.Spider):
name = 'skirt'
allowed_domains = ['https://item.taobao.com'] # 只保留域名
start_urls = ['https://item.taobao.com/item.htm?id=537194970660&ali_refid=a3_430673_1006:1105679232:N:%E5%A5%B3%E8%A3%85:30942d37a432dd6b95fad6c34caf5bd5&ali_trackid=1_30942d37a432dd6b95fad6c34caf5bd5&spm=a2e15.8261149.07626516002.3']
def parse(self, response):
# 获取单价
price = response.css('.tb-rmb-num::text').extract()
''' 获取评论数量 '''
# 获取页面渲染脚本的第一个结构
first_js_script = response.css('script::text')[0].extract()[0]
g_config = re.findall('var g_config = ([\s\S]*)g_config.tadInfo', first_js_script)[0]
rate_counter_api = re.findall("rateCounterApi : '//(.*)',", g_config)[0]
# 访问获取评论的 url
rate_count_response = requests.get("http://" + rate_counter_api) # null({"count":627})
# 获取评论数量
rate_count = re.findall('"count":(.*)}', rate_count_response.text)[0]
print(price)
print(rate_count)
不知为什么,运行 mian 函数后会出现错误:
raise error.ReactorNotRestartable()
ReactorNotRestartable
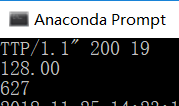
于是在 Anaconda Prompt 中输入:
scrapy crawl skirt

得到结果:
获取具体的评论信息

同样不能从页面直接获取,是通过 js 脚本从别的地方加载进来的,与评论数量的获取方式类似。
选择“Network”选项,清空一下
点击评论第 2 页,可以看到一些结果

点击那个链接,验证是否为评论信息

该如何获取该评论信息?切换到“Headers”选项,可以看到 Request URL

将该 url 复制后,复制到新的浏览器查询页面后,可以得到:

所以接下来分析该 url,里面有哪些东西是可用的。该 url 具体如下
https://rate.taobao.com/feedRateList.htm?auctionNumId=537194970660&userNumId=794196473¤tPageNum=2&pageSize=20&rateType=&orderType=sort_weight&attribute=&sku=&hasSku=false&folded=0&ua=098%23E1hvKpvWvPvvUvCkvvvvvjiPR2MhAjnCPLd9zjrCPmP9gjDnRFsy6jEmn2MUsjrm9phvVZ2MWlAQ7rMNz1CKz8otUSiswIFU1qYbJzWPvpvhvv2MMQyCvhQhhQyvCsxleExrV8t%2Bm7zhaf9gKFnfIExrs8TZfvDrAjc6%2Bul1bbmxfwp4d56Ofw3l%2Bb8rwkM6D7zhVut%2Bm7zh6j7J%2B3%2BiafmxfBeKKphv8vvvvvCvpvvvvvv2vhCvmnGvvvWvphvW9pvvvQCvpvs9vvv2vhCv2RmivpvUvvmv%2BQeoltAEvpvVmvvC9jXmvphvC9vhvvCvp2yCvvpvvvvviQhvCvvv9U8jvpvhvvpvv2yCvvpvvvvvdphvmQ9ZW9UYPpLY5gyA&_ksTS=1543128829263_1021&callback=jsonp_tbcrate_reviews_list
可以看到用 & 符号连接一些参数。以下这部分 url 比较好懂,而后面的部分不好懂,先忽略,用以下新的 url 打开新的页面
https://rate.taobao.com/feedRateList.htm?auctionNumId=537194970660&userNumId=794196473¤tPageNum=2&pageSize=20

可以看到请求成功,说明 url 后面的部分没有用。
同理,userNumId 参数没有用,可删掉,将 currentPageNum = 1,可得到如下页面
https://rate.taobao.com/feedRateList.htm?auctionNumId=537194970660¤tPageNum=1&pageSize=20

而参数 pageSize 表示一次请求多少条评论信息,默认是 20 条。
接下通过拼接的方式得到以下类似的 url,以获取具体评论信息。
https://rate.taobao.com/feedRateList.htm?auctionNumId=537194970660¤tPageNum=2&pageSize=20
获得拼接 url 的前面部分,即 “https://rate.taobao.com/feedRateList.htm”

在 Anaconda Prompt 中输入
response.css('#reviews')

然后从中获取 url,“::” 后面跟 attr,而不是 text
data_listapi_url = response.css('#reviews::attr(data-listapi)').extract()[0]

# 评论的 url
feed_rate_list_url = re.findall("\/\/(.*?)\?", data_listapi_url)[0]
\:转义字符
?:遇到第一个匹配的后停止

获取需要拼接的 url 中的参数:宝贝 id
# 宝贝 id
auction_num_id = re.findall("auctionNumId=(.*?)&", data_listapi_url)[0]

获取所有评论信息
接下来完成每页 url 的拼接。
# 计算一共有多少页的评论
page_size = 20
pages = math.ceil(int(rate_count) / page_size) # rate_count 为前面获取的评论数量
拼接各种参数,得到 url
for current_page_number in range(1, pages):
yield scrapy.Request(url = "http://"+ feed_rate_list_url
+ "?auctionNumId=" + auction_num_id
+ "¤tPageNum=" + str(current_page_number)
+ "&pageSize=" + str(page_size),
callback = self.parse_rate_list) # 如何处理该页面
回调函数
def parse_rate_list(self, response):
print(response.text)
现在,skirt.py 如下
# -*- coding: utf-8 -*-
import scrapy
import re
import requests
import math
class SkirtSpider(scrapy.Spider):
name = 'skirt'
# 允许的域名,如果没有把域名写在这里,那么将会过滤掉
allowed_domains = ['item.taobao.com',
'rate.taobao.com'] # 只保留域名
# 从哪个页面开始抓取
start_urls = ['https://item.taobao.com/item.htm?id=537194970660&ali_refid=a3_430673_1006:1105679232:N:%E5%A5%B3%E8%A3%85:30942d37a432dd6b95fad6c34caf5bd5&ali_trackid=1_30942d37a432dd6b95fad6c34caf5bd5&spm=a2e15.8261149.07626516002.3']
def parse(self, response):
# 连衣裙的单价
price = response.css('.tb-rmb-num::text').extract()[0]
''' 获取评论数量 '''
# 获取到页面渲染的第一个脚本的数据结构
first_js_script = response.css('script::text')[0].extract()
# 正则匹配到g_config字段
g_config = re.findall('var g_config = ([\s\S]*)g_config.tadInfo', first_js_script)[0]
# 正则匹配,拿到页面的评论 url
rate_counter_api = re.findall("rateCounterApi : '//(.*)',", g_config)[0]
# 访问获取评论的 url
rate_count_response = requests.get("http://" + rate_counter_api) # null({"count":627})
# 获取评论数量
rate_count = re.findall('"count":(.*)}', rate_count_response.text)[0]
# 该请求可获取具体的评论信息
# https://rate.taobao.com/feedRateList.htm?auctionNumId=537194970660¤tPageNum=2&pageSize=20
# 拿到 data_listapi_url,这个能够匹配到域名
data_listapi_url = response.css('#reviews::attr(data-listapi)').extract()[0]
# 获取到评论的 url
feed_rate_list_url = re.findall("//(.*?)\?", data_listapi_url)[0]
# 宝贝 id
auction_num_id = re.findall("auctionNumId=(.*?)&", data_listapi_url)[0]
# 设置一个值,一页获取的评论数量
page_size = 20
# 计算一共有多少页的评论
pages = math.ceil(int(rate_count) / page_size)
# 迭代一共有多少页,然后分别请求每一页评论
for current_page_number in range(1, pages):
yield scrapy.Request(url = "http://"+ feed_rate_list_url
+ "?auctionNumId=" + auction_num_id
+ "¤tPageNum=" + str(current_page_number)
+ "&pageSize=" + str(page_size),
callback = self.parse_rate_list) # 如何处理该页面
# 解析具体的评论
def parse_rate_list(self, response):
print(response.text)
运行
scrapy crawl skirt
结果如下
