LSDA算法(基于大量类别的场景)
LSDA算法背景
资源
论文全称:LSDA: Large Scale Detection through Adaptation
论文链接:https://arxiv.org/abs/1407.5035
论文日期:2014.11.01
算法简介
目前基于大尺寸目标检测的难点:检测数据集标签难以获取。
本文算法就是针对含有检测标签的类别,学习分类与检测两者这件的差别,然后将这些差别迁移到没有检测标签的类别上,训练出检测器。
本文提出的LSDA算法是基于含有大量类别的场景进行目标检测的算法,目前有很多金典算法在目标检测领域表现优秀,检测准确度有了很大的提升,但是这些算法的检测场景中只包含20个左右类别的对象,而现实场景中,对象种类成千上万,这些金典算法基于大尺寸场景的检测表现的不够突出,因此本文提出了一个基于迁移学习原理的自适应检测算法。
由于分类数据集通过搜索引擎可以得到大量的数据,这些数据的标签是图像级别的,只需要识别是何种对象,而检测数据集的标签还需要精确的定位边界框,检测数据集难以获取。目前有很多分类数据集含有上千类目标,可以训练出很好的分类网络,但是检测数据集只有上十类的对象,检测这上十类目标准确率很高,但是应用于其他类别的对象则表现不佳。因此,本文提出了一个迁移学习算法,首先利用分类数据集初始化神经网络,然后再利用检测数据集进行微调,然后将检测数据集训练的参数迁移到没有检测标签的类别上。
算法详情
算法的核心就是针对含有检测标签的类别,学习分类与检测之间的配对关系,然后迁移到不含检测标签的类别上,训练出针对所有类别的检测器。

本算法就是一个迁移问题,将分类器作为源域,检测器作为目标域,找到源域到目标域的一个通用迁移,从而任何图片分类器都可以应用到目标检测中。
算法对比
R-CNN
Girshick等人提出的R-CNN阐述的以微调形式的自适应算法,对于迁移算法非常重要,也影响了本文的算法。但是R-CNN算法只使用分类数据进行预训练,之后就需要大量的边界框标签去训练每一个检测类别,不能对不含标签的类别进行推断。
本文的LSDA算法只需要少量的检测数据,这些数据只针对少量的类别,并且训练时间相对更短,主要目的是进行从分类器到检测器的迁移。
本文中也经过实验表明,在ImageNet检测任务上,对于那些只在提取区域上使用仅仅分类器权重的基础算法,准确度达到了相对50%的提升。
MIL算法
Multiple Instance Learning (MIL)算法使用弱标签训练检测器,弱标签是指只含有类别标签而不含有边界框标签,MIL范式估计正样本训练袋中的潜在标签,每一个正样本袋中至少包含一个正样本。
MIL算法没有应用于大尺寸的ImageNet检测挑战,所以无法比较。
Domain adaptation算法
区域自适应算法的重点就是减小训练域与测试域之间统计分布的差异找出的数据偏差。在本文中,将分类器作为源域,检测器作为目标域,从而将从分类器到检测器之间的迁移问题转换为域自适应问题。
之前也有许多针对分类器自适应的算法被踢提出,但是甚至联合学习模型也不能优化特征提取过程,因此被限制到浅的自适应技术。除此之外,这些方法仅仅被用于视觉域之间,任务被固定了。在本文中,我们不仅应用于从一个大视觉域到更小的视觉域,还应用于从分类器到检测器。
监督域自适应模型
给一个在源域上训练的检测器,在带有标签的目标域数据上调整参数,包含线性支持向量机,自适应潜在SVM,自适应样本SVM。但是这些算法需要在目标域与源域上所有类别的检测数据标签。
算法实现
假设含有K个类别想要被检测,但是只有m个类别的检测标签。将这m个带有边界框标签的类别作为一个集合B: B = {1,…,m},然后将剩余没有边界框标签的类别作为一个集合A: A = { m,…,K}。m<<K,这K个类别均含有分类标签,我们使用这些数据初始化神经网络。
LSDA算法有3个重要优势:
- 使分类器适应检测器的过程中识别背景是很重要的一步;
- 可以在分类器和检测器特征表示之间传送类别不变信息;
- 在分类器与检测器之间可能有特定类别差异。

Category Invariant Adaptation
神经网络采用Krizhevsky结构,这个神经网络需要大量的数据与时间来训练大概6000万个参数。
首先利用分类数据集ILSVRC2012进行预训练,包含1000类的120万张图片。然后使用K个线性分类器替代原始的最后一层(1000个线性分类器),这K个线性分类器就是代表任务中的每一个类别。权重是任意初始化的,然后利用分类数据微调整个神经网络。
然后迁移分类神经网络到检测神经网络,通过使用具有检测数据标签的集合B微调来训练神经网络的1-7层,根据R-CNN算法,我们对于集合B中的每一类别收集正样本边界框,使用在剪切之后的每一个带标签区域作为微调的输入,与R-CNN不同,不需要所有类别的检测数据标签,微调迁移所有的神经网络权重并且生成一个适用于所有类别的softmax检测器,包含一个新背景类别的权重向量。
集合B的所有类别间共享1-7层的参数,类别不变信息在分类网络与检测网络之间转换时使用,尽管微调没有集合A内的检测数据,网络以一种自动使原始集合A图像分类器在检测上更有效的方式进行变换,=同时微调也学习了背景权重向量。
Category Specific Adaptation
最后学习了一个特定类别转换,它将分类器模型参数转换为在检测特征表示上操作的检测器模型参数。特定类别的输出层由fcA, fcB, δB, 与 fc − BG组成。对于集合B中的类别,是相等的去固定fcB,然后学习一个零初始化的新层δB,使用与fcB相同的损失函数,将fcB与δB两者相加。
定义原始分类网络的输出层权重为Wc, 适用检测网络的输出层为Wd,
将最终的检测权重计算为Wid=Wic+δBi 。
对于没有检测数据的集合A,不使用直接学习的方法,而是如果有检测数据,可以近似于fcA发生的微调。使用KNN算法,通过找到集合B中与集合A中每一个类别最相近的类别,并且使用平均值计算。
而这些最相近的类别就是通过L2正则化计算分类网络的fc8参数得到。
计算方式是:
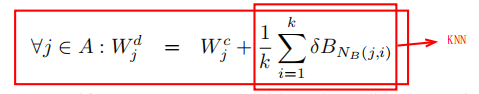
Detection with LSDA
在测试阶段,使用神经网络对于图片中的每一个候选区域提取K+1个分数,结合每一个类别的分数与背景分数对于类别i的分数计算:scorei-scorebackground 。
本算法直接使用最后的分数向量生成预测分数,而没有任意重复训练的步骤,这一选择也导致了很小的损失,提高了准确度的同时缩短了训练时间。
实验
本文选用ILSVRC2013检测数据集,这个数据集包含200个类别,我们选用200类别的只含有分类标签,其中100个类别含有检测数据标签(按字母顺序进行排序)。
实验结果:

使用KNN算法,对于K的的=选择,选择k = 10,准确度达到16.15%mAP,使用配对样本t-test,在p=0.017时具有统计学意义。

误差分析
有三种类型的false positive errors:
- 定位误差;
- 与背景混淆;
- 其他类型。
大多数的false positive errors是与背景混淆以及定位误差,相反,在使用LSDA算法之后,由于定位与背景混淆,在top false positives中误差要远小于之前。

结论
LSDA算法使用自适应算法相对提高了分类网络50%的表现,并且显著减小了生产高质量检测器的开销。