
0. 写在前面
感觉GraphLab非常惊艳,可以在python环境当中非常好地使用。但它在接受了两轮投资之后已经由原来的免费项目变成了一个付费试用的项目。但是个人和学术使用依然可以申请。伴随着这个商业化的过程,graphlab.org也变成了dato.com。下面详细介绍GraphLab单机测试和集群部署的过程。
1. 实验环境
| 系统 | 主机名 | IP地址 | 内存 | CPU |
|---|---|---|---|---|
| Ubuntu12.04 64bit | namenode | 10.107.12.10 | 62GB | 12核 |
| Ubuntu12.04 64bit | datanode1 | 10.107.12.20 | 62GB | 12核 |
| Ubuntu12.04 64bit | datanode2 | 10.107.12.50 | 62GB | 12核 |
| Ubuntu12.04 64bit | datanode3 | 10.107.12.60 | 62GB | 12核 |
2. GraphLab 单机环境配置
先到官网注册申请免费使用版本
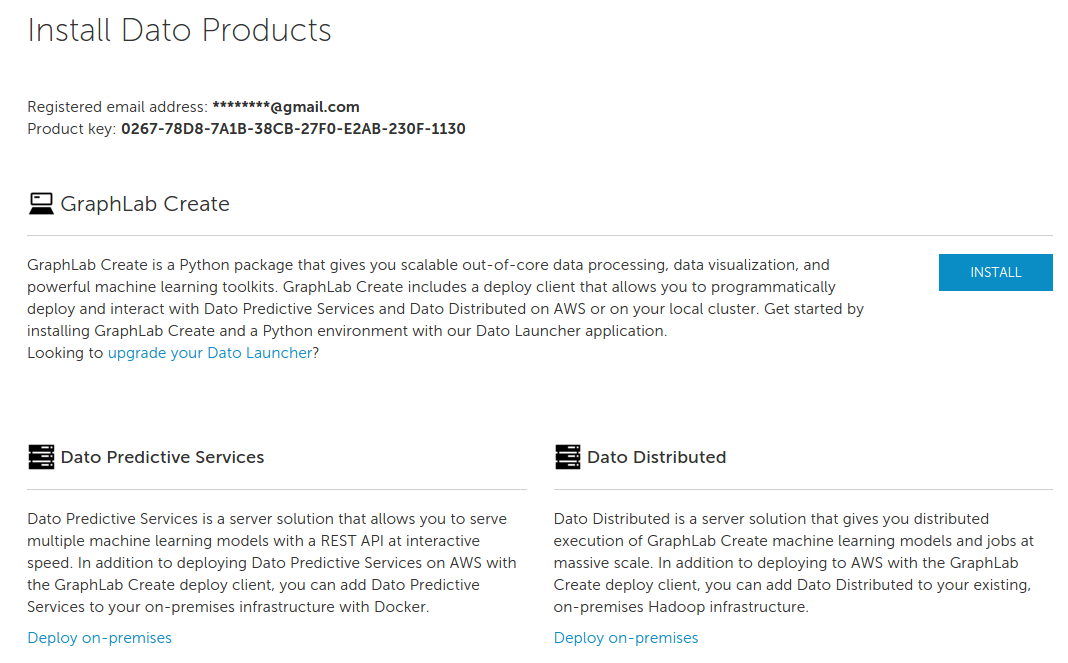
注册完之后会跳转到下载页面,页面上会提供
Product key,记住该注册码,下载软件时需要使用。点击 INSTALL 进入安装本地运行环境导航页面,根据自己的系统,选择相应的版本。
安装python版本要高于2.7,pip版本高于7。
sudo apt-get install python python-pip ipython[notebook]安装GraphLab Create,your email和product key填写你自己的邮箱和刚才保存的注册码。
pip install --upgrade https://get.dato.com/GraphLab-Create/1.7.1/your email/product key/GraphLab-Create-License.tar.gz终端输入
ipython,简单测试环境是否成功,然后输入import graphlab,如果导入成功,恭喜你单机环境已经配置成功。这里有一个简单的blog教程。
3. GraphLab 集群部署
安装Hadoop分布式集群环境,详细过程点击这里。
回到有注册码的页面,点击 Deploy on-premises,进入GraphLab分布式部署下载页面。
下载
dato-distributed-1.7.1.tar.gz和Dato-Distributed-Services.ini license两个包。将两个文件拷贝到namenode节点,并解压。然后执行下面命令:
cd dato-distrib-1.7.1 ./setup_dato-distributed.sh -d hdfs://10.107.12.10:/graphlab -k ../Dato-Distributed-License.ini -c ../../spark_sdk/hadoop-2.7.1/etc/hadoop/
- 1
- 2
-d 执行hdfs的存储路径,该路径在hdfs中要不存在,否则不能创建;-k 注册码文件路径;-c hadoop配置文件的路径。
- 集群运行graphLab简单程序,先在namenode终端输入
ipython进入python环境,然后执行下面代码:
import graphlab as gl # 建立集群 c = gl.deploy.hadoop_cluster.create( name='test-cluster', dato_dist_path='hdfs://10.107.12.10:9000/graphlab', hadoop_conf_dir='~/spark_sdk/hadoop-2.7.1/etc/hadoop') def echo(input): return input j = gl.deploy.job.create(echo, environment=c, input='helll world!') j.get_results()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
【完】
再分享一下我老师大神的人工智能教程吧。零基础!通俗易懂!风趣幽默!还带黄段子!希望你也加入到我们人工智能的队伍中来!https://blog.csdn.net/jiangjunshow