TICK : Telegraf + InfluxDB + Chronograf + Kapacitor
Telegraf:Telegraf是一个数据采集套件,对应用、容器等进行监控,监控采集的数据会发送给influxDB。
InfluxDB:go语言开发的时序数据库,专门负责存储时序数据。
Chronograf :可视化的监控展示服务。
Kapacitor:Kapacitor是一款时序数据分析处理、告警的软件。可以周期性将InfluxDB中的数据汇总、处理后再输出到InfluxDB当中,或者告警(支持Email、HTTP、TCP、 HipChat, OpsGenie, Alerta, Sensu, PagerDuty, Slack等多种方式)
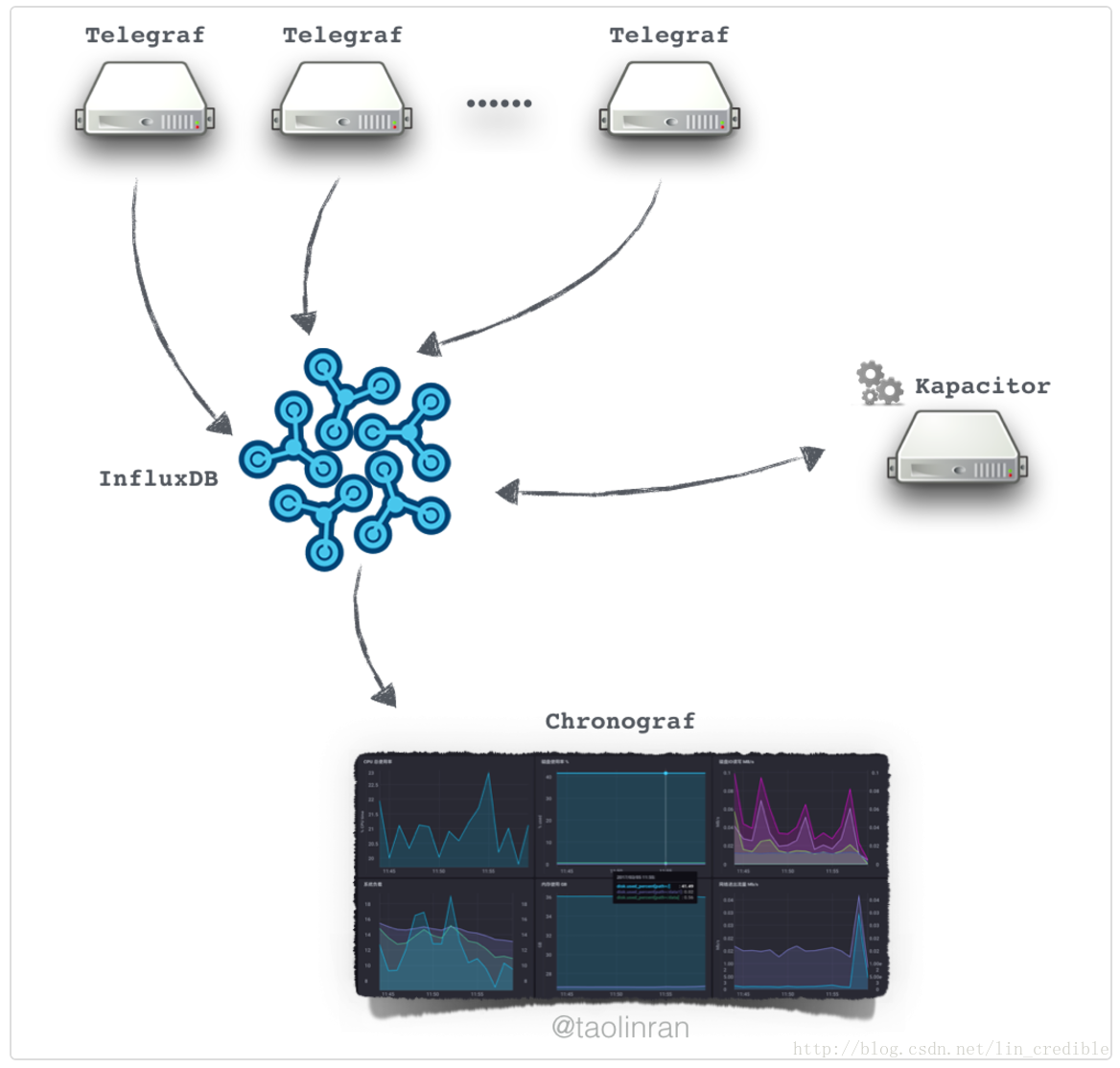
这四个组件组成了性能监控的数据管道:Telegraf负责采集节点上的性能数据,然后放入InfluxDB数据库进行存储,Kapacitor通过监听InfluxDB的性能数据来对异常指标发出告警,而Chronograf用来展示集群实时的各项性能指标和状态,提供一个可视化的界面。
TICKscript中一些核心概念
task:
task是一个tickscript的最大粒度单位,可以说,一个tickscript就是一个task,一段脚本要执行,首先需要经过kapacitor对当前的task文件进行编译然后才能执行。
pipeline:
pipeline就是指管道,标识数据的流向
kapaciotr当中的数据是由influxdb处监听获取,从管道
自上而下进行处理,可以有分支,可以有交汇,但是不可以回溯,管道根据数据源来源方式不同,可以分为两种,即stream和batch。
stream 数据流:
kapacitor关键字之一,用来标识数据流来源的入口,即它会监听每一个插入influxdb的数据,然后通过管道当中的各个节点进行处理,最终流向管道底部。
batch 批处理:
kapacitor关键字之一,用来标识批处理数据来源的入口,可以理解为每隔一段时间执行一条influxQL去influxdb当中查询数据,查询到的结果集会随当前batch所在的管道流向底部。
stream和batch的区别:
stream是监听当前influxdb每一个时间点插入的数据流,而batch则是获取的InfluxQL查询的结果集,此结果集应该是单行的,stream下面可以不用直接跟from()方法指定数据库和表(即会监听当前所有插入influxdb的数据)。
但是batch方法下必须指定query()作为批处理对数据进行筛选。
node:
用来组成管道的节点,可以理解为我们常见的水管上用来拼接成管道的连接头,也可以理解为processor point,即数据处理器节点,一个pipeline是通过多个node组成的。
influxDB中的一些核心概念
database、retention policy、measurement、filed、tag:
influxDB与传统数据库中的名词做比较
| influxDB中的名词 | 传统数据库中的概念 |
| database | 数据库 |
| retention policy | 保留策略,用于决定要保留多久的数据,保存几个备份,以及集群的策略等,默认为autogen,保存永久 |
| measurement | 测量指标,相当于数据库中的表 |
| points | 相当于表里面的一行数据 |
Points
Points由时间戳(time)、数据(field)、标签(tag)组成。
| Point属性 | 传统数据库中的概念 |
| time | 每个数据记录时间,是数据库中的主索引(会自动生成) |
| field | 各种记录值(没有索引的属性),相当于column |
| tag | 各种有索引的属性,相当于index |
具体的例子:

这一整块代码是一个task,通常一个task被拆分为两个部分,declaration和expression。上图红框上面就是declaration,定义了一些变量。红框里面就是一个pipeline,这个pipeline是由query、httpOut、alert、httpOut这四个node构成的,其中在alert中又包含了四个属性方法(property method),分别是id、info、message、post。代码的执行过程会自上而下,沿着管道一直执行到末尾。
另外,TICKscript里面一些特别的语法:
一些特殊的运算符:
=~ : 判断正则表达式是否匹配。
!~ : 判断正则表达式是否不匹配。

var 声明一个变量,和js一样,不用指定变量类型,统一用var声明即可。一共有这几种类型:
- 其中的duration literal可以理解为时间常量,它是由一个数字+一个时间单位组成,时间单位有这几种:

- 字符串使用一个单引号或者三个单引号引起来的。比如'hello world' 或 '''hello world'''。可以用+连接字符串。
- 布尔类型必须写为大写的TRUE或FALSE,其他写法会报编译错误。
- lambda 用来表示一个表达式的TRUE或FALSE。例如:
var lazy_lambda = lambda: "usage_idle" < 95
| 连接多个node的标识符,多个node可以用这个标识符连接成一个pipeline。
. 通过这个标识符也可以连接多个属性方法(property method)使之成为一个node中的属性管道。
@ 可以理解为用户自定义一个属性方法(user defined function)。
原文:

String templates(字符串模版):
用两个大括号{{}}可以引用一个property(属性)、tag(标签)、field(字段)。
要引用一个property,需要前面加一个.
要引用一个tag或者field,需要前面加一个index .(注意是index后加一个空格再加一个.)
例如:
原文:

字符串数组:
可以用多种方式声明一个字符串数组,
var cpu_groups = [ 'host', 'cpu' ]或者
var foo = 'foo'
var bar = 'bar'
var foobar_list = [foo, bar]Named lambda expression access(命名lambda表达式结果)
lambda表达式的结果可以为其取一个新的名字,例如:

图中用as方法为eval函数计算的lambda表达式的结果赋了新名字sigma,后面的alert函数可以直接把sigma当作field来用。
其中的eval为influxQL中的node。
httpOut:
当代码执行到httpOut节点时,kapacitor会将当前的数据上传,可以通过 host:/kapacitor/v1/tasks/$task_id/$httpOut_id 来查看。