关系数据库的基本操作就是增删改查,即CRUD:Create、Retrieve、Update、Delete。前两篇博文讲解了数据库的基本理论知识与它的简单的操作流程,包括一些简单的指令,可以说是简单的入门,所以本篇博文将主要讲解SQL指令用法。
注意:该部分总结适用MySQL,有些特殊适用方法可能不适用其他数据库,使用其他数据库时请最好以相应的数据库支持为准。
MySQL常用关键字:
- SELECT - 从数据库中提取数据
- UPDATE - 更新数据库中的数据
- DELETE - 从数据库中删除数据
- INSERT INTO - 向数据库中插入新数据
- CREATE DATABASE - 创建新数据库
- ALTER DATABASE - 修改数据库
- CREATE TABLE - 创建新表
- ALTER TABLE - 变更(改变)数据库表
- DROP TABLE - 删除表
- CREATE INDEX - 创建索引(搜索键)
- DROP INDEX - 删除索引
| SQL 语句 |
语法 |
备注 |
| AND / OR |
SELECT column_name(s) |
用于基于一个以上的条件对记录进行过滤 |
| ALTER TABLE |
ALTER TABLE table_name or ALTER TABLE table_name |
用于在已有的表中添加、删除或修改列 |
| AS (alias) |
SELECT column_name AS column_alias or SELECT column_name |
取别名,创建别名是为了让列名称的可读性更强 |
| BETWEEN |
SELECT column_name(s) |
用于选取介于两个值之间的数据范围内的值,可以是数值、文本或者日期(不同数据库代表的范围可能不同) |
| CREATE DATABASE |
CREATE DATABASE database_name |
用于创建数据库 |
| CREATE TABLE |
CREATE TABLE table_name |
用于创建数据库中的表 |
| CREATE INDEX |
CREATE INDEX index_name or CREATE UNIQUE INDEX index_name |
用于在表中创建索引。 在不读取整个表的情况下,索引使数据库应用程序可以更快地查找数据
|
| CREATE VIEW |
CREATE VIEW view_name AS |
创建基于 SQL 语句的结果集的可视化的表 |
| DELETE |
DELETE FROM table_name or DELETE FROM table_name DELETE * FROM table_name |
用于删除表中的记录 |
| DROP DATABASE |
DROP DATABASE database_name |
用于删除数据库 |
| DROP INDEX |
DROP INDEX table_name.index_name (SQL Server) |
用于删除表中的索引 |
| DROP TABLE |
DROP TABLE table_name |
用于删除表 |
| GROUP BY |
SELECT column_name, aggregate_function(column_name) |
分组聚合 |
| HAVING |
SELECT column_name, aggregate_function(column_name) |
当分组筛选的时候用HAVING,用HAVING就一定要和GROUP BY连用 |
| IN |
SELECT column_name(s) |
允许您在 WHERE 子句中规定多个值(注意不是范围,是值) |
| INSERT INTO |
INSERT INTO table_name or INSERT INTO table_name |
用于向表中插入新记录 |
| INSERT INTO SELECT |
INSERT INTO table2 or INSERT INTO table2 |
从一个表复制数据,然后把数据插入到一个已存在的表中。目标表中任何已存在的行都不会受影响 |
| INNER JOIN |
SELECT column_name(s) |
如果表中有至少一个匹配,则返回行 |
| LEFT JOIN |
SELECT column_name(s) |
即使右表中没有匹配,也从左表返回所有的行
|
| RIGHT JOIN |
SELECT column_name(s) |
即使左表中没有匹配,也从右表返回所有的行
|
| FULL JOIN |
SELECT column_name(s) |
只要其中一个表中存在匹配,则返回行
|
| LIKE |
SELECT column_name(s) |
用于在 WHERE 子句中搜索列中的指定模式 |
| ORDER BY |
SELECT column_name(s) |
用于对结果集进行排序 ASC(默认为正序排序) DESC倒序 |
| SELECT |
SELECT column_name(s) |
从数据库中选取数据。 结果被存储在一个结果表中,称为结果集 |
| SELECT * |
SELECT * |
从xxx表中选取所有列 |
| SELECT DISTINCT |
SELECT DISTINCT column_name(s) |
返回唯一不同的值 |
| SELECT INTO |
SELECT * or SELECT column_name(s) |
从一个表复制数据,然后把数据插入到另一个新表中 |
| SELECT TOP |
SELECT TOP number|percent column_name(s) |
用于规定要返回的记录的数目(这是MySQL语法,不同数据库有不同语法) |
| TRUNCATE TABLE |
TRUNCATE TABLE table_name |
清空表数据 |
| UNION |
SELECT column_name(s) FROM table_name1 |
合并两个或多个 SELECT 语句的结果,每个 SELECT 语句中的列的顺序必须相同。过滤重复。 |
| UNION ALL |
SELECT column_name(s) FROM table_name1 |
合并两个或多个 SELECT 语句的结果,每个 SELECT 语句中的列的顺序必须相同,全部显示,不过滤 |
| UPDATE |
UPDATE table_name |
用于更新表中已存在的记录 |
| WHERE |
SELECT column_name(s) |
用于提取那些满足指定标准的记录 |
-
WHERE 子句中的运算符
下面的运算符可以在 WHERE 子句中使用:
| 运算符 |
描述 |
例子 |
| = |
等于 |
|
| <> |
不等于。注释:在 SQL 的一些版本中,该操作符可被写成 != |
|
| > |
大于 |
|
| < |
小于 |
|
| >= |
大于等于 |
|
| <= |
小于等于 |
|
| BETWEEN |
在某个范围内 |
Select * from emp where sal between 1500 and 3000; |
| LIKE |
搜索某种模式 |
Select * from emp where ename like 'M%'; 查询 EMP 表中 Ename 列中有 M 的值,M 为要查询内容中的模糊信息。 % 表示多个字值,_ 下划线表示一个字符; M% : 为能配符,正则表达式,表示的意思为模糊查询信息为 M 开头的。 %M% : 表示查询包含M的所有内容。 %M_ : 表示查询以M在倒数第二位的所有内容。 ‘_ M _’ //三位且中间字母是M的 '_ M ' //两位且结尾字母是M的 ' M _' //两位且开头字母是M的 |
| IN |
指定针对某个列的多个可能值 |
Select * from emp where sal in (5000,3000,1500); 查询 EMP 表 SAL 列中等于 5000,3000,1500 的值 |
| IS NULL |
空值判断 |
Select * from emp where comm is null; |
在 MySQL 中可以通过设置 sql_safe_updates 这个自带的参数来解决,当该参数开启的情况下,你必须在update 语句后携带 where 条件,否则就会报错。
set sql_safe_updates=1; 表示开启该参数
-
JOIN
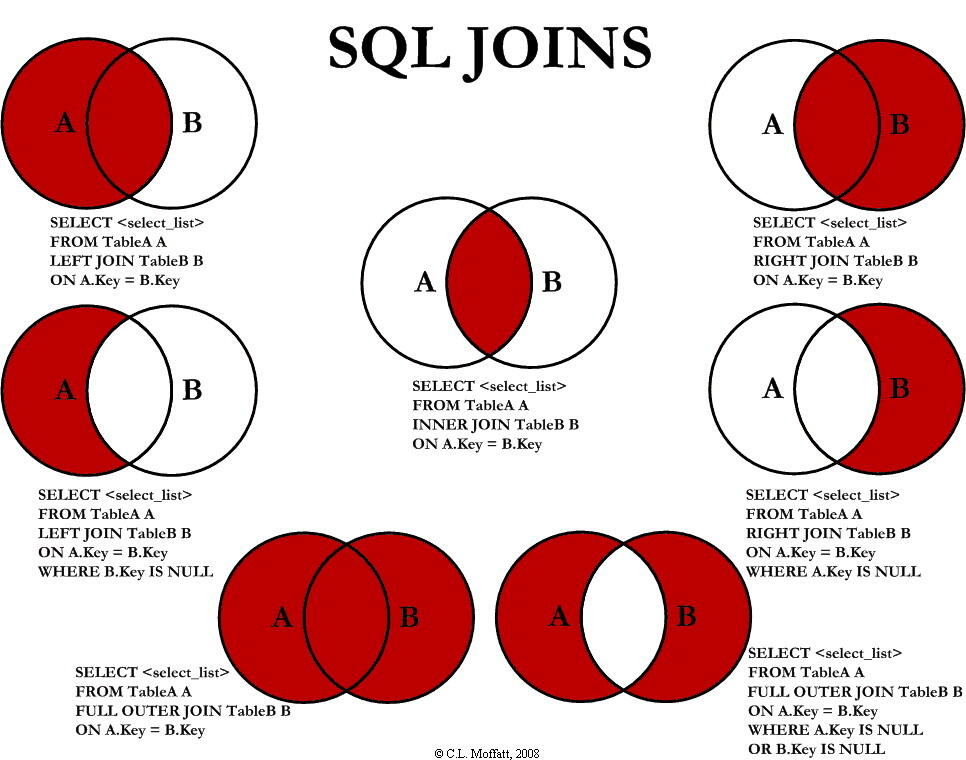
-
SQL 通配符
在 SQL 中,通配符与 SQL LIKE 操作符一起使用。
SQL 通配符用于搜索表中的数据。
| 通配符 |
描述 |
| % |
替代 0 个或多个字符 |
| _ |
替代一个字符 |
| [charlist] |
字符列中的任何单一字符 |
| [^charlist] |
不在字符列中的任何单一字符 |
-
SQL 约束(Constraints)
SQL 约束用于规定表中的数据规则。
如果存在违反约束的数据行为,行为会被约束终止。
约束可以在创建表时规定(通过 CREATE TABLE 语句),或者在表创建之后规定(通过 ALTER TABLE 语句)。
SQL CREATE TABLE + CONSTRAINT 语法
CREATE TABLE table_name
(
column_name1 data_type(size) constraint_name,
column_name2 data_type(size) constraint_name,
column_name3 data_type(size) constraint_name,
....
);在 SQL 中,我们有如下约束:
- NOT NULL - 指示某列不能存储 NULL 值。
CREATE TABLE Persons
(
P_Id int NOT NULL,
LastName varchar(255) NOT NULL,
FirstName varchar(255),
Address varchar(255),
City varchar(255)
)- UNIQUE - 保证某列的每行必须有唯一的值。
CREATE TABLE Persons
(
P_Id int NOT NULL,
LastName varchar(255) NOT NULL,
FirstName varchar(255),
Address varchar(255),
City varchar(255),
UNIQUE (P_Id),
CONSTRAINT uc_PersonID UNIQUE (LastName, FirstName) --命名UNIQUE约束,并定义多个列的UNIQUE 约束
)如果是已存在的表:
ALTER TABLE Persons
ADD UNIQUE (P_Id)
--或者:
ALTER TABLE Persons
ADD CONSTRAINT uc_PersonID UNIQUE (P_Id,LastName)撤销UNIQUE约束:
ALTER TABLE Persons
DROP INDEX uc_PersonID- PRIMARY KEY - NOT NULL 和 UNIQUE 的结合。确保某列(或两个列多个列的结合)有唯一标识,有助于更容易更快速地找到表中的一个特定的记录。
CREATE TABLE Persons
(
P_Id int NOT NULL,
LastName varchar(255) NOT NULL,
FirstName varchar(255),
Address varchar(255),
City varchar(255),
PRIMARY KEY (P_Id),
CONSTRAINT pk_PersonID PRIMARY KEY (LastName, FirstName) --命名 PRIMARY KEY 约束,并定义多个列的 PRIMARY KEY 约束
)如果是已存在的表:
ALTER TABLE Persons
ADD PRIMARY KEY (P_Id)
--或者:
ALTER TABLE Persons
ADD CONSTRAINT pk_PersonID PRIMARY KEY (P_Id,LastName)撤销PRIMARY KEY约束:
ALTER TABLE Persons
DROP PRIMARY KEY- FOREIGN KEY – 外键。保证一个表中的数据匹配另一个表中的值的参照完整性。
CREATE TABLE Orders
(
O_Id int NOT NULL,
OrderNo int NOT NULL,
P_Id int,
PRIMARY KEY (O_Id),
FOREIGN KEY (P_Id) REFERENCES Persons(表) (P_Id),
CONSTRAINT fk_PerOrders FOREIGN KEY (P_Id) --命名 FOREIGN KEY 约束,并定义多个列的 FOREIGN KEY 约束
REFERENCES Persons(表)(P_Id)
)如果是已存在的表:
ALTER TABLE Orders
ADD FOREIGN KEY (P_Id)
REFERENCES Persons(P_Id)
--或者:
ALTER TABLE Orders
ADD CONSTRAINT fk_PerOrders
FOREIGN KEY (P_Id)
REFERENCES Persons(P_Id)撤销FOREIGN KEY约束:
ALTER TABLE Orders
DROP FOREIGN KEY fk_PerOrders- CHECK - 保证列中的值符合指定的条件。
如果对单个列定义 CHECK 约束,那么该列只允许特定的值。
如果对一个表定义 CHECK 约束,那么此约束会基于行中其他列的值在特定的列中对值进行限制。
CREATE TABLE Persons
(
P_Id int NOT NULL,
Hight int NOT NULL,
LastName varchar(255) NOT NULL,
FirstName varchar(255),
Address varchar(255),
City varchar(255),
CHECK (P_Id>0),
CONSTRAINT chk_Person CHECK (Hight >0 AND City='Sandnes') --命名 CHECK 约束,并定义多个列的 CHECK 约束
)如果是已存在的表:
ALTER TABLE Persons
ADD CHECK (P_Id>0)
或者:
ALTER TABLE Persons
ADD CONSTRAINT chk_Person CHECK (P_Id>0 AND City='Sandnes')撤销CHECK约束:
ALTER TABLE Persons
DROP CHECK chk_Person- DEFAULT - 规定没有给列赋值时的默认值。
CREATE TABLE Persons
(
P_Id int NOT NULL,
LastName varchar(255) NOT NULL,
FirstName varchar(255),
Address varchar(255),
City varchar(255) DEFAULT 'Sandnes',
OrderDate date DEFAULT GETDATE()
)如果表已经被创建:
ALTER TABLE Persons
ALTER City SET DEFAULT 'SANDNES'撤销DEFAULT约束:
ALTER TABLE Persons
ALTER City DROP DEFAULT- AUTO INCREMENT - 新记录插入表中时生成一个唯一的数字
下面的 SQL 语句把 "Persons" 表中的 "ID" 列定义为 auto-increment 主键字段:
CREATE TABLE Persons
(
ID int NOT NULL AUTO_INCREMENT,
LastName varchar(255) NOT NULL,
FirstName varchar(255),
Address varchar(255),
City varchar(255),
PRIMARY KEY (ID)
)MySQL 使用 AUTO_INCREMENT 关键字来执行 auto-increment 任务。
默认地,AUTO_INCREMENT 的开始值是 1,每条新记录递增 1。
要让 AUTO_INCREMENT 序列以其他的值起始,请使用下面的 SQL 语法:
ALTER TABLE Persons AUTO_INCREMENT=100
-
视图
百度百科定义了什么是视图,但是对缺乏相关知识的人可能还是难以理解或者只有一个比较抽象的概念,笔者举个例子来解释下什么是视图。
朕想要了解皇宫的国库的相关情况,想知道酒窖有什么酒,剩多少,窖藏多少年,于是派最信任的高公公去清点,高公公去国库清点后报给了朕;朕又想知道藏书情况,于是又派高公公去清点并回来报告给朕,又想知道金银珠宝如何,又派高公公清点。。。过一段时间又想知道藏书情况,高公公还得重新再去清点,皇上问一次,高公公就得跑一次路。
后来皇上觉得高公公不容易,就成立了国库管理部门,小邓子负责酒窖,小卓子负责藏书,而小六子负责金库的清点。。。后来皇上每次想了解国库就直接问话负责人,负责人就按照职责要求进行汇报。

安排专人管理后,每次皇上想要了解国库情况,就不必让高公公每次都跑一趟,而是指定的人员按照指定的任务完成指定的汇报工作就可以了。
和数据库相对应,每次进行查询工作,都需要编写查询代码进行查询;而视图的作用就是不必每次都重新编写查询的SQL代码,而是通过视图直接查询即可。因此:
注意:视图是虚拟表,本身不存储数据,而是按照指定的方式进行查询。
视图参考链接原文:https://blog.csdn.net/moxigandashu/article/details/63254901
创建视图:
CREATE VIEW view_name AS
SELECT column_name(s)
FROM table_name
WHERE condition注释:视图总是显示最新的数据!每当用户查询视图时,数据库引擎通过使用视图的 SQL 语句重建数据。
更新视图(更新视图是指更新视图所依赖的SQL语句):
CREATE OR REPLACE VIEW view_name AS
SELECT column_name(s)
FROM table_name
WHERE condition查询就类似查表,但是实际的意义与效率就不一样了。